
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
一、实验环境
Ubuntu18.04
Spark 2.4.0
Python 3.6.5
二、实验流程
1.PySpark交互式编程
在 spark下创建文件夹sparksqldata,将data01.txt上传到sparksqldata下:
cd /usr/local/spark
mkdir sparksqldata
cd /bin
./pyspark
(1)统计学生人数(即文件的行数)
lines = sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt")
res = lines.map(lambda x:x.split(",")).map(lambda x: x[0]) //获取每行数据的第1列
distinct_res = res.distinct() //去重操作
distinct_res.count()//取元素总个数

(2)统计开设课程总数
lines = sc.textFile("file:///usr/local/spark/sparksqldata/data01.txt")
df = lines.map(lambda x:x.split(",")).map(lambda x:x[1])
df1 = df.distinct()
df1.count()

(3)计算Tom所有课程的平均分
lines = sc.textFile("file:///usr/local/spark/sparksqldata/data01.txt")
res = lines.map(lambda x:x.split(",")).filter(lambda x:x[0]=="Tom")
res.foreach(print)
score = res.map(lambda x:int(x[2]))
num = res.count()
sum_score = score.reduce(lambda x,y:x+y)
avg = sum_score/num
print(avg)

(4)计算每一个人的选课总数
lines = sc.textFile("file:///usr/local/spark/sparksqldata/data01.txt")
res = lines.map(lambda x:x.split(",")).map(lambda x:(x[0],1))
each_res = res.reduceByKey(lambda x,y: x+y)
each_res.foreach(print)

(5)计算DataBase的选修人数
lines = sc.textFile("file:///usr/local/spark/sparksqldata/data01.txt")
res = lines.map(lambda x:x.split(",")).filter(lambda x:x[1]=="DataBase")
res.count()

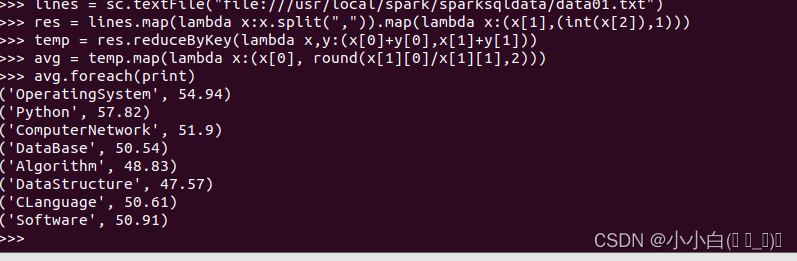
(6)计算每门课程的平均分
lines = sc.textFile("file:///usr/local/spark/sparksqldata/data01.txt")
res = lines.map(lambda x:x.split(",")).map(lambda x:(x[1],(int(x[2]),1)))
temp = res.reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1]))
avg = temp.map(lambda x:(x[0], round(x[1][0]/x[1][1],2)))
avg.foreach(print)
(7) 使用累加器计算共有多少人选了DataBase这门课。
lines = sc.textFile("file:///usr/local/spark/sparksqldata/data01.txt")
res = lines.map(lambda x:x.split(",")).filter(lambda x:x[1]=="DataBase")
accum = sc.accumulator(0)
res.foreach(lambda x:accum.add(1))
accum.value

2.编写独立应用程序
退出Pyspark交互模式:exit()
(1)在spark目录下创建文件A.txt,B.txt:
cd /usr/local/spark
vim A.txt
A.txt写入以下内容(一定要是竖着的):
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
vim B.txt
B.txt写入以下内容
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
然后创建C.py文件:
vim C.py
from pyspark import SparkContext
#初始化SparkContext
sc = SparkContext('local','remdup')
#加载两个文件A和B
lines1 = sc.textFile("file:///usr/local/spark/A.txt")
lines2 = sc.textFile("file:///usr/local/spark/B.txt")
#合并两个文件的内容
lines = lines1.union(lines2)
#去重操作
distinct_lines = lines.distinct()
#排序操作
res = distinct_lines.sortBy(lambda x:x)
#将结果写入result文件中,repartition(1)的作用是让结果合并到一个文件中,不加的话会结果写入到两个文件
res.repartition(1).saveAsTextFile("file:///usr/local/spark/result")
Python3 C.py
然后执行C.py文件:python3 C.py,运行结果如下:
 然后我们要查看去重的结果:
然后我们要查看去重的结果:
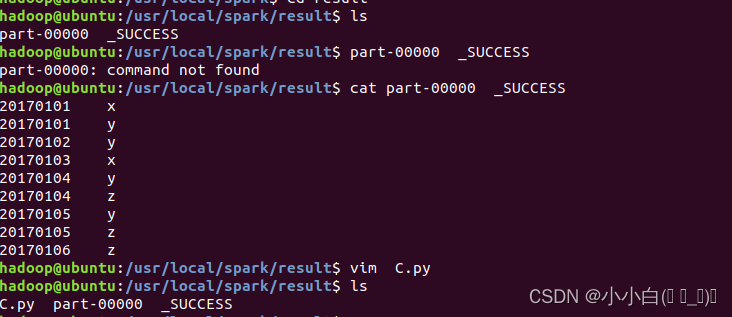
cd /usr/local/spark
cd result
ls
cat part-00000 _SUCCESS
(2)在spark目录下创建 Algorithm.txt、Database.txt、Python.txt
cd /usr/local/spark
vim Algorithm.txt:
小明 92
小红 87
小新 82
小丽 90
vim Database.txt:
小明 95
小红 81
小新 89
小丽 85
vim Python.txt:
小明 82
小红 83
小新 94
小丽 91
然后编写python程序:
vim score.py
from pyspark import SparkContext
sc = SparkContext('local',' avgscore')
lines1 = sc.textFile("file:///usr/local/spark/Algorithm.txt")
lines2 = sc.textFile("file:///usr/local/spark/Database.txt")
lines3 = sc.textFile("file:///usr/local/spark/Python.txt")
lines = lines1.union(lines2).union(lines3)
data = lines.map(lambda x:x.split(" ")).map(lambda x:(x[0],(int(x[1]),1)))
res = data.reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1]))
result = res.map(lambda x:(x[0],round(x[1][0]/x[1][1],2)))
result.repartition(1).saveAsTextFile("file:///usr/local/spark/result1")
然后执行Py文件:
python3 score.py

然后查看我们统计的结果:
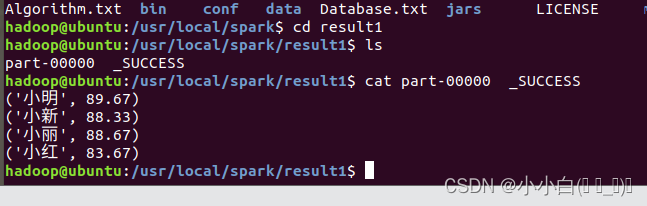
cd /usr/local/spark
cd result1
ls
cat part-00000 _SUCCESS
本文转载自: https://blog.csdn.net/zhangzili12/article/details/138453653
版权归原作者 小小白(ง •_•)ง 所有, 如有侵权,请联系我们删除。
版权归原作者 小小白(ง •_•)ง 所有, 如有侵权,请联系我们删除。