
在学习《spark编程基础 python版》第5.7章 spark SQL时遇到的问题。
因为这本书全程都是在linux上搞,搞得我实在难受,然后我看黑马那一套可以配置远程解释器,所以我尝试使用Windows下Pycharm配置远程anaconda解释器(anaconda在linux上),然后使用pyspark连接MySQL。
1. 在linux上安装MySQL8
CentOS7安装MySQL8(亲测无坑百分百安装成功)-CSDN博客
这个好像真没坑
来先插点数据
$ mysql -u root -p
Enter password:
mysql> create database spark;
mysql> use spark;
mysql> create table student (id int(4), name char(20), gender char(4), age int(4));
mysql> insert into student values(1,'Xueqian','F',23);
mysql> insert into student values(2,'Weiliang','M',24);
mysql> select * from student;
2. 下载MySQL-Connector-Java
https://mvnrepository.com/artifact/mysql/mysql-connector-java
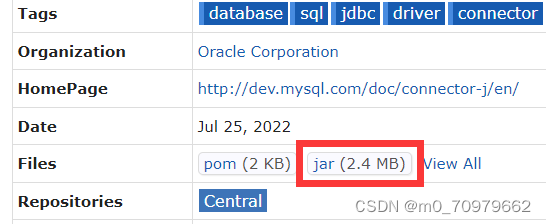
下载对应MySQL版本的jar包:先点进版本里,然后点红框里的jar就可以下载了
3. 在linux上安装anaconda,创建环境
这个教程多自己搜,而且似乎在linux上装anaconda,比在Windows上装还要简单。
(注:我的anaconda路径:/export/server/anaconda3 我的环境名称:pyspark)
4. 在Windows Pycharm中配置SSH远程解释器
点击右下角配置解释器
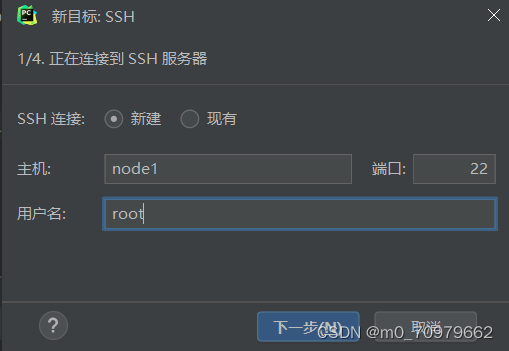
输入linux主机名(IP地址)或映射,和用户名
(注:我的映射:C:\Windows\System32\drivers\etc\hosts  ,记得用管理员权限打开哦)
,记得用管理员权限打开哦)
点击下一步输入密码
点击下一步等待内省
点击下一步配置基础解释器的位置:找到anaconda的位置,然后找到你要配置的环境的位置,找到bin/python
我的路径是:/export/server/anaconda3/envs/pyspark/bin/python
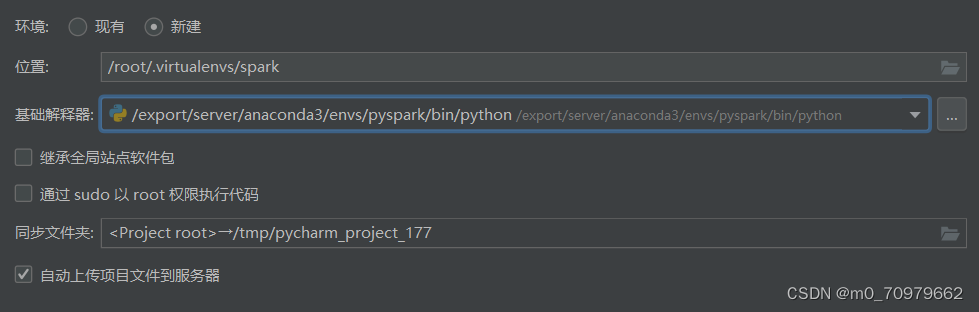
点击创建,完成SSH远程解释器的配置
5. 把jar包放到对应位置
把jar包放到这个文件夹里:/export/server/anaconda3/envs/pyspark/lib/python3.8/site-packages/pyspark/jars,根据你自己的路径调整
对没错就这一步 =_=
6. 运行代码
(注:node1是MySQL所在的节点,spark是数据库名称,表名为student)
代码1:查询
from pyspark import SparkConf
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
jdbc = spark.read.format("jdbc") \
.option("driver", "com.mysql.cj.jdbc.Driver") \
.option("url", "jdbc:mysql://node1:3306/spark") \
.option("dbtable", "student") \
.option("user", "root") \
.option("password", "123456") \
.load()
jdbc.foreach(print)
查询结果:

代码2:插入
from pyspark import SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import *
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
#设置模式信息
schema = StructType([StructField("id", IntegerType(), True),
StructField("name", StringType(), True),
StructField("gender", StringType(), True),
StructField("age", IntegerType(), True)])
# 设置两条数据,表示两个学生的信息
studentRDD = spark \
.sparkContext \
.parallelize(["3 Rongcheng M 26", "4 Guanhua M 27"]) \
.map(lambda x: x.split(" "))
# 创建 Row 对象,每个 Row 对象都是 rowRDD 中的一行
rowRDD = studentRDD.map(lambda p: Row(int(p[0].strip()), p[1].strip(), p[2].strip(), int(p[3].strip())))
# 建立 Row 对象和模式之间的对应关系,也就是把数据和模式对应起来
studentDF = spark.createDataFrame(rowRDD, schema)
# 写入数据库
prop = {'user': 'root', 'password': '123456', 'driver': "com.mysql.cj.jdbc.Driver"}
studentDF.write.jdbc("jdbc:mysql://node1:3306/spark", 'student', 'append', prop)
插入结果
mysql> select * from student;
+------+-----------+--------+------+
| id | name | gender | age |
+------+-----------+--------+------+
| 1 | Xueqian | F | 23 |
| 2 | Weiliang | M | 24 |
| 3 | Rongcheng | M | 26 |
| 4 | Guanhua | M | 27 |
+------+-----------+--------+------+
4 rows in set (0.00 sec)
OK结束,学不动了
版权归原作者 xcRt 所有, 如有侵权,请联系我们删除。