

deephub翻译组:Alexander Zhao

在这篇文章中,我将用简单的术语解释决策树。这可以被认为是一个关于决策树的傻瓜教程,虽然我个人不太喜欢这种表达。
引言与直观感受
在机器学习领域,决策树是一种非参数的模型,可以用于分类和回归。这意味着决策树是一种灵活的模型,在我们正确构建的前提下,如果我们添加更多的特征,这并不会增加模型参数的数量。决策树可以用于输出类别标签的分类任务(比如植物是否属于某种类型),也可用于输出数值的回归任务(比如房价)。
决策树两种元素构成:节点和分支。在每个节点上,决策树对数据的一个特征进行评估,在训练阶段用于决策树的生长,而在推理阶段则让一段特定的数据沿着特定的流向在决策树上流动。

节点决定了流经此处的数据要遵循的路径
在构建决策树时,我们通过递归的方式来评估不同的特征,并在每个节点上使用最能分割数据的特征来构建决策树。这将在稍后详细解释。
也许最好的解释方法是看一个决策树是什么样子,建立一个对决策树的直觉。下图显示了一棵决策树的总体结构。
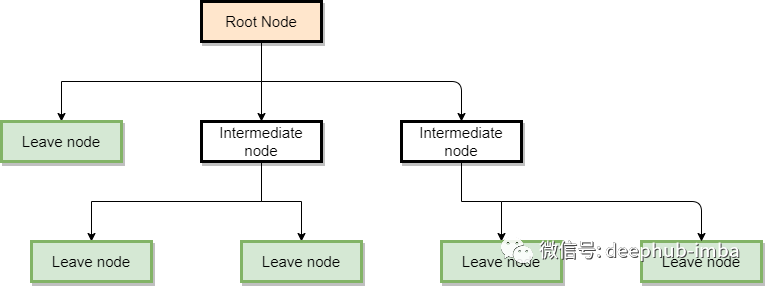
在这个图中,我们可以观察到三种节点:
- 根节点:数据流图的启动节点。在一般的决策树中,这一节点评估的是最能够分割数据的变量。
- 中间节点:这些节点计算变量,但不是进行预测的最终节点。
- 叶节点:这是决策树的最终节点,在这里对类别或数值进行预测。
好了,现在我们已经大致了解了决策树是什么,让我们看看它们是如何构建的。
决策树的训练
正如我们前面提到的,决策树是通过使用在我们的任务中最适合的特征递归地分割我们的训练样本来构建的。决策树的划分依据一些特定的指标,比如分类决策树使用基尼指数或信息熵,而回归决策树使用残差或均方误差。
我们使用的特征是离散的还是连续也会带来不同的划分过程。对于离散特征,假设其有N个可能的取值,那么就有N个划分点,对这N个划分点进行评估即得到N个评价度量。对于连续特征,我们将连续特征取值大小从最低到最高排序,依次取相邻的两个连续值的平均值作为划分阈值。
完成这个过程后,对于一个特定的节点,我们得到了一个特征列表,其中每个特征都具有不同的划分阈值,并且对于每个特征或阈值,我们也都得到了对应的评价度量(基尼指数或均方误差等)。然后,我们选择能够为子节点提供最高/最低的评价度量的特征/阈值的组合来划分数据。
我们不会讨论这些指标是如何计算的,因为不是我们文章的主题,但是如果您感兴趣的话,我将在最后留下一些资源供您深入研究。现在把这些度量(分类树的基尼指数和回归树的均方误差)看作是某种我们想要减少的误差。
让我们看一个两个决策树的例子,一个是分类树,一个是回归树,以便更清楚地了解这个过程。下图显示了为著名的Iris数据集构建的分类树,在该数据集中,我们尝试使用花瓣宽度、长度、萼片长度等特征预测三种不同花朵的类别:
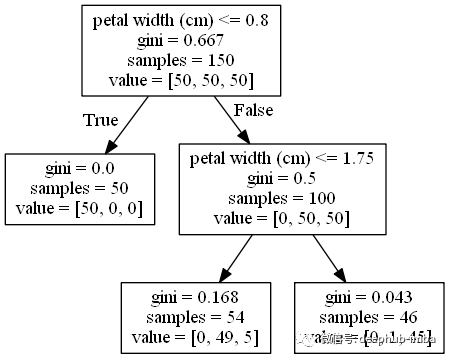
我们可以看到根节点从包含3个类的50个样本开始,其基尼指数(因为它是一个分类树,基尼指数越低越好)是0.667。
在该节点中,分割不同类别数据的最佳特征是花瓣宽度(以厘米为单位),阈值为0.8。这将产生两个节点,一个节点的基尼为0(只有一种类型的花的纯节点),另一个节点的基尼为0.5,其中含有其他两种花。
在这个中间节点中,使用1.75的阈值计算相同的特征(是的,这可能发生,而且如果特征很重要的话,重复使用同一特征的现象很常见)。现在产生两个不是纯节点的子节点,但是其基尼指数很低。
在所有这些节点中,我们也对数据的所有其他特征(萼片长度、萼片宽度和花瓣长度)进行了评估,并计算了它们的基尼指数,然而,给我们最好结果(最低基尼指数)的特征是花瓣宽度。
树没有继续生长的原因是我们对决策树往往规定了生长停止条件,否则它们会一直生长,直到每个训练样本分离到自己的叶节点。可用的停止条件包括树的最大深度、叶节点中的最小样本数或误差度量的最小减少量等。
现在让我们查看一个回归树,为此,我们将使用波士顿房价数据集,生成以下图表:
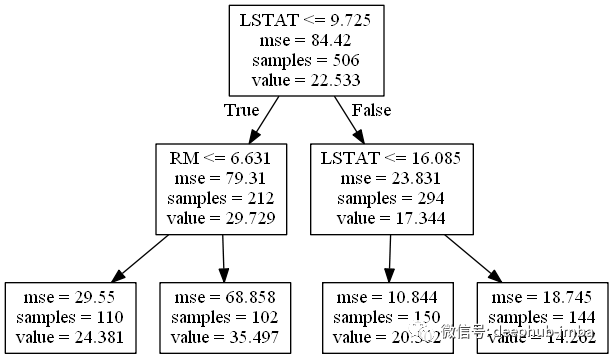
如上图所示,这里我们用的不是基尼指数,而是MSE(均方误差)。与前面的基于基尼指数的示例一样,我们的树是使用最能减少子节点的MSE的特征/阈值组合构建的。
根节点使用阈值为9.725的变量LSTAT(区域人口中地位低下者的百分比)作为最初分割样本。我们可以看到在根节点有506个样本,我们分别将其分为212个(左子节点)和294个(右子节点)。
左侧子节点使用阈值为6.631的变量RM(每个住宅的房间数),右侧节点使用阈值为16.085的变量LSTAT,生成四个美丽的叶节点。与之前一样,每个节点上也计算了所有其他特征与阈值的组合,但这两个变量是最适合分割数据的变量。
太酷了!现在我们知道决策树是如何构建的了,接下来让我们学习如何使用它们进行预测。
用决策树进行预测
使用决策树可以很容易地预测新样本的类别或数值目标值,这是这类算法的主要优点之一。我们要做的就是从根节点开始,查看计算对应特征的指标,然后根据该指标转到左或右子节点。
这个过程一直重复,直到我们到达一个叶节点。当这种情况发生时,根据我们面临的是分类问题还是回归问题,可能会发生两种情况:
a)如果我们面临分类问题,预测的类别将是该叶节点上对应的类别。还记得在分类树中,中间的叶节点上的值是[0,49,5]吗?这意味着到达该节点的测试样本属于该节点上含有49个训练样本的类的概率最高,因此我们将其分为这一类。
b) 对于回归树,我们在最后所做的预测是叶节点处的目标变量值的平均值。在我们的房价示例中,如果一个叶节点有4个样本,对应的房价分别为20、18、22和24,那么该节点的预测值将为21,即4个训练样本的平均值。
在下图中,我们可以看到如何对前一个回归树的新测试样本(房屋)进行预测。
注:**下图只显示了决策树用过的特征

好!现在我们知道如何使用决策树进行预测,让我们学习一下这一算法的优缺点。
决策树的优缺点
优点
- 决策树的主要优点是可解释性强。当其他机器学习模型接近黑盒时,决策树提供了一种图形化和直观化的方式来帮助理解算法的功能。
- 与其他机器学习算法相比,决策树需要训练的数据更少。
- 可同时用于分类和回归。
- 模型复杂度低。
- 对缺失值的容忍度较高。
缺点
- 很容易出现过拟合,对异常值也很敏感。
- 学习能力很弱:一棵决策树通常不会做出很好的预测,因此多棵树经常组合在一起形成“森林”,从而产生更强的集成模型。这将在下一篇文章中讨论。
结论与其他资源
决策树是一种简单而直观的算法,因此在解释机器学习模型的结果时,它们被大量使用。尽管单棵决策树的性能较弱,但它们可以组合在一起,获得功能强大的bagging或boosting模型。在下一篇文章中,我们将探讨其中一些模型。
如果要了解构建树的整个过程,请观看以下视频:
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********