
第一章
1.大数据特点:4V
2.大数据计算模式
3.hadoop生态系统
4.spark提供了内存计算和基于DAG的任务调度机制,遵循一个软件栈满足不同应用场景的理念。
5.hadoop中MapReduce计算框架的缺点,对应的spark的优点
第二章
1.spark生态系统
2.spark的应用场景
3.RDD,DAG,Executor,应用,阶段的概念
4.spark架构设计
5.spark运行基本流程
6.RDD是一个分布式对象集合,本质上是一个只读的分区记录集合。提供了一种高度受限的共享内存模型,不能直接修改。RDD提供一组丰富的操作分为行动和转换两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的依赖关系。
7.RDD采用惰性调用,真正的计算发生在行动操作,通过血缘关系连接起来的一系列RDD操作可以实现管道化Pipeline
8.RDD特性(*)
9.宽依赖与窄依赖的区别:是否包含shuffle操作
10.窄依赖:map,filter,union
11.宽依赖:groupByKey
12.spark中,对窄依赖合并过程被称为流水线优化
13.RDD阶段的划分(简答)
14.spark部署方式:Spark on Mesos(URL是Mesos://ip:port),Spark on YARN ,Standalone
第四章

第五章
1.Spark SQL架构
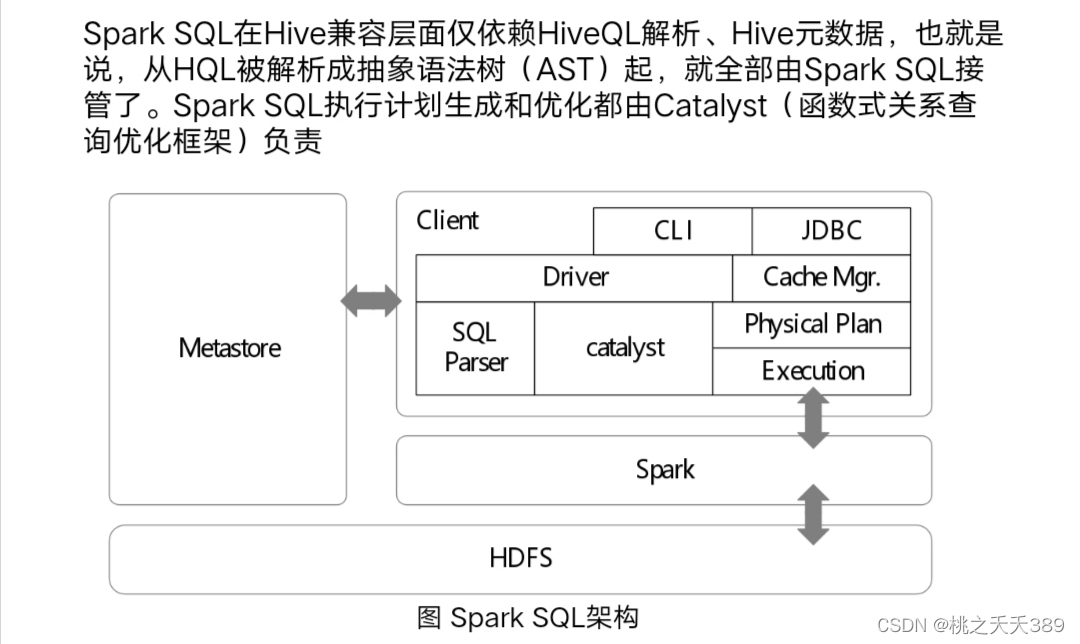
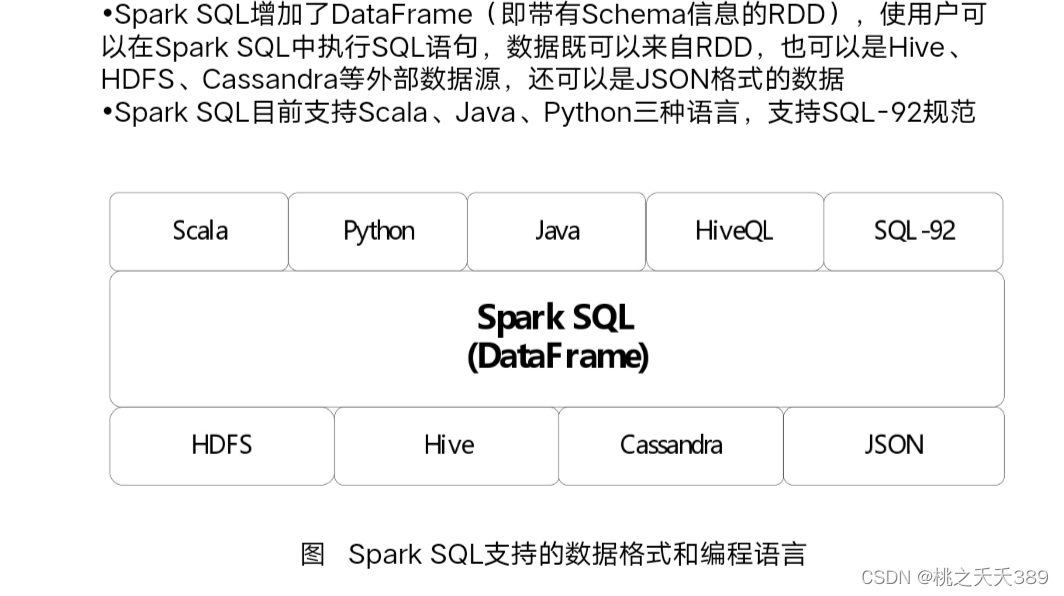

第六章
1.流计算和批量计算过一遍(有印象就行)
2.Spark Streaming的基本原理
3.Spark Streaming最主要的抽象是Dstream
4.Spark Streaming中有一个组件Receiver,作为长期运行的任务在一个Executor上执行,每个Receiver负责一个DStream输入流
5.编写Spark Streaming基本步骤
6.RDD编程中需要生成一个SparkContext对象,在Spark SQL编程中需要生成一个SparkSession对象,在Spark Streaming中需要生成一个StreamingContext对象
7.Socket工作原理(填空accept)
8.Kafka分布式发布订阅消息系统,相关概念:Broker,Topic,Producer,Consumer,Partition
9.DStream无状态转换操作和有状态转换操作区别

第七章
1.Structured Streaming关键思想
2.Structured Streaming的两种处理模型区别
3.Structured Streaming,Spark SQL,Spark Streaming区别

第八章
1.机器学习三个关键词:算法,经验,性能
2.模型是用数据对算法进行训练得到的
3.常用学习算法:分类,回归,聚类,协同过滤
4.流水线包括一些概念:DataFrame,转换器实现了transform()方法,评估器,流水线,参数
5.构建一个机器学习流水线,首先要定义流水线中各个PipelineStage,称为工作流阶段,包括转换器和评估器,之后就可以按照具体的处理逻辑,有序组织PipelineStage并创建一个流水线。构建好后,就可以把训练数据集作为输入参数,调用流水线实例的fit()方法,以流的方式来处理原训练数据。该调用返回一个PipelineModel类的实例,用来预测测试数据的标签。
6.TF-IDF的含义

版权归原作者 桃之夭夭389 所有, 如有侵权,请联系我们删除。