
系列文章目录
kafka学习(一):Kafka集群安装及踩坑
kafka学习(二):Kafka基本概念
文章目录
目录
1. 客户端开发
JDK8,maven项目,依赖的 kafka 版本为:
1.1 概述
生产者客户端的代码步骤大概有:
1)配置生产者客户端参数,创建生产者实例;
2)构建待发送的消息;
3)消息发送
4)关闭生产者实例
代码示例:
// 1. 配置生产者客户端参数,创建生产者实例
Properties properties = new Properties();
properties.put(ProducerConfig.ACKS_CONFIG, "all");
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka001:9092,kafka002:9092,kafka003:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 2. 构建待发送的消息
KafkaProducer<K, V> producer = new KafkaProducer<>(properties);
ProducerRecord<String, String> record1 = new ProducerRecord<>("test", "key1", "value1");
// 3. 消息发送
Future<RecordMetadata> send1 = producer.send(record1);
// 4. 关闭生产者实例
producer.close();
1.2 必要参数
bootstrap.servers:指定连接 Kafka 集群的 Broker 地址列表,格式为 host1:port1,host2:port2,这里不需要所有 broker 地址,因为客户端会从给定的 broker 里获取集群的信息,不过建议设置两个以上,防止其中一个宕机而连接不到集群;
key.serializer 和 value.serializer:broker 端接收的消息必须是字节数组的形式,而 KafkaProducer<String,String> 中的泛型对应的是消息中 key 和 value 的类型,生产者客户端通过 key.serializer 和 value.serializer 将 key 和 value 进行序列化,这里需要设置序列化器的全限定类名,如:org.apache.kafka.common.serialization.StringSerializer;
client.id:用来指定 KafkaProducer 对应的客户端 id,默认值为"",如果不只是,KafkaProducer 会自动生成一个非空字符串。
其他参数可以通过 org.apache.kafka.clients.producer.ProducerConfig 中的常量查看。
1.3 序列化
生产者需要用序列化器(Serializer)把对象转换成字节数组才能通过网络发送给 Kafka;而在消费端,消费者需要用反序列化器(Deserializer)把从 Kafka 中收到的字节数组转换成相应的对象。
客户端自带了很多序列化器,除了用于 String 的 org.apache.kafka.common.serialization.StringSerializer,还有 ByteArray、ByteBuffer、Bytes、Double、Integer、Long这几种类型,它们都实现了 org.apache.kafka.common.serialization.Serializer 接口,该接口定义:
public interface Serializer<T> extends Closeable {
/**
* Configure this class.
* @param configs configs in key/value pairs
* @param isKey whether is for key or value
*/
default void configure(Map<String, ?> configs, boolean isKey) {
// intentionally left blank
}
/**
* Convert {@code data} into a byte array.
*
* @param topic topic associated with data
* @param data typed data
* @return serialized bytes
*/
byte[] serialize(String topic, T data);
/**
* Convert {@code data} into a byte array.
*
* @param topic topic associated with data
* @param headers headers associated with the record
* @param data typed data
* @return serialized bytes
*/
default byte[] serialize(String topic, Headers headers, T data) {
return serialize(topic, data);
}
/**
* Close this serializer.
* <p>
* This method must be idempotent as it may be called multiple times.
*/
@Override
default void close() {
// intentionally left blank
}
}
configure() 方法用来配置当前类,从配置里获取一些属性;serialize() 用来执行序列化操作;close() 方法用来关闭当前序列化器,一般为空。
消费端可以通过实现这个接口,自定义序列化方式,相对的,也要在消费端定义对应的反序列化器。可以选择使用 Avro、JSON、Thrift、ProtoBuf 和 Protostuff 等通用的序列化工具来实现。
1.4 分区器
因为消息是在分区中保存的,分区对生产者很多时候却是透明的,这样在分区扩容、缩容时生产者不需要感知。而消息从生产者到到具体的分区中,就需要依赖到分区器。当然,如果消息 ProducerRecord 中指定了 partition 字段,就不需要执行分区器了。
消息在通过 send() 方法发往 broker 过程中,需要经过 拦截器(Interceptor)、序列化器(Serializer)和分区器(Partitioner),分区器的作用就是要给消息路由出具体要发送的分区。
Kafka 中提供的默认分区器是 org.apache.kafka.clients.producer.internals.DefaultPatitioner,实现了 org.apache.kafka.clients.producer.Partitioner 接口,接口定义:
public interface Partitioner extends Configurable, Closeable {
/**
* Compute the partition for the given record.
*
* @param topic The topic name
* @param key The key to partition on (or null if no key)
* @param keyBytes The serialized key to partition on( or null if no key)
* @param value The value to partition on or null
* @param valueBytes The serialized value to partition on or null
* @param cluster The current cluster metadata
*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
/**
* This is called when partitioner is closed.
*/
public void close();
/**
* Notifies the partitioner a new batch is about to be created. When using the sticky partitioner,
* this method can change the chosen sticky partition for the new batch.
* @param topic The topic name
* @param cluster The current cluster metadata
* @param prevPartition The partition previously selected for the record that triggered a new batch
*/
default public void onNewBatch(String topic, Cluster cluster, int prevPartition) {
}
partion() 方法用来计算分区号,返回值为 int 类型,参数为消息的主题、键、值以及序列化后的数据,同时,接口的父接口:org.apache.kafka.common.Configurable,同样有设置配置的接口。业务上可以通过实现自定义的分区器来保证消息的分区,在配置中使用 ProducerConfig#PARTITIONER_CLASS_CONFIG 的属性进行配置。
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, DemoParitioner.class.getName());
默认实现中若 key 不为空,则按照 key 的哈希值来计算分区,拥有相同 key 的消息会被写入到同一个分区;如果 key 为 null,那么消息将会以轮询的方式发往主题内的各个分区(每个批次更换分区)。
1.5 拦截器
拦截器(Interceptor)可以在消息发送前做一些处理,比如根据规则过滤、修改消息内容等,也可以用来在发送回调逻辑前做一些定制化处理,比如统计工作。
public interface ProducerInterceptor<K, V> extends Configurable {
/**
* This is called from {@link org.apache.kafka.clients.producer.KafkaProducer#send(ProducerRecord)} and
* {@link org.apache.kafka.clients.producer.KafkaProducer#send(ProducerRecord, Callback)} methods, before key and value
* get serialized and partition is assigned (if partition is not specified in ProducerRecord).
*
* @param record the record from client or the record returned by the previous interceptor in the chain of interceptors.
* @return producer record to send to topic/partition
*/
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record);
/**
* This method is called when the record sent to the server has been acknowledged, or when sending the record fails before
* it gets sent to the server.
* Any exception thrown by this method will be ignored by the caller.
* @param metadata The metadata for the record that was sent (i.e. the partition and offset).
* If an error occurred, metadata will contain only valid topic and maybe
* partition. If partition is not given in ProducerRecord and an error occurs
* before partition gets assigned, then partition will be set to RecordMetadata.NO_PARTITION.
* The metadata may be null if the client passed null record to
* {@link org.apache.kafka.clients.producer.KafkaProducer#send(ProducerRecord)}.
* @param exception The exception thrown during processing of this record. Null if no error occurred.
*/
public void onAcknowledgement(RecordMetadata metadata, Exception exception);
/**
* This is called when interceptor is closed
*/
public void close();
可以通过实现 org.apache.kafka.clients.producer.ProducerInterceptor 接口,来自定义拦截器,它有两个核心方法:onSend() 是在将消息序列化和计算分区之前调用,一般不要修改消息的 key、topic 和 partition;onAckknowledgement() 在消息发送失败或被应答之前调用,优先于用户设定的 Callback 之前执行,但是这个方法运行在 Producer 的 I/O 线程中,实现逻辑要简单,否则会影响消息的发送速度。其他方法:close() 方法用于在关闭拦截器时执行资源清理。另一个 configure() 方法同上,不再赘述。
拦截器通过 ProducerConfig.INTERCEPTOR_CLASSES_CONFIG 配置全限定类名,可以设置多个,通过逗号间隔,会按照顺序执行。拦截器异常不会影响后续执行,当某个拦截器依赖上个拦截器的执行结果时需要注意。
2. 原理分析
2.1 整体架构 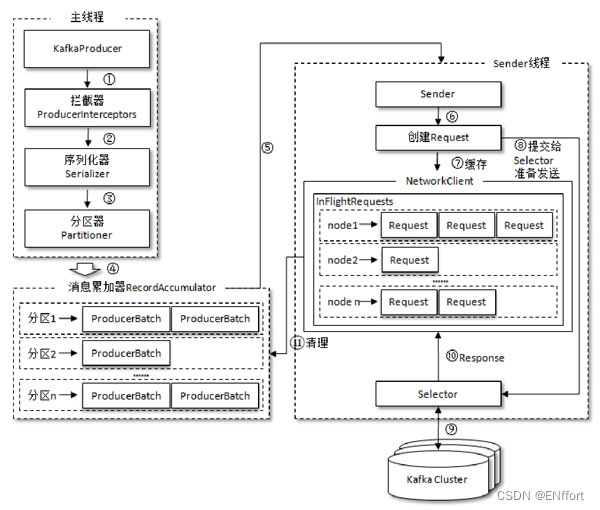
拦截器、序列化器、分区器执行顺序如上图,整个生产者客户端是由两个线程协调运行,分别为主线程和 Sender 线程。主线程中由 KafkaProducer 创建消息,然后通过拦截器(如果配置了)、序列化器、分区器,最后将消息缓存到消息累加器(RecordAccumulator)中,而 Sender 线程负责从中获取消息并且进行发送。
RecordAccumulator 负责缓存消息进行批量发送,从而减少网络传输的资源消耗以提升性能,大小可以通过 buffer.memory 配置,默认为 32MB;如果生产者发送消息的速度超过发送到服务器的速度,则会导致生产者空间不足,这个时候 KafkaProducer 的 send() 方法调用要么被阻塞,要么抛出异常,max.block.ms 配置阻塞的时间,默认 60000。
RecordAccumulator 中维护了一个 ConcurrentMap,缓存了每个 TopicPartition 要发送的数据,用双端队列(Duque<Request>)存储,队列中的内容为 ProducerBatch,消息写入缓存时写到队列,Sender 读取消息时,从头部读取。
ProducerBatch 是由一个或多个 ProducerRecord 组成,好处是:使字节更加紧凑,减少网络请求次数,提升整体的吞吐量,如果生产者客户端要向很多分区发送消息,可以将 buffer.memory 参数适当调大。
Sender 线程发送消息后,还会将消息放到 inFlightRequests(Map 结构,key 为 TopicPartition,value 为已发送还未收到响应的请求) 中,用来监控每个分区已发送但未收到响应的请求个数,最多为 max.in.flight.requests.per.connection 个,默认为 5,超过之后就不能再发送了,除非有请求收到了响应。通过比较 Duque<Request> 的 size 和缓存,可以判断消息是否积压,节点负载等情况。
2.2 元数据更新
InFlightRequests 还可以获得 leastLoadedNode,即所有 Node 中负载最小的那一个,可以通过这个 Node 获取元数据。
元数据是指 kafka 集群中的有哪些主题,哪些分区,leader、follower 副本分配情况,AR、ISR 集合,集群节点、控制节点等信息,当客户端中没有元数据,或超过 metadata.max.age.ms(默认 300000,即 5 分钟) 时间没有更新元数据都会进行元数据更新。
3. 参数详解
3.1 acks
用户指定分区中必须要有多少个副本收到这条消息,生产者才会认为这条消息是成功写入的。它是非常重要的参数,涉及消息的可靠性和吞吐量之间的权衡,可以设置的值如下:
acks=1:默认值,只要 leader 副本成功写入,就会收到来自服务端的成功响应,如果消息无法写入 leader 副本,比如 leader 副本崩溃、重新选举中,那么生产者就会收到错误的响应,为了避免消息丢失,生产者可以重发消息。如果消息写入 leader 副本并返回成功响应给生产者,且在被其他 follower 副本拉取之前 leader 副本崩溃,那么消息将会丢失。acks 设置为 1,是消息可靠性和吞吐量之间的折中方案。
acks=all 或 acks=-1:生产者发送消息后,等待所有 ISR 中的所有副本都收到消息后,才能收到来自服务端的成功响应。可靠性最强,但当 ISR 中只有 leader 副本时,同 acks=1,所以一般配合 min.insync.replicas 等参数联动。
acks=0:生产者发送消息后不需要等待任何服务端的响应。如果消息从发送到写入 Kafka 过程中出现某些异常,导致 Kafka 并没有收到这条消息,那么生产者也无从得知,消息将丢失。此配置可以达到最大吞吐量。
3.2 max.request.size
发送消息的最大值,默认 1MB,不建议盲目增大,因为这个参数还涉及一些其他参数的联动,如 broker 端的 message.max.bytes 参数,如果配置错误可能会引起一些不必要的异常。
3.3 retries 和 retry.backoff.ms
3.4 compression.type
3.5 connections.max.idle.ms
3.6 linger.ms
3.7 receive.buffer.bytes
3.8 send.buffer.bytes
3.9 request.timeout.ms
标签:
kafka
本文转载自: https://blog.csdn.net/ENffort/article/details/140061282
版权归原作者 ENffort 所有, 如有侵权,请联系我们删除。
版权归原作者 ENffort 所有, 如有侵权,请联系我们删除。