
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
本文使用深度强化技术来优化网站上的广告位,以最大限度地提高用户点击的概率并增加数字营销收入。在介绍概念的同时提供了带有代码的详细案例,可以作为在任何真实示例中实施解决方案。
流量联盟和按点击付费是数字营销的两个重要流程。这些技术的优化实施可以大大增加公司的产品/服务销售额,并为营销人员带来可观的收入。随着深度强化学习的进步,数字营销是可以极大受益的领域之一。
传统的数字营销活动调整方法需要大量的历史数据。这既耗费时间又耗费资源。使用强化学习,可以节省时间和资源,因为它们不需要任何历史数据或活动的先验信息。在本文中,我们可以看到简单的深度强化学习技术如何优化相当复杂的数字营销活动并获得近乎完美的结果。
在本文中,我们将通过接近真实的案例研究,了解强化学习如何帮助我们管理广告展示位置以获得最大收益。
问题和描述
我们有 10 个电子商务网站,每个网站都专注于销售不同类别的商品,如电脑、珠宝、巧克力等。我们的目标是通过将在我们网站上购物的客户推荐到他们可能感兴趣的另一个网站来增加产品的销售。当客户浏览我们的一个网站时,我们会显示另一个网站的广告,并希望他们在其他网站也购买产品。我们的问题是不知道应该向客户推荐哪个网站,或者我们没有客户偏好的任何信息。
让我们用强化学习来解决这个问题吧!!
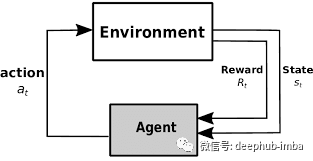
一般来说,强化学习是一种我们训练agent在环境中操作的技术。agent在状态s下采取行动a,并从环境中获得行动的奖励r。所以(s,a,r)成为状态-行动-奖励元组。我们训练的目标是使agent获得的总报酬最大化。因此我们发现(s,a,r)元组对于给定的状态和动作具有最大的奖励。为了找到优化的元组,我们运行了许多集,每次重新计算奖励。
在这个广告放置问题中,我们需要测试不同的行动,并自动学习在特定情况或状态或背景下的最有回报的结果。所以我们称之为“Contextual bandit framework”,在这个框架中,state变成了上下文信息,agent为当前上下文找到最佳行动。
假设我们有 10 个网站需要管理,这些网站构成了 10 个不同的状态。假定客户在其中一个网站上,我们有 10 种不同的产品类别,因此我们可以为客户展示这 10 种产品中的任何一种。所以我们在每个状态中有 10 个不同的动作。这将导致 100 个不同的状态-动作-奖励元组。我们需要存储 100 个不同的数据点,并在每次获得新奖励时重新计算。在这个例子中,这似乎是合理的。但是如果我们有 1000 个网站需要管理,这将导致 1000000 个数据点。存储和重新计算这将花费大量的时间和资源。
这意味着当状态和动作空间很大时强化学习是不可能实现的(状态和动作的总数很大)
这就是深度强化学习出现的原因。我们不是存储每个状态、动作和奖励元组,而是使用神经网络来抽象每个状态和动作的奖励值。神经网络很擅长学习摘要。它们可以学习数据中的模式和规则,并能将大量信息压缩到它们的记忆中作为权重。因此,神经网络可以学习状态-行为和奖励之间的复杂关系。
神经网络充当了从环境中学习以最大化回报的agent。在本文中,我们将使用PyTorch构建一个神经网络,并训练它优化广告位置,以获得最大的奖励。
代码实践
让我们首先为“Contextual bandit framework“创建一个模拟环境。这个环境应该包括10个状态,代表10个网站(0到9)产生广告点击后奖励方法,以及选择行动的方法(10个广告中的哪一个将被显示)。
class ContextBandit:
def __init__(self, arms=10):
self.arms = arms
self.init_distribution(arms)
self.update_state()
def init_distribution(self, arms): #1
self.bandit_matrix = np.random.rand(arms,arms)
def reward(self, prob):
reward = 0
for i in range(self.arms):
if random.random() < prob:
reward += 1
return reward
def get_state(self):
return self.state
def update_state(self):
self.state = np.random.randint(0,self.arms)
def get_reward(self,arm):
return self.reward(self.bandit_matrix[self.get_state()][arm])
def choose_arm(self, arm): #2
reward = self.get_reward(arm)
self.update_state()
return reward
1 它是一个表示每个状态的矩阵。行代表状态和代表动作
2 选择动作后返回奖励并更新状态
下面的代码显示了如何使用这个环境
env = ContextBandit(arms=10)
state = env.get_state()
reward = env.choose_arm(1)
print(state)
>>> 1
print(reward)
>>> 7
该环境由一个名为 ContextBandit 的类组成,该类可以通过动作(代码中的arm)的数量进行初始化。在这个例子中,我们采用的状态数等于动作数。但这在现实生活中可能会有所不同。该类有一个函数 get_state() ,当调用该函数时,它将从均匀分布返回一个随机状态。。在现实生活的例子中,状态可以来自更复杂或与业务相关的分布。使用任何动作 (arm) 作为输入调用 choose_arm() 将模拟放置广告。这个方法返回动作的奖励,并且用新状态更新当前状态。我们需要总是调用get_state(),然后再调用choose_arm()来不断获取新数据。
ContextualBandit 也有一些辅助函数,如 one-hot 编码和 softmax。one-hot 编码函数返回一个向量,其中one 为 1,all为 0,其中 1 表示当前状态。Softmax 函数用于设置各种动作在每个状态上的奖励分配。我们将有n种不同的softmax奖励分配给每个状态的行动。因此,我们需要学习状态与其动作分布之间的关系,并选择对给定状态具有最高概率的动作。下面提到了这两个函数的代码
def one_hot(N, pos, val=1): #N- number of actions , pos-state
one_hot_vec = np.zeros(N)
one_hot_vec[pos] = val
return one_hot_vec
def softmax(av, tau=1.12):
softm = np.exp(av / tau) / np.sum( np.exp(av / tau) )
return softm
现在让我们创建一个具有ReLU激活的两层前馈神经网络,它将作为Agent。第一层将接受10个元素的onehot编码向量(状态向量),最后一层将输出10个元素向量,表示每个动作的奖励。
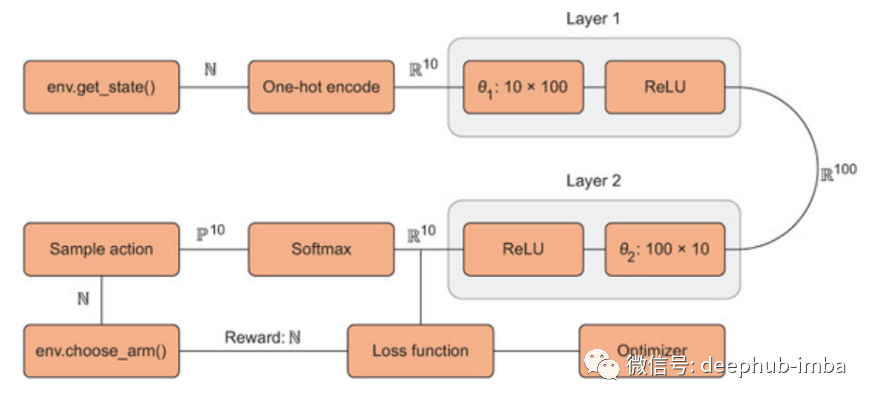
从图 2 中我们可以看到 get_state() 函数返回一个随机状态值,该值用过 one-hot 编码转换为 10 个元素向量。该向量作为神经网络的输入。神经网络的输出也是 10 个元素的向量,代表给定输入状态下每个动作的预测奖励。输出是一个密集向量,所以需要使用 softmax 函数进一步转换为概率。根据概率选择样本动作。一旦选择了动作,choose_arm() 就会获得奖励,并使用环境中的新状态进行更新。
最初,神经网络会为状态 0 生成一个类似于 [1.4, 50, 4.3, 0.31, 0.43, 11, 121, 90, 8.9, 1.1] 的输出向量。在运行 softmax 并对动作进行采样后,最有可能选择动作 6 (最高预测奖励)。在运行choose_arm() 后,选择动作6 将产生奖励8。我们训练神经网络用 [1.4, 50, 4.3, 0.31, 0.43, 11, 8, 90, 8.9, 1.1] 来更新向量,因为 8 是实际奖励。现在,下次神经网络将在看到状态 0 时为动作 6 预测接近 8 的奖励。我们会重复在许多状态和动作上不断训练我们的模型时,神经网络将学会为各种状态-动作对预测更准确的奖励
下面是创建神经网络并启动环境的代码
arms = 10
N, D_in, H, D_out = 1, arms, 100, arms
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out),
torch.nn.ReLU(),
)
loss_fn = torch.nn.MSELoss()
env = ContextBandit(arms)
现在让我们看看如何训练agent并按照图2中解释的所有步骤进行操作
def train(env, epochs=5000, learning_rate=1e-2):
cur_state = torch.Tensor(one_hot(arms,env.get_state())) #1
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
rewards = []
for i in range(epochs):
y_pred = model(cur_state) #2
av_softmax = softmax(y_pred.data.numpy(), tau=2.0) #3
av_softmax /= av_softmax.sum() #4
choice = np.random.choice(arms, p=av_softmax) #5
cur_reward = env.choose_arm(choice) #6
one_hot_reward = y_pred.data.numpy().copy() #7
one_hot_reward[choice] = cur_reward #8
reward = torch.Tensor(one_hot_reward)
rewards.append(cur_reward)
loss = loss_fn(y_pred, reward)
optimizer.zero_grad()
loss.backward()
optimizer.step()
cur_state = torch.Tensor(one_hot(arms,env.get_state())) #9
return np.array(rewards)
大概流程如下:
- 获取当前环境状态;转换为PyTorch变量
- 神经网络前向传播得到奖励预测
- 使用softmax将奖励预测转换为概率分布
- 对分布进行归一化,确保和为1
- 随机选择新动作
- 采取行动,获得奖励
- 将PyTorch张量数据转换为Numpy数组
- 更新one_hot_reward数组作为标记的训练数据
- 更新当前环境状态
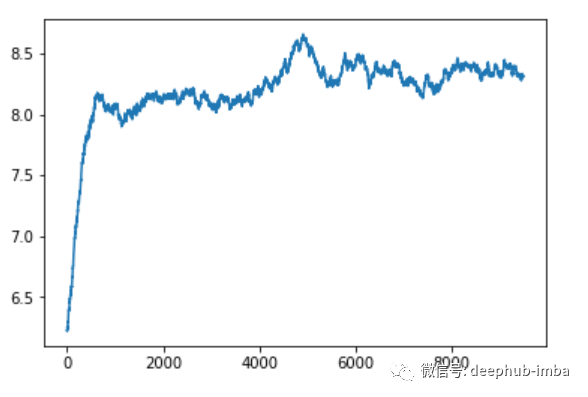
在训练网络5000个轮后,我们可以看到平均奖励的改善如下所示
总结
我们可以看到平均奖励都在8以上。效果还是可以的
整个项目代码可以在这个GIT链接中找到:https://github.com/NandaKishoreJoshi/Reinforcement_Lerning/blob/main/RL_course/1_Ad_placement.ipynb
本文基于Brandon Brown 和 Alexander Zai合著的《 Deep Reinforcement Leaning In Action》一书。这本书的链接在这里:https://learning.oreilly.com/library/view/deep-reinforcement-learning/9781617295430/kindle_split_011.html
作者:NandaKishore Joshi
喜欢就关注一下吧:
点个 在看 你最好看!********** **********