
一、源码下载
下面是hive官方源码下载地址,我下载的是hive-3.1.3,那就一起来看下吧
https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-src.tar.gz
二、上下文
<Hive-源码带你看hive命令背后都做了什么>博客中已经讲到了hive命令执行后会一直循环处理控制台输入的hql,下面就来继续分析下一条hql的执行过程,我们先看官网给的路径,然后再从源码开始捋。
三、官网说明
Design - Apache Hive - Apache Software Foundation
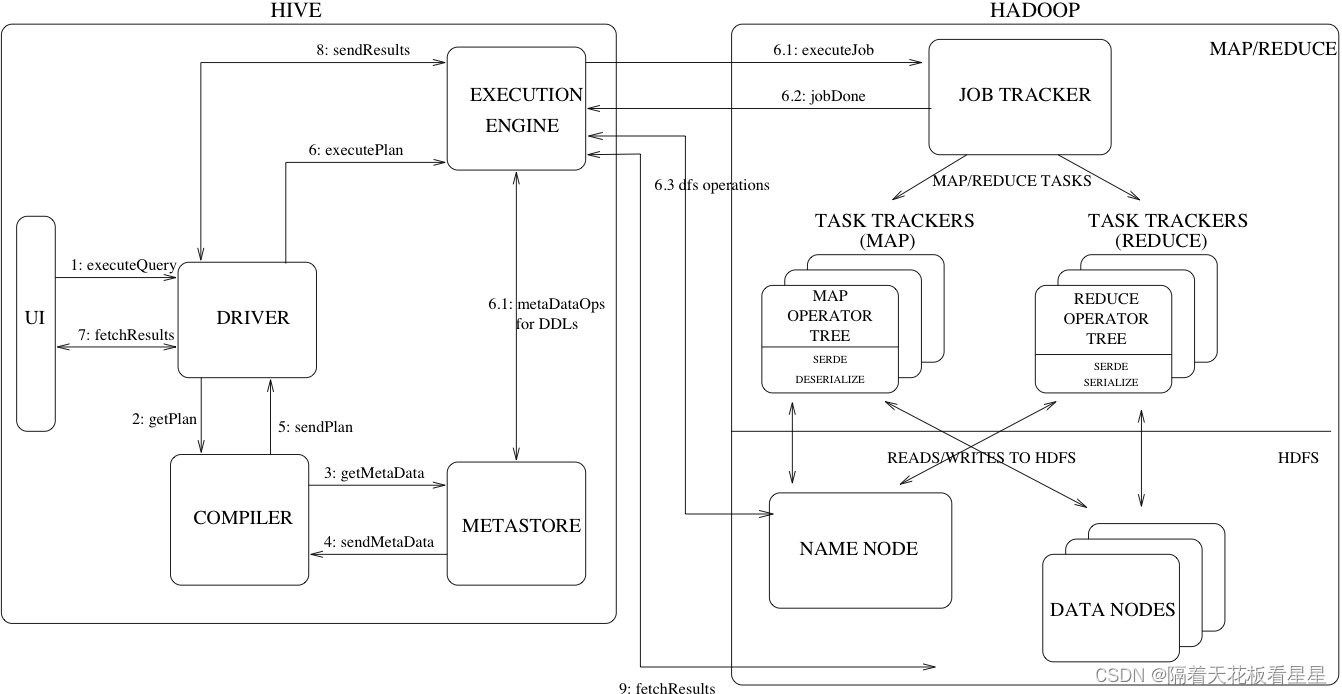
图中还展示了一个典型的查询是如何在系统中流动的,这里我们先看普通的查询
1、UI调用驱动程序的执行接口
2、驱动程序为查询创建会话句柄,并将查询发送给编译器以生成执行计划
3、4、编译器从元存储中获取必要的元数据
5、利用元数据对查询树中的表达式进行类型检查,并根据查询谓词修剪分区。编译器生成计划,计划是阶段的DAG,每个阶段要么是Map/Reduce作业,要么是元数据操作,要么是HDFS上的操作。对于Map/Reduce阶段,计划包含map运算符树(在MapTask上执行的运算符树)和reduce运算符树(用于需要ReduceTask的操作)。
6、6.1、6.2、6.3:执行引擎将这些阶段提交给适当的组件,
四、源码分析
<Hive-源码带你看hive命令背后都做了什么>博客中已经讲到了CliDriver.executeDriver(),我们从其中的processLine()开始捋
1、processLine
/**
* 处理一行分号分隔的命令 *
* @param line
* 要处理的命令 也就是一条hql
* @param allowInterrupting
* 当为true时,函数将通过中断处理并返回-1来处理SIG_INT(Ctrl+C)
*
* @return 如果一切正常 返回 0
*/
public int processLine(String line, boolean allowInterrupting) {
SignalHandler oldSignal = null;
Signal interruptSignal = null;
//如果是解析从控制台来的hql,allowInterrupting = true
if (allowInterrupting) {
//请记住在我们开始行处理时正在运行的所有线程。处理此行时挂起自定义Ctrl+C处理程序
//中断保留现场
interruptSignal = new Signal("INT");
oldSignal = Signal.handle(interruptSignal, new SignalHandler() {
private boolean interruptRequested;
@Override
public void handle(Signal signal) {
boolean initialRequest = !interruptRequested;
interruptRequested = true;
//在第二个ctrl+c上杀死VM
if (!initialRequest) {
console.printInfo("Exiting the JVM");
System.exit(127);
}
//中断CLI线程以停止当前语句并返回提示,还确实,下方给出了截图
console.printInfo("Interrupting... Be patient, this might take some time.");
console.printInfo("Press Ctrl+C again to kill JVM");
//首先,终止所有正在运行的MR作业
HadoopJobExecHelper.killRunningJobs();
TezJobExecHelper.killRunningJobs();
HiveInterruptUtils.interrupt();
}
});
}
try {
int lastRet = 0, ret = 0;
//我们不能直接使用“split”函数,因为可能会引用“;” 比如拼接字符串中有 “\\;”
//将hql按照字符一个一个处理,遇到 “;” 就会将前面的处理成一个hql 放入 commands
List<String> commands = splitSemiColon(line);
String command = "";
//循环执行用户一次输入的多条hql
for (String oneCmd : commands) {
if (StringUtils.endsWith(oneCmd, "\\")) {
command += StringUtils.chop(oneCmd) + ";";
continue;
} else {
command += oneCmd;
}
if (StringUtils.isBlank(command)) {
continue;
}
//接下来我们看processCmd方法中都做了什么
ret = processCmd(command);
command = "";
lastRet = ret;
boolean ignoreErrors = HiveConf.getBoolVar(conf, HiveConf.ConfVars.CLIIGNOREERRORS);
if (ret != 0 && !ignoreErrors) {
return ret;
}
}
return lastRet;
} finally {
// Once we are done processing the line, restore the old handler
if (oldSignal != null && interruptSignal != null) {
Signal.handle(interruptSignal, oldSignal);
}
}
}
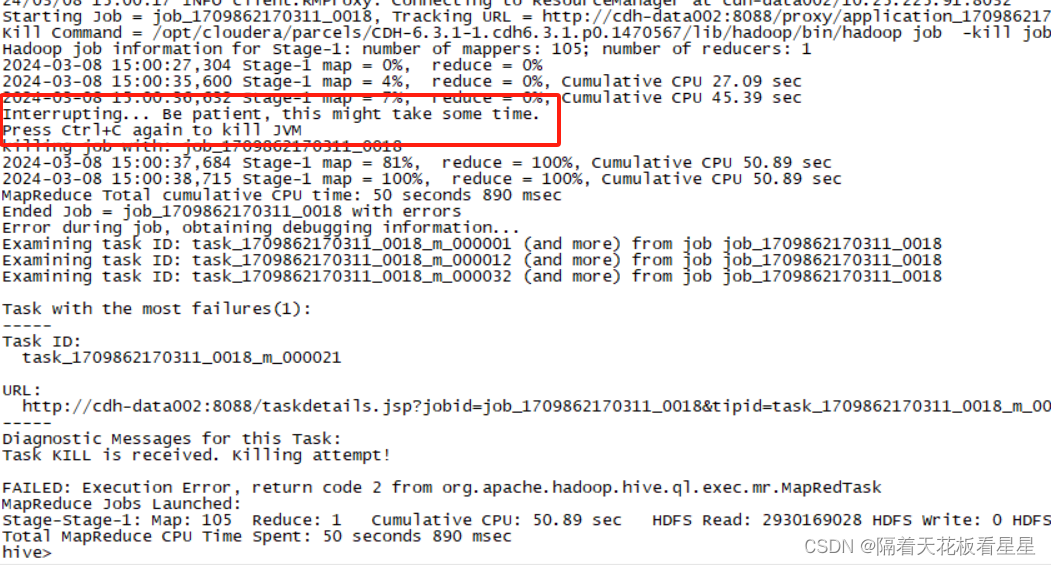
确实如源码中所写,当hql执行时如果按了ctrl+c 会有退出且给出这样的提示
2、processCmd
public int processCmd(String cmd) {
CliSessionState ss = (CliSessionState) SessionState.get();
ss.setLastCommand(cmd);
ss.updateThreadName();
//刷新打印流,使其不包括上一个命令的输出
ss.err.flush();
//从sql语句中剥离注释,跟踪语句何时包含字符串文字。并去掉头尾空白符(只有头尾哟)
String cmd_trimmed = HiveStringUtils.removeComments(cmd).trim();
//将去掉注释和首尾空白的hql按照 "\\s+" 分割成 tokens 字符串数组
// "\\s+" 等价于 [\f\r\t\v]
//比如现在 tokens 就是{“select” ,“*” , “from” ,“ods.test” , "where" "dt='20240309'"}
String[] tokens = tokenizeCmd(cmd_trimmed);
int ret = 0;
//如果用户输入的是 quit 或 exit 直接退出
if (cmd_trimmed.toLowerCase().equals("quit") || cmd_trimmed.toLowerCase().equals("exit")) {
//如果我们已经走到了这一步——要么前面的命令都成功了,
//要么这是命令行。无论哪种情况,这都算作成功运行
ss.close();
System.exit(0);
//如果 hql 第一个字符串是 source
} else if (tokens[0].equalsIgnoreCase("source")) {
//获取 source 后的hql字符串
String cmd_1 = getFirstCmd(cmd_trimmed, tokens[0].length());
cmd_1 = new VariableSubstitution(new HiveVariableSource() {
@Override
public Map<String, String> getHiveVariable() {
return SessionState.get().getHiveVariables();
}
}).substitute(ss.getConf(), cmd_1);
File sourceFile = new File(cmd_1);
if (! sourceFile.isFile()){
console.printError("File: "+ cmd_1 + " is not a file.");
ret = 1;
} else {
try {
ret = processFile(cmd_1);
} catch (IOException e) {
console.printError("Failed processing file "+ cmd_1 +" "+ e.getLocalizedMessage(),
stringifyException(e));
ret = 1;
}
}
} else if (cmd_trimmed.startsWith("!")) {
// 对于shell命令,请使用unstretch命令
//可以在hive客户端输入 ! sh your_script.sh 执行你的脚本
String shell_cmd = cmd.trim().substring(1);
shell_cmd = new VariableSubstitution(new HiveVariableSource() {
@Override
public Map<String, String> getHiveVariable() {
return SessionState.get().getHiveVariables();
}
}).substitute(ss.getConf(), shell_cmd);
// shell_cmd = "/bin/bash -c \'" + shell_cmd + "\'";
try {
ShellCmdExecutor executor = new ShellCmdExecutor(shell_cmd, ss.out, ss.err);
ret = executor.execute();
if (ret != 0) {
console.printError("Command failed with exit code = " + ret);
}
} catch (Exception e) {
console.printError("Exception raised from Shell command " + e.getLocalizedMessage(),
stringifyException(e));
ret = 1;
}
} else { //本地方式
try {
//获取执行hql的驱动程序,这个我们详细来看下
try (CommandProcessor proc = CommandProcessorFactory.get(tokens, (HiveConf) conf)) {
if (proc instanceof IDriver) {
//让驱动程序使用sql解析器剥离注释
ret = processLocalCmd(cmd, proc, ss);
} else {
//这里是直接使用剥离完注释的sql,我们看这里
ret = processLocalCmd(cmd_trimmed, proc, ss);
}
}
} catch (SQLException e) {
console.printError("Failed processing command " + tokens[0] + " " + e.getLocalizedMessage(),
org.apache.hadoop.util.StringUtils.stringifyException(e));
ret = 1;
}
catch (Exception e) {
throw new RuntimeException(e);
}
}
ss.resetThreadName();
return ret;
}
3、获取执行hql的驱动程序
顺着第2步看这个类CommandProcessorFactory
public static CommandProcessor get(String[] cmd, @Nonnull HiveConf conf) throws SQLException {
CommandProcessor result = getForHiveCommand(cmd, conf);
if (result != null) {
return result;
}
if (isBlank(cmd[0])) {
return null;
} else {
//如果不是llap开头的hql都会走这
//为客户端构建一个驱动程序
return DriverFactory.newDriver(conf);
}
}
public static CommandProcessor getForHiveCommand(String[] cmd, HiveConf conf)
throws SQLException {
return getForHiveCommandInternal(cmd, conf, false);
}
public static CommandProcessor getForHiveCommandInternal(String[] cmd, HiveConf conf,
boolean testOnly)
throws SQLException {
//这部分是关键,在HiveCommand中,我们看下
HiveCommand hiveCommand = HiveCommand.find(cmd, testOnly);
if (hiveCommand == null || isBlank(cmd[0])) {
return null;
}
if (conf == null) {
conf = new HiveConf();
}
Set<String> availableCommands = new HashSet<String>();
for (String availableCommand : conf.getVar(HiveConf.ConfVars.HIVE_SECURITY_COMMAND_WHITELIST)
.split(",")) {
availableCommands.add(availableCommand.toLowerCase().trim());
}
if (!availableCommands.contains(cmd[0].trim().toLowerCase())) {
throw new SQLException("Insufficient privileges to execute " + cmd[0], "42000");
}
if (cmd.length > 1 && "reload".equalsIgnoreCase(cmd[0])
&& "function".equalsIgnoreCase(cmd[1])) {
// special handling for SQL "reload function"
return null;
}
switch (hiveCommand) {
case SET:
return new SetProcessor();
case RESET:
return new ResetProcessor();
case DFS:
SessionState ss = SessionState.get();
return new DfsProcessor(ss.getConf());
case ADD:
return new AddResourceProcessor();
case LIST:
return new ListResourceProcessor();
case LLAP_CLUSTER:
return new LlapClusterResourceProcessor();
case LLAP_CACHE:
return new LlapCacheResourceProcessor();
case DELETE:
return new DeleteResourceProcessor();
case COMPILE:
return new CompileProcessor();
case RELOAD:
return new ReloadProcessor();
case CRYPTO:
try {
return new CryptoProcessor(SessionState.get().getHdfsEncryptionShim(), conf);
} catch (HiveException e) {
throw new SQLException("Fail to start the command processor due to the exception: ", e);
}
default:
throw new AssertionError("Unknown HiveCommand " + hiveCommand);
}
}
HiveCommand是非SQL语句,例如设置属性或添加资源。
//可以看出正常情况下只会返回 LLAP_CLUSTER 和 LLAP_CACHE
public static HiveCommand find(String[] command, boolean findOnlyForTesting) {
if (null == command){
return null;
}
//解析第一个hql字符串,比如 select 、 delete 、update 、set 等等
String cmd = command[0];
if (cmd != null) {
/转成大写 SELECT 、 DELETE 、UPDATE 、SET 等等
cmd = cmd.trim().toUpperCase();
if (command.length > 1 && "role".equalsIgnoreCase(command[1])) {
//对 "set role r1" 语句的特殊处理
return null;
} else if(command.length > 1 && "from".equalsIgnoreCase(command[1])) {
//对 "delete from <table> where..." 语句特殊处理
return null;
} else if(command.length > 1 && "set".equalsIgnoreCase(command[0]) && "autocommit".equalsIgnoreCase(command[1])) {
return null;//不希望set autocommit true|false与set hive.foo.bar混合......
} else if (command.length > 1 && "llap".equalsIgnoreCase(command[0])) {
return getLlapSubCommand(command);
} else if (COMMANDS.contains(cmd)) {
HiveCommand hiveCommand = HiveCommand.valueOf(cmd);
if (findOnlyForTesting == hiveCommand.isOnlyForTesting()) {
return hiveCommand;
}
return null;
}
}
return null;
}
private static HiveCommand getLlapSubCommand(final String[] command) {
if ("cluster".equalsIgnoreCase(command[1])) {
return LLAP_CLUSTER;
} else if ("cache".equalsIgnoreCase(command[1])) {
return LLAP_CACHE;
} else {
return null;
}
}
如果不是llap开头的hql都会走这 return DriverFactory.newDriver(conf);
public static IDriver newDriver(QueryState queryState, String userName, QueryInfo queryInfo) {
//获取配置中 hive.query.reexecution.enabled 的属性值 默认 true
//解释:启用查询重新执行
boolean enabled = queryState.getConf().getBoolVar(ConfVars.HIVE_QUERY_REEXECUTION_ENABLED);
if (!enabled) {
//如果没有开启则返回Driver
return new Driver(queryState, userName, queryInfo);
}
//获取配置中 hive.query.reexecution.strategies 的属性值 默认值为 overlay,reoptimize
//解释:可以使用逗号分隔的插件列表:
//overlay:hiveconf子树“reexec.overlay”用作执行出错时的覆盖
//reoptimize:在执行期间收集运算符统计信息,并在失败后重新编译查询
String strategies = queryState.getConf().getVar(ConfVars.HIVE_QUERY_REEXECUTION_STRATEGIES);
strategies = Strings.nullToEmpty(strategies).trim().toLowerCase();
ArrayList<IReExecutionPlugin> plugins = new ArrayList<>();
for (String string : strategies.split(",")) {
if (string.trim().isEmpty()) {
continue;
}
plugins.add(buildReExecPlugin(string));
}
//默认返回ReExecDriver
//覆盖IDriver接口,处理查询的重新执行;并向底层的重新执行插件提出了明确的问题。
return new ReExecDriver(queryState, userName, queryInfo, plugins);
}
4、processLocalCmd
int processLocalCmd(String cmd, CommandProcessor proc, CliSessionState ss) {
//获取hive-site.xml中的hive.cli.print.escape.crlf属性值,默认为false
//解释:是否将行输出中的回车和换行打印为转义符\r\n
boolean escapeCRLF = HiveConf.getBoolVar(conf, HiveConf.ConfVars.HIVE_CLI_PRINT_ESCAPE_CRLF);
int ret = 0;
if (proc != null) {
//从第3步已经知晓,默认会走这一步
if (proc instanceof IDriver) {
//强制先转成IDriver
IDriver qp = (IDriver) proc;
PrintStream out = ss.out;
long start = System.currentTimeMillis();
if (ss.getIsVerbose()) {
out.println(cmd);
}
//这里调用的时IDriver.run() 我们详细看下
ret = qp.run(cmd).getResponseCode();
if (ret != 0) {
qp.close();
return ret;
}
//查询已运行捕获时间
long end = System.currentTimeMillis();
double timeTaken = (end - start) / 1000.0;
ArrayList<String> res = new ArrayList<String>();
printHeader(qp, out);
//打印结果
int counter = 0;
try {
if (out instanceof FetchConverter) {
((FetchConverter) out).fetchStarted();
}
while (qp.getResults(res)) {
for (String r : res) {
if (escapeCRLF) {
r = EscapeCRLFHelper.escapeCRLF(r);
}
out.println(r);
}
counter += res.size();
res.clear();
if (out.checkError()) {
break;
}
}
} catch (IOException e) {
console.printError("Failed with exception " + e.getClass().getName() + ":" + e.getMessage(),
"\n" + org.apache.hadoop.util.StringUtils.stringifyException(e));
ret = 1;
}
qp.close();
if (out instanceof FetchConverter) {
((FetchConverter) out).fetchFinished();
}
console.printInfo(
"Time taken: " + timeTaken + " seconds" + (counter == 0 ? "" : ", Fetched: " + counter + " row(s)"));
} else {
String firstToken = tokenizeCmd(cmd.trim())[0];
String cmd_1 = getFirstCmd(cmd.trim(), firstToken.length());
if (ss.getIsVerbose()) {
ss.out.println(firstToken + " " + cmd_1);
}
CommandProcessorResponse res = proc.run(cmd_1);
if (res.getResponseCode() != 0) {
ss.out
.println("Query returned non-zero code: " + res.getResponseCode() + ", cause: " + res.getErrorMessage());
}
if (res.getConsoleMessages() != null) {
for (String consoleMsg : res.getConsoleMessages()) {
console.printInfo(consoleMsg);
}
}
ret = res.getResponseCode();
}
}
return ret;
}
5、ReExecDriver
public CommandProcessorResponse run(String command) {
CommandProcessorResponse r0 = compileAndRespond(command);
if (r0.getResponseCode() != 0) {
return r0;
}
return run();
}
public CommandProcessorResponse compileAndRespond(String statement) {
currentQuery = statement;
//coreDriver就是Driver 我们去Driver详细看下这个逻辑
return coreDriver.compileAndRespond(statement);
}
public CommandProcessorResponse run() {
executionIndex = 0;
int maxExecutuions = 1 + coreDriver.getConf().getIntVar(ConfVars.HIVE_QUERY_MAX_REEXECUTION_COUNT);
while (true) {
executionIndex++;
for (IReExecutionPlugin p : plugins) {
p.beforeExecute(executionIndex, explainReOptimization);
}
coreDriver.getContext().setExecutionIndex(executionIndex);
LOG.info("Execution #{} of query", executionIndex);
CommandProcessorResponse cpr = coreDriver.run();
PlanMapper oldPlanMapper = coreDriver.getPlanMapper();
afterExecute(oldPlanMapper, cpr.getResponseCode() == 0);
boolean shouldReExecute = explainReOptimization && executionIndex==1;
shouldReExecute |= cpr.getResponseCode() != 0 && shouldReExecute();
if (executionIndex >= maxExecutuions || !shouldReExecute) {
return cpr;
}
LOG.info("Preparing to re-execute query");
prepareToReExecute();
CommandProcessorResponse compile_resp = coreDriver.compileAndRespond(currentQuery);
if (compile_resp.failed()) {
LOG.error("Recompilation of the query failed; this is unexpected.");
// FIXME: somehow place pointers that re-execution compilation have failed; the query have been successfully compiled before?
return compile_resp;
}
PlanMapper newPlanMapper = coreDriver.getPlanMapper();
if (!explainReOptimization && !shouldReExecuteAfterCompile(oldPlanMapper, newPlanMapper)) {
LOG.info("re-running the query would probably not yield better results; returning with last error");
// FIXME: retain old error; or create a new one?
return cpr;
}
}
}
5.1、Driver
public CommandProcessorResponse compileAndRespond(String command, boolean cleanupTxnList) {
try {
compileInternal(command, false);
return createProcessorResponse(0);
} catch (CommandProcessorResponse e) {
return e;
} finally {
if (cleanupTxnList) {
//使用此命令编译的查询可能会生成有效的txn列表,因此我们需要重置它
conf.unset(ValidTxnList.VALID_TXNS_KEY);
}
}
}
private void compileInternal(String command, boolean deferClose) throws CommandProcessorResponse {
//......省略......
try {
//deferClose表示进程中断时是否应推迟关闭/销毁,
//如果在另一个方法(如runInternal)内调用编译,
//则应将其设置为true,runInternal将关闭推迟到该方法中调用的。
//我们详细看下
compile(command, true, deferClose);
} catch (CommandProcessorResponse cpr) {
//......省略......
} finally {
compileLock.unlock();
}
//......省略......
}
private void compile(String command, boolean resetTaskIds, boolean deferClose) throws CommandProcessorResponse {
//......省略......
command = new VariableSubstitution(new HiveVariableSource() {
@Override
public Map<String, String> getHiveVariable() {
return SessionState.get().getHiveVariables();
}
}).substitute(conf, command);
String queryStr = command;
try {
//应编辑命令以避免记录敏感数据
queryStr = HookUtils.redactLogString(conf, command);
} catch (Exception e) {
LOG.warn("WARNING! Query command could not be redacted." + e);
}
checkInterrupted("at beginning of compilation.", null, null);
if (ctx != null && ctx.getExplainAnalyze() != AnalyzeState.RUNNING) {
//在编译新查询之前关闭现有的ctx-etc,但不要破坏驱动程序
closeInProcess(false);
}
if (resetTaskIds) {
TaskFactory.resetId();
}
LockedDriverState.setLockedDriverState(lDrvState);
//获取查询id 正在执行的查询的ID(每个会话可能有多个
String queryId = queryState.getQueryId();
if (ctx != null) {
setTriggerContext(queryId);
}
//保存一些信息以供webUI在计划释放后使用
this.queryDisplay.setQueryStr(queryStr);
this.queryDisplay.setQueryId(queryId);
//正在编译这条 hql
LOG.info("Compiling command(queryId=" + queryId + "): " + queryStr);
conf.setQueryString(queryStr);
//FIXME:副作用将把最后一个查询集留在会话级别
if (SessionState.get() != null) {
SessionState.get().getConf().setQueryString(queryStr);
SessionState.get().setupQueryCurrentTimestamp();
}
//查询编译过程中是否发生任何错误。用于查询生存期挂钩。
boolean compileError = false;
boolean parseError = false;
try {
//初始化事务管理器。这必须在调用解析(analyze)之前完成。
if (initTxnMgr != null) {
queryTxnMgr = initTxnMgr;
} else {
queryTxnMgr = SessionState.get().initTxnMgr(conf);
}
if (queryTxnMgr instanceof Configurable) {
((Configurable) queryTxnMgr).setConf(conf);
}
queryState.setTxnManager(queryTxnMgr);
//如果用户Ctrl-C两次杀死Hive CLI JVM,如果多次调用compile,
//我们希望释放锁,请清除旧的shutdownhook
ShutdownHookManager.removeShutdownHook(shutdownRunner);
final HiveTxnManager txnMgr = queryTxnMgr;
shutdownRunner = new Runnable() {
@Override
public void run() {
try {
releaseLocksAndCommitOrRollback(false, txnMgr);
} catch (LockException e) {
LOG.warn("Exception when releasing locks in ShutdownHook for Driver: " +
e.getMessage());
}
}
};
ShutdownHookManager.addShutdownHook(shutdownRunner, SHUTDOWN_HOOK_PRIORITY);
//在解析和分析查询之前
checkInterrupted("before parsing and analysing the query", null, null);
if (ctx == null) {
ctx = new Context(conf);
setTriggerContext(queryId);
}
//设置此查询的事务管理器
ctx.setHiveTxnManager(queryTxnMgr);
ctx.setStatsSource(statsSource);
//设置hql
ctx.setCmd(command);
//退出时清理HDFS
ctx.setHDFSCleanup(true);
perfLogger.PerfLogBegin(CLASS_NAME, PerfLogger.PARSE);
//在查询进入解析阶段之前调用
hookRunner.runBeforeParseHook(command);
ASTNode tree;
try {
//解析hql 这里先不展开讲,我们会单独拿一篇博客来研究
tree = ParseUtils.parse(command, ctx);
} catch (ParseException e) {
parseError = true;
throw e;
} finally {
hookRunner.runAfterParseHook(command, parseError);
}
perfLogger.PerfLogEnd(CLASS_NAME, PerfLogger.PARSE);
hookRunner.runBeforeCompileHook(command);
//清除CurrentFunctionsInUse 设置,以捕获SemanticAnalyzer发现正在使用的新函数集
SessionState.get().getCurrentFunctionsInUse().clear();
perfLogger.PerfLogBegin(CLASS_NAME, PerfLogger.ANALYZE);
//刷新元存储缓存。这确保了我们不会从在同一线程中运行的先前查询中拾取对象。
//这必须在我们获得语义分析器之后(即与元存储建立连接时),
//但在我们进行分析之前完成,因为此时我们需要访问对象。
Hive.get().getMSC().flushCache();
backupContext = new Context(ctx);
boolean executeHooks = hookRunner.hasPreAnalyzeHooks();
//Hive为HiveSemanticAnalyzerHook的实现提供的上下文信息
HiveSemanticAnalyzerHookContext hookCtx = new HiveSemanticAnalyzerHookContextImpl();
if (executeHooks) {
hookCtx.setConf(conf);
hookCtx.setUserName(userName);
hookCtx.setIpAddress(SessionState.get().getUserIpAddress());
hookCtx.setCommand(command);
hookCtx.setHiveOperation(queryState.getHiveOperation());
//在Hive对语句执行自己的语义分析之前调用。实现可以检查语句AST,
//并通过抛出SemanticException来阻止其执行。它是可选地,
//它也可以扩充/重写AST,但必须生成一个与Hive自己的解析器直接返回的表单等效的表单。
//返回替换后的AST(通常与原始AST相同,除非必须替换整个树;不得为null)
tree = hookRunner.runPreAnalyzeHooks(hookCtx, tree);
}
//进行语义分析和计划生成
//这里会根据 tree的type获取不同的优化引擎,默认是CalcitePlanner
BaseSemanticAnalyzer sem = SemanticAnalyzerFactory.get(queryState, tree);
if (!retrial) {
openTransaction();
generateValidTxnList();
}
//对hql转化后的tree进行解析,比如:语义分析 ,后面专门用一篇博客来研究
sem.analyze(tree, ctx);
if (executeHooks) {
hookCtx.update(sem);
hookRunner.runPostAnalyzeHooks(hookCtx, sem.getAllRootTasks());
}
/语义分析完成
LOG.info("Semantic Analysis Completed (retrial = {})", retrial);
//检索有关查询的缓存使用情况的信息。
if (conf.getBoolVar(HiveConf.ConfVars.HIVE_QUERY_RESULTS_CACHE_ENABLED)) {
cacheUsage = sem.getCacheUsage();
}
//验证计划
sem.validate();
perfLogger.PerfLogEnd(CLASS_NAME, PerfLogger.ANALYZE);
//分析查询后
checkInterrupted("after analyzing query.", null, null);
//获取输出模式
schema = getSchema(sem, conf);
//制作查询计划
plan = new QueryPlan(queryStr, sem, perfLogger.getStartTime(PerfLogger.DRIVER_RUN), queryId,
queryState.getHiveOperation(), schema);
//设置mapreduce工作流引擎id和name
conf.set("mapreduce.workflow.id", "hive_" + queryId);
conf.set("mapreduce.workflow.name", queryStr);
//在此处初始化FetchTask
if (plan.getFetchTask() != null) {
plan.getFetchTask().initialize(queryState, plan, null, ctx.getOpContext());
}
//进行授权检查
if (!sem.skipAuthorization() &&
HiveConf.getBoolVar(conf, HiveConf.ConfVars.HIVE_AUTHORIZATION_ENABLED)) {
try {
perfLogger.PerfLogBegin(CLASS_NAME, PerfLogger.DO_AUTHORIZATION);
//具体会做以下操作
// 1、连接hive的元数据
// 2、设置输入输出
// 3、获取表和列的映射
// 4、添加正在使用的永久UDF
// 5、解析hql操作是对数据库、表、还是查询或者导入
// 6、如果是分区表,还要检查分区权限
// 7、通过表扫描运算符检查列授权
// 8、表授权检查
doAuthorization(queryState.getHiveOperation(), sem, command);
} catch (AuthorizationException authExp) {
console.printError("Authorization failed:" + authExp.getMessage()
+ ". Use SHOW GRANT to get more details.");
errorMessage = authExp.getMessage();
SQLState = "42000";
throw createProcessorResponse(403);
} finally {
perfLogger.PerfLogEnd(CLASS_NAME, PerfLogger.DO_AUTHORIZATION);
}
}
if (conf.getBoolVar(ConfVars.HIVE_LOG_EXPLAIN_OUTPUT)) {
String explainOutput = getExplainOutput(sem, plan, tree);
if (explainOutput != null) {
LOG.info("EXPLAIN output for queryid " + queryId + " : "
+ explainOutput);
if (conf.isWebUiQueryInfoCacheEnabled()) {
//设置执行计划
queryDisplay.setExplainPlan(explainOutput);
}
}
}
} catch (CommandProcessorResponse cpr) {
throw cpr;
} catch (Exception e) {
checkInterrupted("during query compilation: " + e.getMessage(), null, null);
compileError = true;
ErrorMsg error = ErrorMsg.getErrorMsg(e.getMessage());
errorMessage = "FAILED: " + e.getClass().getSimpleName();
if (error != ErrorMsg.GENERIC_ERROR) {
errorMessage += " [Error " + error.getErrorCode() + "]:";
}
// HIVE-4889
if ((e instanceof IllegalArgumentException) && e.getMessage() == null && e.getCause() != null) {
errorMessage += " " + e.getCause().getMessage();
} else {
errorMessage += " " + e.getMessage();
}
if (error == ErrorMsg.TXNMGR_NOT_ACID) {
errorMessage += ". Failed command: " + queryStr;
}
SQLState = error.getSQLState();
downstreamError = e;
console.printError(errorMessage, "\n"
+ org.apache.hadoop.util.StringUtils.stringifyException(e));
throw createProcessorResponse(error.getErrorCode());
} finally {
// 触发编译后挂钩。请注意,如果此处编译失败,则执行前/执行后挂钩将永远不会执行。
if (!parseError) {
try {
hookRunner.runAfterCompilationHook(command, compileError);
} catch (Exception e) {
LOG.warn("Failed when invoking query after-compilation hook.", e);
}
}
double duration = perfLogger.PerfLogEnd(CLASS_NAME, PerfLogger.COMPILE)/1000.00;
ImmutableMap<String, Long> compileHMSTimings = dumpMetaCallTimingWithoutEx("compilation");
queryDisplay.setHmsTimings(QueryDisplay.Phase.COMPILATION, compileHMSTimings);
boolean isInterrupted = lDrvState.isAborted();
if (isInterrupted && !deferClose) {
closeInProcess(true);
}
lDrvState.stateLock.lock();
try {
if (isInterrupted) {
lDrvState.driverState = deferClose ? DriverState.EXECUTING : DriverState.ERROR;
} else {
lDrvState.driverState = compileError ? DriverState.ERROR : DriverState.COMPILED;
}
} finally {
lDrvState.stateLock.unlock();
}
if (isInterrupted) {
LOG.info("Compiling command(queryId=" + queryId + ") has been interrupted after " + duration + " seconds");
} else {
LOG.info("Completed compiling command(queryId=" + queryId + "); Time taken: " + duration + " seconds");
}
}
}
5.2、ReExecDriver自身执行
public CommandProcessorResponse run() {
executionIndex = 0;
//获取配置文件中的 hive.query.reexecution.max.count 属性值,默认为 1
//解释:单个查询的最大重新执行次数
int maxExecutuions = 1 + coreDriver.getConf().getIntVar(ConfVars.HIVE_QUERY_MAX_REEXECUTION_COUNT);
while (true) {
executionIndex++;
//循环执行重新执行逻辑
for (IReExecutionPlugin p : plugins) {
//在执行查询之前调用
p.beforeExecute(executionIndex, explainReOptimization);
}
coreDriver.getContext().setExecutionIndex(executionIndex);
LOG.info("Execution #{} of query", executionIndex);
//还是会调用Driver ,但是和5.1调用的不一样,我们详细看看
CommandProcessorResponse cpr = coreDriver.run();
PlanMapper oldPlanMapper = coreDriver.getPlanMapper();
afterExecute(oldPlanMapper, cpr.getResponseCode() == 0);
boolean shouldReExecute = explainReOptimization && executionIndex==1;
shouldReExecute |= cpr.getResponseCode() != 0 && shouldReExecute();
if (executionIndex >= maxExecutuions || !shouldReExecute) {
return cpr;
}
//正在准备重新执行查询
LOG.info("Preparing to re-execute query");
prepareToReExecute();
CommandProcessorResponse compile_resp = coreDriver.compileAndRespond(currentQuery);
if (compile_resp.failed()) {
LOG.error("Recompilation of the query failed; this is unexpected.");
return compile_resp;
}
PlanMapper newPlanMapper = coreDriver.getPlanMapper();
if (!explainReOptimization && !shouldReExecuteAfterCompile(oldPlanMapper, newPlanMapper)) {
//重新运行查询可能不会产生更好的结果;返回最后一个错误
LOG.info("re-running the query would probably not yield better results; returning with last error");
return cpr;
}
}
}
分析调用Driver的逻辑(和5.1不同)
public CommandProcessorResponse run(String command, boolean alreadyCompiled) {
try {
runInternal(command, alreadyCompiled);
return createProcessorResponse(0);
} catch (CommandProcessorResponse cpr) {
//......省略......
}
}
private void runInternal(String command, boolean alreadyCompiled) throws CommandProcessorResponse {
errorMessage = null;
SQLState = null;
downstreamError = null;
LockedDriverState.setLockedDriverState(lDrvState);
lDrvState.stateLock.lock();
try {
if (alreadyCompiled) {
if (lDrvState.driverState == DriverState.COMPILED) {
//如果引擎是编译状态,现在修改成执行状态
lDrvState.driverState = DriverState.EXECUTING;
} else {
//失败:预编译的查询已被取消或关闭。
errorMessage = "FAILED: Precompiled query has been cancelled or closed.";
console.printError(errorMessage);
throw createProcessorResponse(12);
}
} else {
lDrvState.driverState = DriverState.COMPILING;
}
} finally {
lDrvState.stateLock.unlock();
}
//一个标志,通过跟踪方法是否因错误而返回,帮助在finally块中设置正确的驱动器状态。
boolean isFinishedWithError = true;
try {
//Hive向HiveDriverRunHook的实现提供的上下文信息
HiveDriverRunHookContext hookContext = new HiveDriverRunHookContextImpl(conf,
alreadyCompiled ? ctx.getCmd() : command);
//获取所有驱动程序运行挂钩并预执行它们
try {
hookRunner.runPreDriverHooks(hookContext);
} catch (Exception e) {
errorMessage = "FAILED: Hive Internal Error: " + Utilities.getNameMessage(e);
SQLState = ErrorMsg.findSQLState(e.getMessage());
downstreamError = e;
console.printError(errorMessage + "\n"
+ org.apache.hadoop.util.StringUtils.stringifyException(e));
throw createProcessorResponse(12);
}
PerfLogger perfLogger = null;
//如果还没有编译
if (!alreadyCompiled) {
//内部编译将自动重置性能记录器
compileInternal(command, true);
//然后我们继续使用这个性能记录器
perfLogger = SessionState.getPerfLogger();
} else {
//重用现有的性能记录器
perfLogger = SessionState.getPerfLogger();
//由于我们正在重用已编译的计划,因此需要更新其当前运行的开始时间
plan.setQueryStartTime(perfLogger.getStartTime(PerfLogger.DRIVER_RUN));
}
//我们在这里为cxt设置txn管理器的原因是,每个查询都有自己的ctx对象。
//txn-mgr在同一个Driver实例中共享,该实例可以运行多个查询。
ctx.setHiveTxnManager(queryTxnMgr);
checkInterrupted("at acquiring the lock.", null, null);
lockAndRespond();
//......省略......
try {
//执行hql 我们后面专门用一篇博客来研究
execute();
} catch (CommandProcessorResponse cpr) {
rollback(cpr);
throw cpr;
}
//如果needRequireLock为false,则此处的发布将不执行任何操作,因为没有锁
try {
//由于set autocommit启动了一个隐式txn,请关闭它 if(queryTxnMgr.isImplicitTransactionOpen() || plan.getOperation() == HiveOperation.COMMIT) {
releaseLocksAndCommitOrRollback(true);
}
else if(plan.getOperation() == HiveOperation.ROLLBACK) {
releaseLocksAndCommitOrRollback(false);
}
else {
//txn(如果有一个已启动)未完成
}
} catch (LockException e) {
throw handleHiveException(e, 12);
}
perfLogger.PerfLogEnd(CLASS_NAME, PerfLogger.DRIVER_RUN);
queryDisplay.setPerfLogStarts(QueryDisplay.Phase.EXECUTION, perfLogger.getStartTimes());
queryDisplay.setPerfLogEnds(QueryDisplay.Phase.EXECUTION, perfLogger.getEndTimes());
//获取所有驱动程序运行的钩子并执行它们。
try {
hookRunner.runPostDriverHooks(hookContext);
} catch (Exception e) {
}
isFinishedWithError = false;
} finally {
if (lDrvState.isAborted()) {
closeInProcess(true);
} else {
//正常只释放相关资源ctx、driverContext
releaseResources();
}
lDrvState.stateLock.lock();
try {
lDrvState.driverState = isFinishedWithError ? DriverState.ERROR : DriverState.EXECUTED;
} finally {
lDrvState.stateLock.unlock();
}
}
}
五、总结
1、用户在hive客户端输入hql
2、进行中断操作,终止正在运行的mr作业
3、解析用户在hive客户端输入的hql(将hql按照字符一个一个处理,遇到 ";" 就会将前面的处理成一个hql 放入列表中)
4、循环执行hql列表中的每一条hql
5、从sql语句中剥离注释,并去掉头尾空白符 并按照 '\s+' 分割成hql数组
6、判断hql 是 正常的sql(只分析这个) 还是 source 、quit 、 exit 还是 !
7、获取执行hql的驱动程序(对hql数组的第一个字符串进行转大写操作并匹配对应的驱动程序,默认会返回ReExecDriver)
8、编译hql
9、解析hql
10、语义分析和计划生成
11、校验计划
12、获取输出模式并制作查询计划,并设置mapreduce工作流引擎参数
13、授权检查
13.1、连接hive的元数据
13.2、设置输入输出
13.3、获取表和列的映射
13.4、添加正在使用的永久UDF
13.5、通过表扫描运算符检查列授权
13.6、表授权检查
14、设置执行计划并执行
版权归原作者 隔着天花板看星星 所有, 如有侵权,请联系我们删除。