
本文的目的是解释Conditional Tabular GANs的工作原理,因为目前我还没有看到类似这样的文章。表格数据生成是一个不断发展的研究领域。CTGANs 论文已成为许多其他机器学习架构的基础,这些架构如今构成了该研究领域的最新技术。
为什么要生成表格数据?
我们都知道如何使用生成对抗网络 (GAN) 生成图像数据。我们现实中最常用的数据类型是表格数据。表格数据是结构化的,在训练机器学习模型时通常更容易处理。然而,虽然文本数据的生成方式和图形数据差不多,但是在生成表格数据时,要制作一个性能良好的模型,实际上会使事情复杂化很多。
本文的目标是了解 CTGAN 的工作原理。为此,我将首先对 GAN 和表格数据进行简要说明。然后我将介绍原始 CTGAN 论文中描述的架构。最后,我将通过一个使用 Python 的示例实现。
回顾 GAN
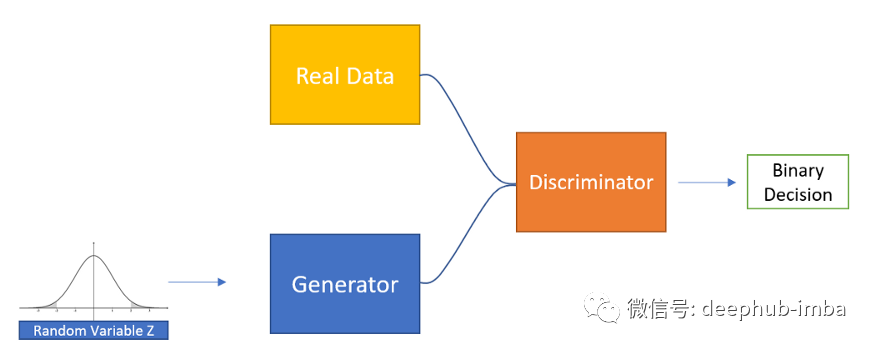
GAN 属于深度学习生成器的分支。这是一个监督学习问题,我们有一组真实数据,我们希望通过使用生成器来扩充这个数据集。GAN 学习生成样本与学习样本的分布有着根本的不同
GAN 由两个神经网络:生成器和鉴别器组成。生成器生成新数据,而鉴别器尝试正确区分真假数据。
这两个网络在训练中具有对抗性目标。鉴别器试图最大化其分类精度(正确识别来自生成器的图像),而生成器的目标是愚弄鉴别器。在学习结束时,生成器应该能够生成看起来很像真实数据集的图像,以至于它们可能会欺骗人类以为它们是真实的。
表格数据
正如我之前提到的,表格数据是结构化的。机器学习模型学习非结构化数据(如文本或图像)要困难得多。在大多数情况下,处理图像数据要复杂得多。但是,在生成表格数据时,您会发现算法很快就会变得非常复杂。
表格数据可以是数字类型的,也可以是分类类型的。
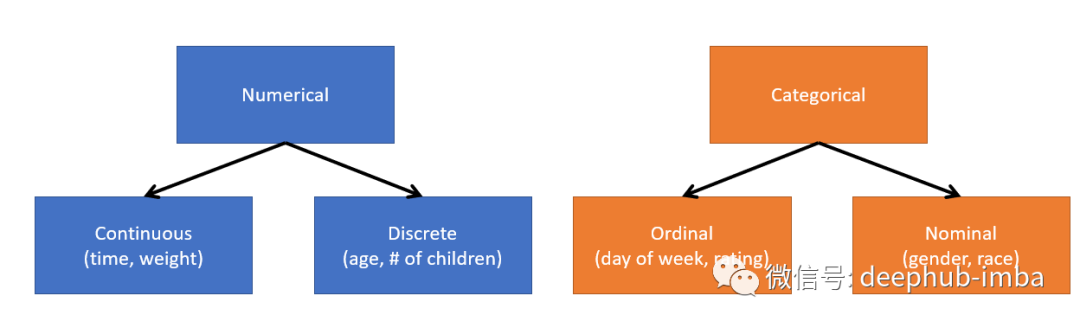
数值数据可以是连续的,也可以是离散的。连续数据的单位没有限制。例如重量可以用吨、公斤、克、毫克等来衡量。离散变量具有唯一的数值。例如我们家中孩子数量。至于分类数据,可能是有序数数据(有顺序的分类数据,例如星期几)或者是标称数据(没有顺序的分类数据)。
在一般情况下,离散数据、有序数据和标称数据都归为一组被称为离散数据。这是因为在训练神经网络时,我们不会把一周的天数作为向量{“星期一”,“星期二”…}。而是给它一个向量{0,1…}作为替代。这意味着我们可以把离散数据和分类数据视为一样的。
一个表格数据集T可以说包含Nd个离散列和Nc个连续列。表格数据生成的目标是训练生成器G学会从T生成合成数据集T(s)。
目前有两篇探讨表格数据生成的关键基础论文,分别是TGANs和CTGANs。在本文中,我将重点介绍CTGANs,这是一种已经在业界起飞的体系结构,在表格数据生成研究领域的发展中起到了关键作用。
CTGANs
为了完成表格数据生成的任务,我们可以训练一个普通的 GAN,但是CTGAN 提出了两种调整方法,试图解决 GAN 在应用于表格数据时的两个问题。
连续数据的归一化
CTGAN 试图解决的第一个问题是对连续数据进行归一化。
让我们首先看看如何表示离散数据。
离散数据很容易表示,因为它可以被One-hot编码。One-hot 编码只是将离散变量中的每个类别分类到其自身维度的过程。在前面的工作日示例中,我们没有使用包含工作日的向量,而是在One-hot编码之后,生成5列数据,其中一列代表一周中的一天,并以二进制表示类成员关系。
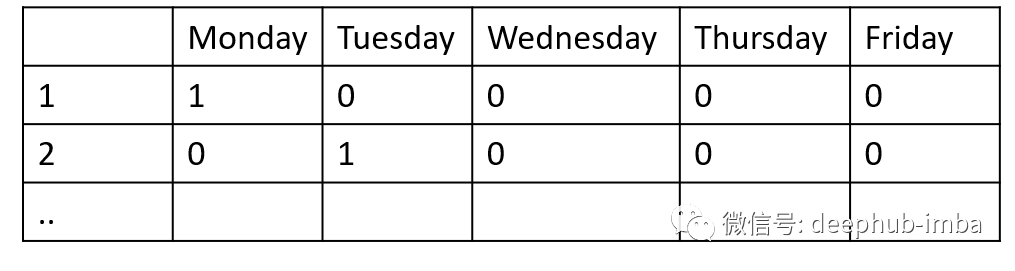
上面,第一个向量 {1,0,0,0,0} 表示星期一。第二个向量 {0,1,0,0,0} 代表星期二,依此类推。一种热编码为我们提供了一种标准化的方式来很好地表示离散变量。
但是,当涉及到连续数据时,很难表达连续变量所携带的所有信息。让我们看一个例子:
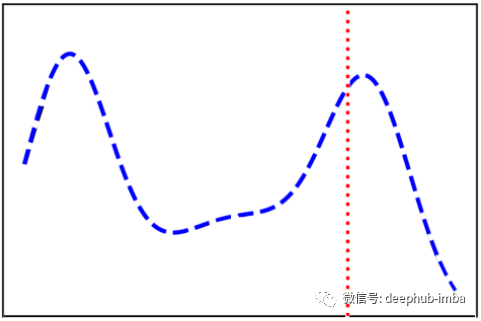
假设我们有一个像上面的连续变量(蓝色的分布),我们想要表示我们的样本(红色的)。如你所见,分布是相当复杂的,它有多种模式。因此,如果简单地给模型连续变量在样本中的值,我们可能会丢失一些信息,比如样本属于哪个模式,以及它在该模式中的重要性。
作者提出了一种他们称之为mode-specific normalization的解决方案,它将连续变量转换为包含我们上面描述的信息的向量。
mode-specific normalization首先将 VGM(variational Gaussian mixture model 变分高斯混合模型)拟合到每个连续变量。高斯混合模型只是试图通过期望最大化来找到最好的 k 个高斯模型来表示数据。VGM 可以通过权重阈值决定适合数据的最佳Gaussians (k) 数。
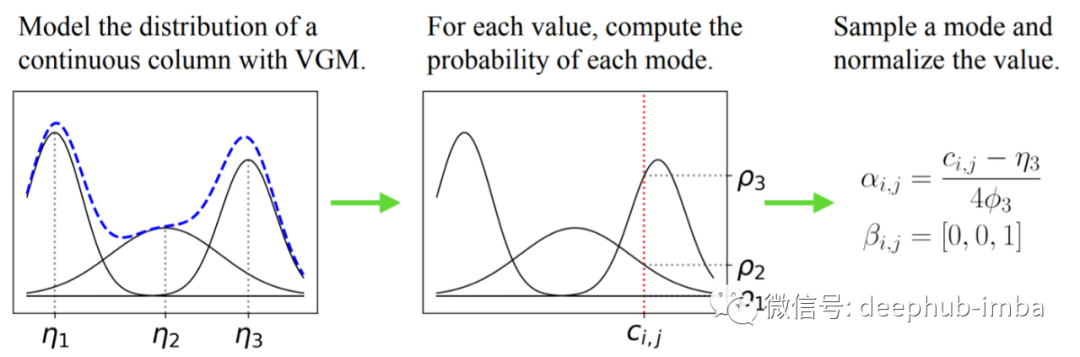
一旦我们找到了对连续变量进行最佳建模的 k 个高斯分布,我们就可以评估每个高斯分布的样本。我们可以确定样本属于哪个分布(用β表示)。最后,我们可以用α表示样本在其分布中的值(该样本在其高斯分布中的重要性)。
在论文的例子中,VGM 找到了 3 个高斯分布来表示连续变量 (k=3) 的分布。样本 c(红色)被编码为一个 β 向量 {0,0,1} 和一个使用上述等式的 α 向量。
就是这样,为了解决归一化问题,我们不需要给模型一个连续变量,而是给它 α 和 β。
离散数据的公平抽样
作者试图解决的关于 GAN 和表格数据的第二个问题与随机抽样和离散数据有关。
在训练 GAN 的生成器时,输入噪声来自先验分布(通常是多变量高斯分布)。用这种方法对离散变量进行抽样可能会丢失关于它们分布的信息。模型以某种方式将来自离散变量的信息作为输入并学习将输入相应地映射到期望的输出。论文提出的解决方案由三个关键要素组成:条件向量、生成器损失、采样训练。
1、强制生成器生成具有与训练数据相似的离散变量分布的样本,除了随机噪声之外,输入中必须包含有关所需离散变量的一些信息。所以他们选择包含一个条件向量。
这个条件向量允许我们强制生成器从选定的类别中生成样本。条件向量是包含所有离散列的One-hot编码,除了我们希望生成的样本满足的条件的离散列中的(一个)类别之外,所有值都是零。条件是通过抽样训练来选择的。
2、CTGANs 采样训练允许对条件进行采样以生成条件向量,使得生成器生成的分布与训练数据中离散变量的分布相匹配。通过抽样进行训练如下:
首先,选择一个随机离散列。然后,从该离散列中根据由该离散列中每个类别的出现频率构建的概率质量函数选择类别。最后,条件被转换为条件向量并用作生成器的输入。
3、生成器损失用于强制生成器在此条件下生成样本。他们通过将条件向量和生成的样本之间的交叉熵添加到损失项中来做到这一点。这迫使生产的样品遵守上面设置的条件。
应用案例
对于本例,我使用了泰坦尼克数据集。目标是生成看起来尽可能真实的数据。
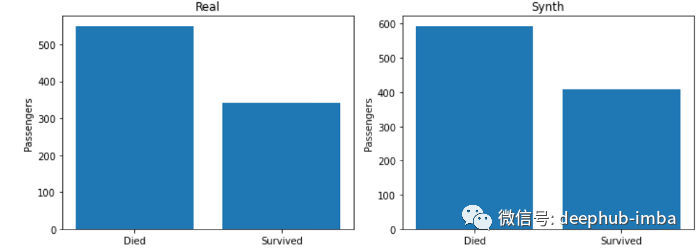
在上面的图像中,左边是数据集中泰坦尼克号上死亡和幸存乘客的真实分布。右边是生成的分布。如您所见,CTGAN学会生成与训练数据相似的分布。
CTGANs问题
虽然CTGANs可以了解训练数据的分布,但有时他们可能会错过这些数据和其他重要方面之间的相关性。
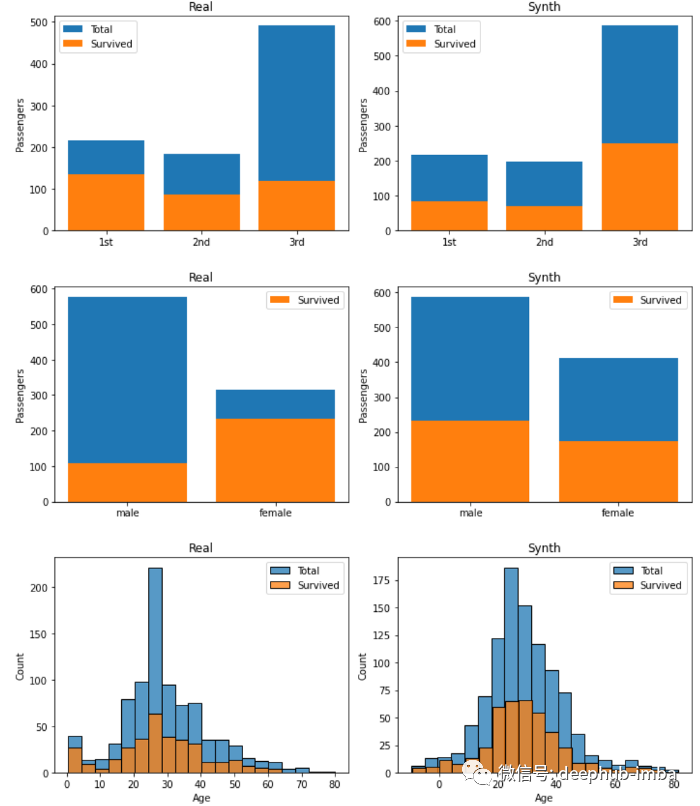
所有左边的图像对应真实数据的分布,右边的图像对应虚假数据的分布。可以看到,生成器错过了训练数据中的关键关系。例如,在真实的数据中可以看到如果是女性,更有可能在泰坦尼克号上幸存下来。该信息并没有被生成器捕获。生成器的另一个大问题是它生成的样本年龄是负的!
尽管有这么多理论,CTGANs本身绝对不是完美的。尽管他们很好地捕捉到了每个变量分布的一般形状,但他们未能捕捉到它们之间共享的大量信息。
总结
本文解释了一种生成表格数据的关键方法。CTGANs 可能很难理解,但为表格数据生成中的一些最大问题提供了一个非常漂亮的解决方案。
在本文的最后,我快速展示了应用于示例数据集的普通CTGANs算法的结果。CTGANs并不完美,但可以通过多种方式加以改进。还有很多源自CTGANs的其他体系结构,这些体系结构都通过自己的方法克服我们在本文中发现的一些缺陷。
引用
[1] Xu, L. and Veeramachaneni, K., 2018. Synthesizing Tabular Data using Generative Adversarial Networks. Cornell University.
[2] Dataset: Titanic - by Joaquin Vanschoren, Author: Frank E. Harrell Jr., Thomas Cason—https://www.openml.org/d/40945
作者:Diego Unzueta