
闲聊
确实,“好”是一个抽象的词。
但是如果我们强行要描述一些“好”的代码,则可能需要用到一些具体化的词语如下:
以下内容相当于字典,仅供查阅:
- 灵活性:指代码的能力可以适应变化和新需求,容易进行修改和扩展。
- 可扩展性:指代码的能力可以方便地进行扩展,支持更多的功能和需求。
- 可维护性:指代码的易于维护、修改和调试,代码风格清晰、结构明了、注释充足,可避免不必要的错误和异常情况。
- 可读性:指代码容易被人理解,包括良好的命名规范、代码结构清晰明了、格式规范等。
- 可理解性:指代码容易被他人理解,包括注释充足、代码语义清晰、逻辑性良好等。
- 易修改性:指代码容易被修改和重构,可以快速响应变化和需求变更。
- 可复用性:指代码可以被重复使用,可以提高开发效率和代码质量。
- 可测试性:指代码容易进行单元测试、集成测试和性能测试等,可以提高代码的质量和稳定性。
- 模块化:指代码结构清晰、各个模块之间耦合度低,易于维护和扩展。
- 高内聚低耦合:指代码中各个模块之间的关联性低,可以提高代码的灵活性和可扩展性。
- 高效:指代码执行速度快,占用资源少,可以提高用户体验。
- 高性能:指代码的响应速度快,负载能力强,可以保证系统的稳定性和可靠性。
- 安全性:指代码不容易受到恶意攻击和非法访问,可以保障用户的隐私和安全。
- 兼容性:指代码可以在不同的平台、不同的环境下运行,可以提高代码的可用性和适用性。
- 易用性:指代码易于使用,用户体验良好,操作简单、直观。
- 整洁:指代码结构清晰、命名规范、风格统一、没有冗余代码和不必要的复杂度。
- 清晰:指代码逻辑清晰,易于理解和维护。
- 简单:指代码尽可能简洁,不复杂,代码可读性强,易于理解。
- 直接:指代码表达的含义直接,代码的目的清晰明了。
- 少即是多:指代码越少越好,不要出现冗余的代码和复杂的逻辑,可以减少代码的维护和修改的难度。
- 文档详尽:指代码的注释和文档详细、准确、清晰,方便其他开发人员理解和维护代码。
- 分层清晰:指代码的架构清晰、模块划分明确,可以提高代码的灵活性和可扩展性。
- 正确性:指代码执行结果正确,不会产生异常或错误。
- 健壮性:指代码在出现错误或异常情况下能够保持稳定、可靠的运行,不会导致系统崩溃或数据丢失。
- 可用性:指代码易于使用、可靠稳定,用户体验良好。
- 可伸缩性:指代码可以适应不同的需求和规模,支持大规模的并发访问和数据处理。
- 稳定性:指代码运行稳定,不容易出现错误和异常情况。
- 优雅:指代码逻辑简洁、清晰、易于理解和修改,体现了编写者的思维深度和编程技巧。
通常,谈到为什么要好好写代码,下面这句话贴出来是很有说服力的,并且还能带给人一种无法反驳的感觉,我们一起看下:
编写稳定、规范、易读、优雅的代码可以提高开发效率、降低代码维护成本、增加代码的可读性、可扩展性、可重用性、可测试性等方面的优点,有助于保证代码的质量和稳定性。同时,也可以提高团队协作效率,减少代码错误和不必要的修改,保证项目的顺利进行。
如果要让逼格再高一点,还需要增加一些语录如下:
C++语言发明者:
我喜欢优雅和高效的代码。代码逻辑应当直截了当,令缺陷难以隐藏;尽量减少依赖关系,使之便于维护;依据某种分层战略完善错误处理代码;性能调至最优,省得引诱别人做没规矩的优化,搞出一堆混乱来。整洁的代码只做好一件事。 ——Bjarne Stroustrup
面向对象思想奠基人,UML提出者
整洁的代码简单直接。整洁的代码如同优美的散文。整洁的代码从不隐藏设计者的意图,充满了干净利落的抽象和直截了当的控制语句。 ——Grady Booch
SOLID原则提出者
函数应该做一件事。做好这件事。只能做这一件事。** **——罗伯特·C.马丁(Robert C.Martin)
高性能和并行计算领域先驱
程序必须是为了给人看而写,给机器去执行只是附带任务。 ——Gordon Bell
Linux之父
拙劣的程序员担心代码。好的程序员担心数据结构及它们的关系。 ——Linus Benedict Torvalds
经过上面的介绍,我们稍微有了一些关于“**好**”代码的标准。也知道了如何从哪些方面去格 “**好代码**”这三个字。但是“**格**”并不是结论,而是手段。看完如果你有种自己不配写代码的感觉,那很正常,正常人也做不到这么绝,**AI**除外。到这里为止,接下来,进入正题。
正题
我写这篇博文的出发点,只是倾向于记录和总结,并试图讲述一些启发性的故事。在经过无数人多年编程工作经验的沉淀后,慢慢总结出来的一些具有参考价值和操作性的思维和习惯,下面我尽量地简洁的语言的方式进行描述。
接下来的内容的总览如下:
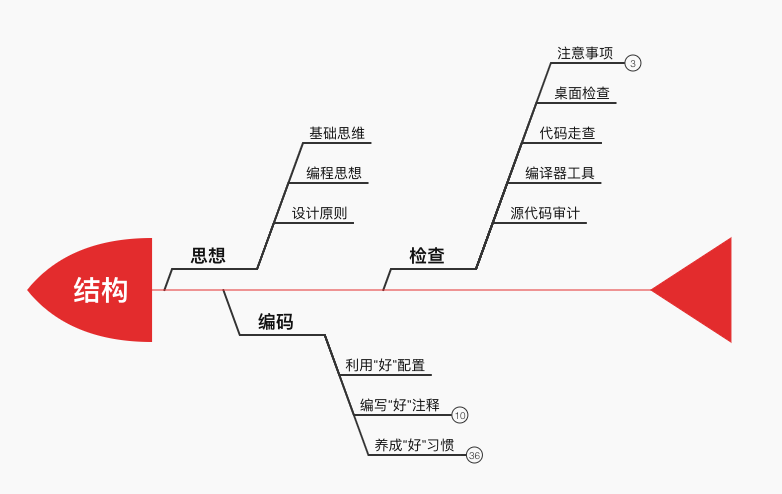
思想
关于程序设计
从大的方面讲有物理架构、逻辑架构、开发架构、运行架构、数据架构之分。
从小的方面讲有编程思想、设计原则、设计模式、算法、数据结构、以及一些编码习惯比如格式、命名、注释、测试等。
为了加深我们对编程的理解,熟悉并理解一些编程上的思想至关重要。
说到底,最终这些思想只是为了将程序结构抽象成**数据流**和**控制流**,从而将它们设计成某种基本结构,然后将这个基本结构进行封装再造组成**业务流**,最终来达到简化程序描述的目的。
基础思维
除了以上常见的设计思想外,更深入地理解可以再进行细分。
三十六种基础思维
这里抛个砖,感兴趣的同学可以戳 三十六种基础编程思想。

编程思想
常见的软件设计思想有 **OOP、POP、AOP、DDD、FP、RP**等。本篇主要介绍下面的三大编程思想。

此外,DDD(领域驱动设计)建议有闲工夫的同学看看,自2009年其实已经开始应用,只是近些年由于微服务架构的飞速演进,DDD将可能成为大型企业级微服务架构设计最适用的思想。有兴趣的可以看看《微服务架构设计模式》这本书。
面向过程编程
一句话理解:根据业务逻辑从上到下步步求精地写代码。
特点:模块化、流程化
好处:性能高,容易理解。
不足:维护性和扩展性低。
面向对象编程
一句话理解:分解业务以建立对象,明确对象的属性和行为,通过编排对象和数据实现业务。
特点:抽象、封装、继承、多态
好处:维护性、扩展性、复用性高
不足:性能比面向过程低
面向切面编程
一句话理解:提取相同的业务动作点,形成切面,针对切面业务编写代码。
特点:延迟设计、关注业务而不是业务细节
好处:降低耦合、简洁代码、更加专注业务
不足:需要动态代理,通常依赖外部实现,编程复杂度略微提升
设计原则
设计原则可以理解成基础思维实施的方法论,它们会在一遍又一遍的认知过程中培养我们的编程思维,这些非常重要。接下来,本文将逐层捅破每个设计原则的窗户纸。
一般性原则
一般提到设计原则,想起来的都是SOLID等等,其实还有一些一般性的原则,它们也极富指导思想。
DRY原则
原文:
Don’t Repeat Yourself 别做重复的事
核心思想就是请你“偷懒”,别反复造轮子。
KISS原则
原文:
keep It simple & Stupid 保持简单
国内有:“大道至简”。
国外有: 奥卡姆剃刀定律,14世纪英格兰的逻辑学家、圣方济各会修士奥卡姆的威廉(William of Occam,约1285年至1349年)提出。
YAGNI原则
原文:
you Ain’t Gonna Need It 你不需要它
核心要义是不要过度设计,不要因迎合概率很低的设计而花费过多时间。
没了,这三个原则就这么简单,但是其蕴含的哲理是覆盖很多领域的,包括如何去过你的一生。
软件设计七大原则
接下来就是熟悉又陌生的环节,其实有些原则每天都在用,但是你就叫不出来名字。
单一职责原则(SRP,Single Responsibility Principle)
原文
There should never be more than one reason for a class to change
一个类,应当只有一个引起它变化的原因;即一个类应该只有一个职责。
理解
主要是理解什么是职责,我们可以从它的另一个名字“**单一**功能**原则**”来理解。一个类、接口、方法,尽可能只实现一个功能。正如“人一心不可二用”。
例子
1、比如修改用户密码尽量单独写一个接口,不要和修改用户信息接口混用。
2、举一个更具体的例子:现在有一个媒体播放器接口。其中有四个方法。具体的实现类比如MP3、MP4等实现这个接口同时实现播放方法即可完成接口的职责。
那么,如果后面继续增加一个媒体下载上传的功能。一般来说,可能有的同事图简单,直接就在MediaPlayer接口中增加两个方法 download(),upload()。
但这种行为违背了SRP原则。正确的做法是,再新增一个接口 MediaTransfer 接口。这样,后续所有对媒体下载接口的调整只需要考虑到对实现了MediaTransfer接口的类进行审查即可。

优点
1.增强对象的稳定性
2.提高可读性
3.降低变更风险
4.高内聚,低耦合
建议
1.职责划分要考虑可变因素与不可变因素,以及相关的收益成本比率。
2.这个原则由于业务上要求非常严格,实际编程中一般很少体现。但是我们要尽量做到接口必须遵循,类尽量遵循。
开闭原则(OCP,Open Close Principle)
原文
Software entities should be open for extension,but closed for modification.
软件实体应当对扩展开放,对修改关闭。
理解
属于面向对象设计中“可复用设计”的基石,是OOP中最重要的原则之一。说大实话就是:在扩展业务时不要改原来写过的代码,如果非改不可,就是违背原则。
例子
假设有一个图形编辑器GraphicEditor,它可以绘制 圆形、三角形、矩形。并且后期可能会需要绘制更多的图形。如果先定义一个Shape的抽象类,并提供一个抽象方法,这样每次增加新的图形时,只需要继承抽象类实现抽象方法即可完成图形绘制业务的扩展如 OtherGraphic.class。
这样一来,新增绘制业务时,仅需要增加一个类,无需修改之前的任何代码,即可完成业务扩展。


优点
1.提高复用性
2.提高扩展性
3.提高可维护性
建议
1.在编写复杂业务逻辑前,多站在整体业务的角度考虑,建立良好的抽象模型
2.完成设计后,仔细评估并以注释的形式描述扩展方案,以检查抽象层次是否遵循OCP原则。
里氏替换原则(LSP,Liskov Substitution Principle)
原文
A derived class (subclass) object can replace its base class (superclass) object in a program.
派生类(子类)对象可以在程式中代替其基类(超类)对象。
理解
**子类可以替代父类工作,而反过来则不一定。**
在编译期,Java语言编译器会检查一个程序是否符合里氏替换原则,这是一个无关实现的、纯语法意义上的检查。里氏替换要求凡是使用基类的地方,子类一定适用,因此子类必须具备基类的全部接口。或者说,子类型的接口必须包括全部的基类的接口,而且还有可能更宽。如果一个Java程序破坏这一条件,Java编译器就会在编译程序时抛出错误提示,并停止编译。例如,一个基类Base声明了一个public方法method(),其子类Sub就不能将该方法的访问权限从public改换成为private或protected。即子类不能使用一个低访问权限的方法覆盖基类中的高访问权限的方法。
例子
Java语言编译器会检查一个程序是否符合里氏替换原则,这是一个无关实现的、纯语法意义上的检查。并提供4点必须遵循的编译时规范:
1.子类必须实现父类的抽象方法,但不得重写(覆盖)父类的非抽象(已实现)方法。
2.子类可以有自己的个性
3.覆盖或实现父类的方法时输入参数可以被放大
4.覆盖或实现父类的方法时输出结果可以被缩小
优点
1.约束继承泛滥
2.加强程序的健壮性、兼容性,提高可维护性和扩展性,降低需求变更时引入的风险。
建议
1.尤其要注意不得重写父类的非抽象已实现方法。比如下面这个例子:

可以看到,子类确实可以替换父类工作,但是工作结果却并不一致,违背了LSP原则。
接口隔离原则(ISP,Interface Segregation Principle)
原文
Clients should not be forced to depend upon interfaces that they do not use。
客户端不应该被强迫依赖它不需要的接口。
理解
简单来说,ISP原则提倡接口中的方法尽量地少。我们也能在阅读源码的时候发现很多最小接口中只有一个方法,或者甚至直接是一个空的接口。
例子
假设有一个Animal接口形容动物的动作,比如eat()、run()、swim()、fly()等,如果将三个动作都揉在一个接口中。这是如果要声明一个Dog对象实现Animal接口,那么不得不覆写上面所有方法,然而狗不能fly(),这个接口对他来说没有意义。这种设计必将会导致类的臃肿和代码重复,不易于理解和阅读。
建议进行以下拆分,使得每个接口的粒度更细。

优点
1.扩展性高
2.易读,层次分明
3.稳定性高
4.减少冗余
建议
1.编码前多结合业务建立抽象概念。
2.类之间如果存在依赖关系,请一定建立在最小接口之上。还是上面那个例子,现在有某个人SomeBody要喂食某个小动物,那么Feed方法的参数一定是依赖于最小的接口来设计。如下:
void feed(Animal animal){
animal.eat();
}
依赖倒置原则(DIP,Dependence Inversion Principle)
原文
High level modules should not depend upon low level modules. Both should depend upon abstractions. Abstractions should not depend upon details.Details should depend upon abstractions.
翻译过来,包括三层含义:
- 高层模块不应该依赖低层模块,两者都依赖其抽象
- 抽象不依赖细节
- 抽象不依赖细节
理解
先弄清几个词:
高层/低层模块(类A直接依赖类B,如果要将类B改成类C,则需要改动类A的代码。在这个场景下,A一般是高层模块,负责编排业务。B和C属于底层模块,负责基本的原子操作。)
抽象(即抽象类或接口,是不能够实例化的)。
细节(即具体的实现类,实现接口或者继承抽象类所产生的类,可以通过关键字new直接被实例化)。
接下来,为了避免直接修改类A的代码,并且减少类B发生变化时对业务产生的影响。可以采用这样的方法:
** 类A直接依赖于接口I,类B和C实现接口I。**
总的来说,依赖倒置原则实际上就是要求“面向接口编程”,高层模块和底层模块之间应该通过抽象进行解耦,分离细节的实现类,以实现OCP原则。
例子
上面所举的ABC例子代码如下:
public class DIP1 {
interface I {
void doSmt();
}
class A {
void justDo(I i) {
i.doSmt();
}
}
class B implements I {
@Override
public void doSmt() {
// do B things
}
}
class C implements I {
@Override
public void doSmt() {
// do C things
}
}
}
这个例子就是DIP原则的最直白体现,细节的多变的最终被抽象的稳定所替代,高层执行模块不应过于关注低层模块的实现细节,而是仅关注彼此之间抽象的“契约”。
优点
1.提高复用性
2.提高扩展性
3.提高可维护性
4.降低耦合性
建议
1.参与核心业务的每个类都尽量有接口或抽象类,或二者均有。
2.变量表面类型尽量是接口或抽象类
3.任何类都不应该从具体类派生
4.结合LSP原则使用
** 上述五个原则又被称之为 SOLID五大原则,分别是 SRP、OCP、LSP、ISP、DIP 五个设计原则。**
迪米特法则(LKP,Least Knowledge Principle)
原文
The dependency of one class to another one should depend on the smallest possible interface.
一个对象应该对其他对象保持尽可能少的了解
理解
这个法则又叫最少知识原则,重点强调**不要知道得太多**,领悟过来大致就是:*“不跟"陌生人"交流,尽量减少与朋友的交流”*。总的来说,有两个要注意的点:
第一是分清哪些是朋友。
在LKP法则中,针对当前对象O来说,朋友是指:
- O本身(this)
- O的成员对象
- 如果O的成员对象是集合,那么集合中的元素也是朋友
- O所创建的对象
- O的方法中的参数
以上这些对象同O之间存在 关联、聚合、组合关系,可以直接访问这些对象的方法,所以属于密友。
第二是如何做到朋友之间知道的不多:
- 尽可能降低成员变量和成员方法的访问权限。(比如private、protect、default、public关键字)
- 设计对象的模板时,只要可以,就设计成不可变。(比如final)
- 类之间松耦合(参考SRP原则)
- 如果类之间必须存在引用,请将引用降到最低。
以上这些要求主要是为了减少对象之间的交互而提出的一些可执行的策略,通常,如果两个对象不需要直接通信,可以通过第三方转发该调用,来降低类之间的耦合度提高模块的独立性。
例子
假设现在有一家公司的总经理 President 需要看看自己企业下的雇员清单。那么直接让 总经理去和员工交流,一个个去点名显然是不合适的。这时候引入一个第三者 Manager 经理,由他来清点员工名单,然后呈现给总经理。这令 President 和 Manager、Employee之间关系更为清晰,并且隔绝了不必要的交流,遵循LKP原则。代码如下:

优点
1.降低耦合性
2.提高了复用性
3.利于扩展
建议
1.这个法则略微狭义,抽离出来的中间类也仅仅只是传递间接的调用,实操时注意不能用力过猛,因为会增加大量中介类,使通信效率降低。使用不当可能会使系统结构变得更复杂难懂。
合成复用原则(Composite/Aggregate Reuse Principle,CARP)
原文
尽量使用对象组合(part-of)或聚合(has-a),而不是继承关系达到软件复用的目的。
理解
尽可能地用组合和聚合替代继承。说明白点就是指:使A对象持有B对象的引用。
另外,要明白上面那句话,就要分清依赖,关联、组合、聚合这几个概念。
如何分清?
如果B是A不可分割的一部分,那么A和B是组合关系
如果B对A来说可有可无,则是聚合关系
如果A和B是平级则是关联关系
如果A只是在其方法的参数中对B进行引用,则属于依赖关系。
例子
设计一个SQL客户端需要能够持有多种不同的连接对象进行工作,这里抽象了个DBConnection作为获取连接的接口,同时组合DBConnection和SqlClient,并通过set的形式进行关联。这种设计初衷,能够完全解耦DBConnection实现类与SqlClient。下次我们需要实现一个新的连接类型时,只需增加一个OtherConnection实现类并实现DBConnection接口即可。具体如下图:

优点
1.降低耦合
2.保证一个类变化时对另一个其他类造成的影响相对更少(遵循LKP原则)
3.灵活度高,可以在代码运行中动态地拔插同一接口的其他具体实现类。
建议
1.建议不要滥用从而导致组合关系错综复杂,违反其他原则。
编码
接下来进入熟悉的编码环节。最终要达到的目的只有一个:写更简单的代码。
利用“好”配置
配置方面的步骤说明篇幅较长,不在这里展开,有兴趣的朋友可以参考:
配置代码风格,可以转到我的这篇博客: 通过配置IDEA实现后端代码风格统一
配置注释模板,可以转到我的这篇博客: 通过配置IDEA实现注释风格统一
编写“好”注释
为什么写注释?
** 注释**是软件开发过程中的性价比极高的一个工具。在你编码之前,只需要花两成的精力就能在将来某一天帮你节省八成的阅读源码的时间。
** 注释**同时也是一种工具,是一种习惯,为了团队内其他成员,也为了将来的自己。
怎么写注释?
1、使用注释模板
可以参考👆🏻内容中提到的 配置注释模板
2、描述what和why而不是how
很多时候,代码本身就是how,而编写注释的人最需要说明的只是编写这段代码的理由以及背景。
3、分层注释
为高层次的代码写注释,需要提供更抽象的信息,比如代码的设计思路/扩展时的影响范围/在业务中承担的职责等。 为低层次的代码写注释,需要提供更细节的信息,比如范围参数的左开/右闭,时间/金额/重量作为入参时的单位。
4、分段注释
首先把代码块分解成多个“段落”,每一个段落都执行单一的任务; 然后在每一个“段落”开始之前添加注释,告诉阅读代码的人接下来的这段代码是干什么用的。

5、及时更新
如果注释的代码原有逻辑发生变更,请在修正代码后一定及时更新注释的内容,保证有效性否则再优雅的注释也是徒劳无功。
6、及时删除
直接注释掉代码而不是删除,是一个愚蠢的做法。这样会导致新接手代码的人不敢删掉注释的代码,因为他们相信代码放在那儿肯定有原因。他们更加不敢放开注释,因为他们不知道为什么要注释掉。
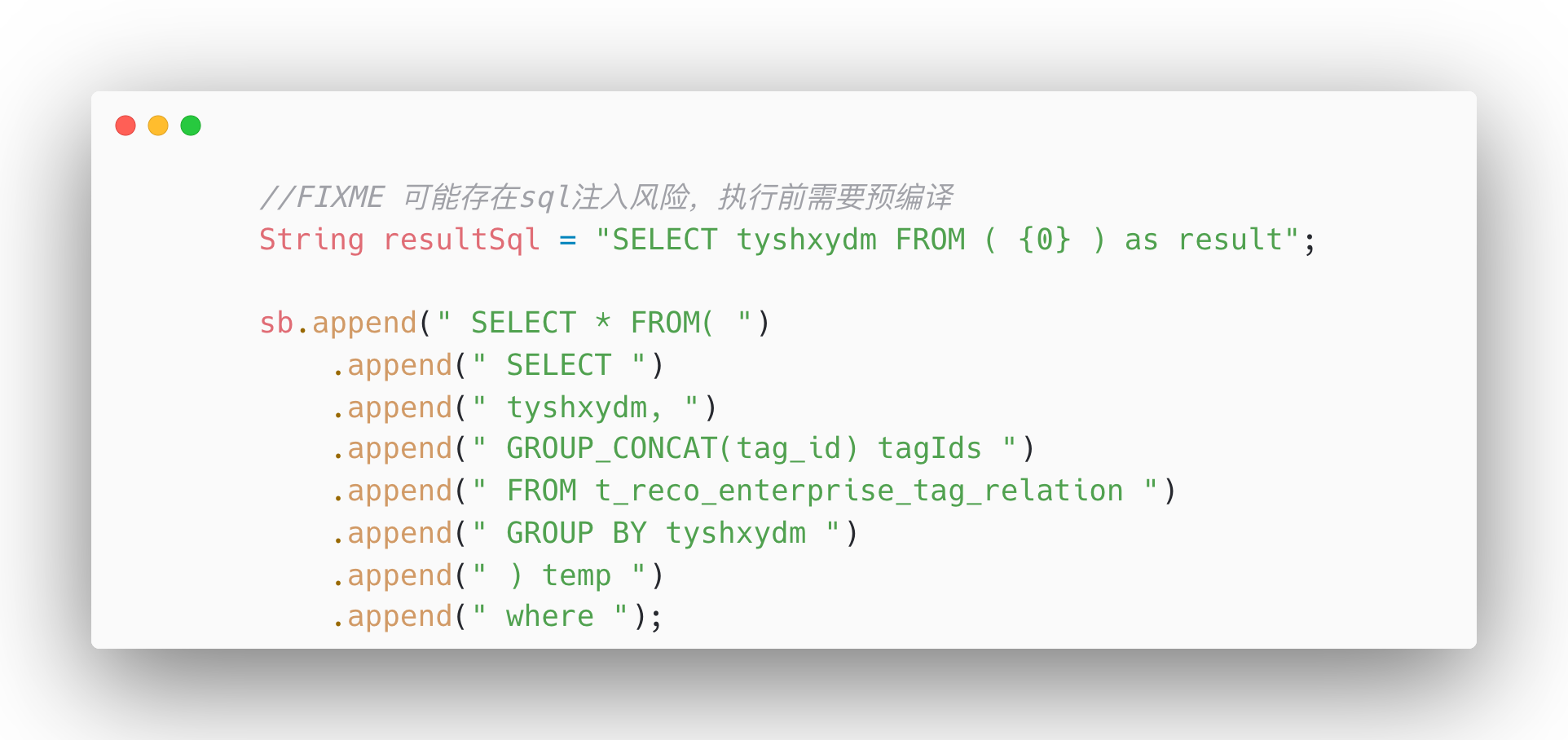
7、不要侮辱别人的智商
注释里不要写废话,代码能清晰表达的,再为其加上注释会扰乱专注力。比如下面这种:

8、使用特殊标签
多采用团队内部统一的标签如:
TODO:待办
**FIXME **需要修正
**XXX **虽然能用,但有待商榷
HACK 根据需求可以自行砍掉一些代码
其中todo尤为重要,提交到仓库前编辑器也会默认进行TODO检查,以防有任何遗漏的需求未开发。善用这些标签,有助于组织内部更“协调”地工作。 注意不要打一些奇怪的标记,诸如 // debug @@@@@@@@@@@@@ 、// ===== large number /// 之类,此类标记通常会随着时间的推移逐渐膨胀,真正有效的信息会沉没在背景噪声中。

9、有礼貌且直截了当
不要在注释里没有礼貌地吐槽,比如 “要注意一些愚蠢的用户会输入一个负数” 或者 “修正由菜鸟工程师写的愚蠢得可怜的代码而导致的副作用”云云,这样的注释对写的人没有任何好处,因为你永远不会知道将来这些会被谁来阅读,你的老板,一个客户或者是刚才被你数落的愚蠢可怜的工程师。
此外,不要在注释里卖弄ASCII艺术,写笑话,作诗或过于冗长,尽量保持简单和直接。
10、不要重复
注释与代码重复是很常见的一种错误,这也是很多开发者认为注释冗余而没有必要的原因之一。比如同一段功能相似的代码,反复进行注释。如下:

此外,某些程序员喜欢在注释中使用代码中的变量名或其中的单词,这种情况也是**注释重复代码**的一种体现,下面这种就是纯粹为了注释而注释。

在参考上述建议的同时,我们也最好让代码保持良好的设计,尽量简洁,复杂的逻辑如果企图完全依靠注释来引导别他人去理解最终也只是事倍功半。
养成“好”习惯
相信维护一位已经离职的同事代码的痛楚已经深深地印刻在我们每个人的心里。“奇长无比的方法”、“其深无比的调用”、“错综复杂的引用”,“耐人寻味的深意”......读不懂的同时找不到人问,最后只能心里默默地问候这位深藏功名的兄弟。
其实最终这些都是因为代码习惯导致的。养成一些好的编码习惯,打好注释,遵循设计原则这些问题也就解决了。
经过我一段时间的总结提炼,以下列举了30个良好的编码习惯,如有不足,欢迎指正。
1、及时沟通
写代码的时候不要伸手就来,先与项目负责人进行沟通,弄清楚这段业务的来龙去脉,仔细思考一番参与其中的各个对象扮演的角色,梳理清楚**数据流**、**业务流**,如果设计状态变化必须提前梳理所有状态是什么?每个状态变更的**触发点**是什么?再着手构思代码该怎么写。
此外,遇到不确定的问题及时与同事交流,刚进一个项目时,由于对工程不熟悉,对整体业务架构、技术方案不了解从而遇到一些细节上的问题,如果闭门造车,默默埋头处理,苦了自己不说,更容易节外生枝。往往沟通后会发现,其实这类问题可能组内早已遇到过,已经有了成熟的解决方案,沟通之后就会变得清晰起来。
** 所以及时沟通尤其重要,通常能省自己的事,也省他人的事。**
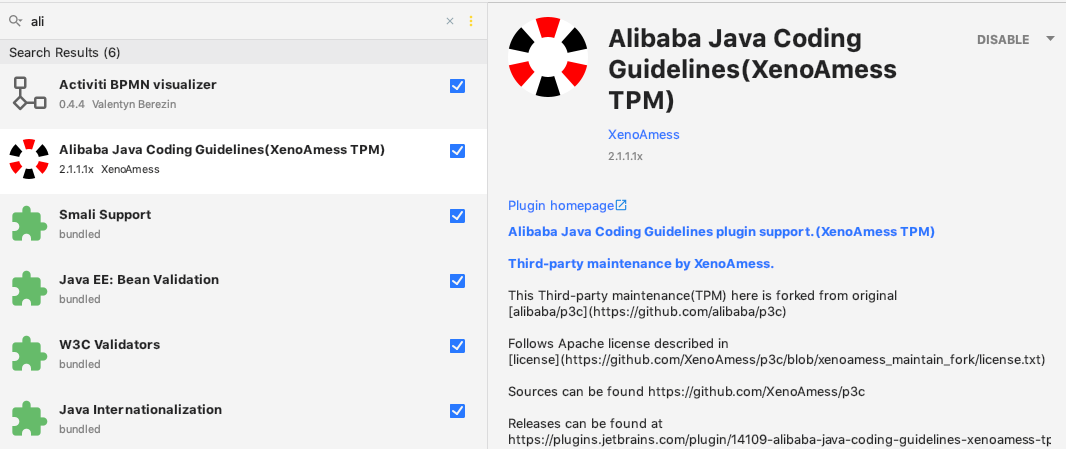
2、安装P3C代码检查插件
后端代码格式化神器,自带扫描、编写检查、以及详细的优化用例,通常一般简单的代码走查也可以通过这种方式进行,你值得拥有。

3、规范命名
命名是写代码中最频繁的操作,比如项目、类、属性、方法、参数等。想取一个好名字,可以参考下几点:
- 可读
比如下面这个,读不出来,也说不出含义来。

换成下面这个,就清晰了。

- 会意
比如需要定义一个变量需要来计数,直接定义index没有任何的实际意义,没有体现出数量的意思,所以我们应当指明数量的业务含义。

4、规范格式
好的代码格式能够让人感觉看起来代码更加舒适。
好的代码格式应当遵守以下几点:
- 合适的空格
- 代码对齐,比如大括号要对齐
- 及时换行,一行不要写太多代码
现在很多开发工具如IDEA,XCode等均支持一键格式化,可以帮助美化代码格式。
5、方法别太长
就是字面的意思。一旦代码太长,给人第一印象就是复杂,没有读的欲望。同时方法太长的代码可能读起来容易让人摸不着头脑,不知道哪一些代码是同一个业务的功能。通常方法保持在80行以内,不够写就要反思是否业务设计不够简洁,或考虑采取提取方法或适当抽象来减少代码量。
试想一个方法写了1000多行,各种if else判断,下次遇到其中的业务变更需要调整代码,你作何感想?
所以一旦方法过长,可以尝试将相同业务功能的代码单独抽取一个方法,最后在主方法中调用即可。或者更好的方式是利用策略模式、工厂模式或者建造者模式对其进行清理重构。
6、面向对象编程
理解面向对象的编程思想,多采用以下思路编写代码。常见的思路有:
- 保持类和接口的单一职责
- 组合/聚合代替继承
- 使用设计模式
- 面向接口编程
编程思想远不止这些,之前也做过了详细介绍。
7、尽量用工具类
比如在对集合判空的时候,一般这么写:

但是,对于初学者来说无可厚非,有一定工作经验后,这种方式并不推荐,可以通过一些判断的工具类进行替换:

不仅仅是集合,还有一些关于字符串判空,大小比较,集合处理,均可以用过一些诸如:CollectionUtils\Arrays\BeanUtils\Objects\MapUtils的工具类去处理。做java后端开发的可以熟悉一下hutool工具包,前端同样也有Lodash等工具包可供参考。
8、尽量预估容器大小
比如在写代码的时候,经常会用到List、Map来临时存储数据,其中最常用的就是ArrayList和HashMap。但是用不好可能也会导致性能的问题。
比如在ArrayList和HashMap如果用于存储已知上限的数据,可以预先指定默认大小,以免其自行扩容干耗性能。
9、尽量不传递null
这个很好理解,不传null值可以避免方法不支持为null入参时产生的空指针问题。
当然为了更好的表明该方法是不是可以传null值,可以通过org.springframework.lang包下的@NonNull和@Nullable注解来进行标记。@NonNull就表示不能传null值,@Nullable就是可以传null值。这种标记仅是在编译器进行弱提示,实际代码依然可以正常运行。


10、尽量不返回null
尽量不返回null值是为了减少调用者对返回值的为null判断,如果无法避免返回null值,可以通过返回Optional来代替null值。 如果不想这么写,也可以通过@NonNull和@Nullable表示方法会不会返回null值。

11、哨兵式if
碰到比较麻烦一点的逻辑多层if判断可能会导致“逻辑地狱”。我们来一起看看这种情况:

面对这种情况,可以换种思路,使用哨兵式if写法来减少阅读时产生的困扰:

12、优雅地参数校验
当前端传递给后端参数的时候,通常需要对参数进场检验,一般可能会这么写

此时Controller接口就需要方法上就需要加上@Valid注解

13、提取公用
重复的代码如果长期不管,在经过多位开发添砖加瓦后可能会变得又臭又长,变得极难维护。 所以一般遇到这种情况,可以抽取成一个工具类,或者抽成一个公共的父类。此外,也可以抽空对复杂的业务逻辑进行合理的抽象、分层,来减少业务代码之间的依赖,降低耦合性。
14、规范日志打印
适时地打印日志能帮助我们快速定位代码中的问题,采用不同的level对日志内容进行分级。当线上业务因为某个偶然的故障发生报错时,我们一般可以根据预先打印好的异常日志进行精准地定位。
打印一个有帮助的日志可以参考以下几点要求:
- 可搜索性,要有明确的关键字信息
- 异常日志需要打印出堆栈信息
- 合适的日志级别,比如异常使用error,正常使用info
- 日志内容太大不打印,比如有时需要将图片转成Base64,那么这个Base64就可以不用打印
15、统一类库
问题
一个庞大的项目往往会引入很多依赖,从而导致项目中多了很多相似功能的类库。比如常见的数据转换的JSON类库,或者一些常用的工具类。五花八门地嵌套在各式各样的业务代码中,由于各有各的编码习惯,而作为开发通常不应该去信任一个自己没有用过的库,导致会花费一些额外时间去检查底层细节。
方案
这种情况下应该规范在项目中使用的类库,相似功能的库我们应当根据其特性,弱水三千只取一瓢,尽量保持少而实用。
示例
比如关于JSON类库的选择,通常有阿里的FastJSON和Google的Gson可供选择。我们通常根据其特性进行评估:
- FastJSON性能极佳,但复杂对象处理起来需要定制引用类型,比较麻烦。
- Gson处理复杂对象稳定便捷,但性能消耗比FastJSON大。
如果性能满足,且我们要构建一个倾向于外部数据对接的项目,那么Gson是很好的选择。 如果我们要求快速响应,并且项目中并没有很复杂的对象转换,我们考虑使用FastJSON应用即可。
16、合理定义枚举
**不要**在代码中以静态变量或者魔法值的形式直接写死。不定义枚举,会对代码的阅读和维护造成极大困扰。
当涉及不同业务类型的字段诞生时,我们应该为它找一个合适的地方安家,可以参考如下形式:

17、经常重构旧代码
随着时间的推移,业务的增长,有的代码可能不再适用,或者有了更好的设计方式,那么可以及时的重构业务代码。
以多样化的外部数据对接业务为例: 在业务刚开始的时候可能只涉及分发到某一个外部系统,于是我们在代码中直接编写分发的业务逻辑。并且和主业务耦合在一起,但是随着业务的背景不断扩大,我们又需要编写分发给其他外部业务系统的逻辑。
那么此时就可以用策略模式抽象出一个分发接口,主业务流程只依赖于抽象的分发接口。具体实现我们重构原先的代码,并且进行新业务代码的编写。
18、try catch 内部抽象成一个方法
try catch代码有时会干扰我们阅读核心的代码逻辑,这时就可以把try catch内部主逻辑抽离成一个单独的方法。如下图是Eureka服务端源码中服务下线的实现中的一段代码:
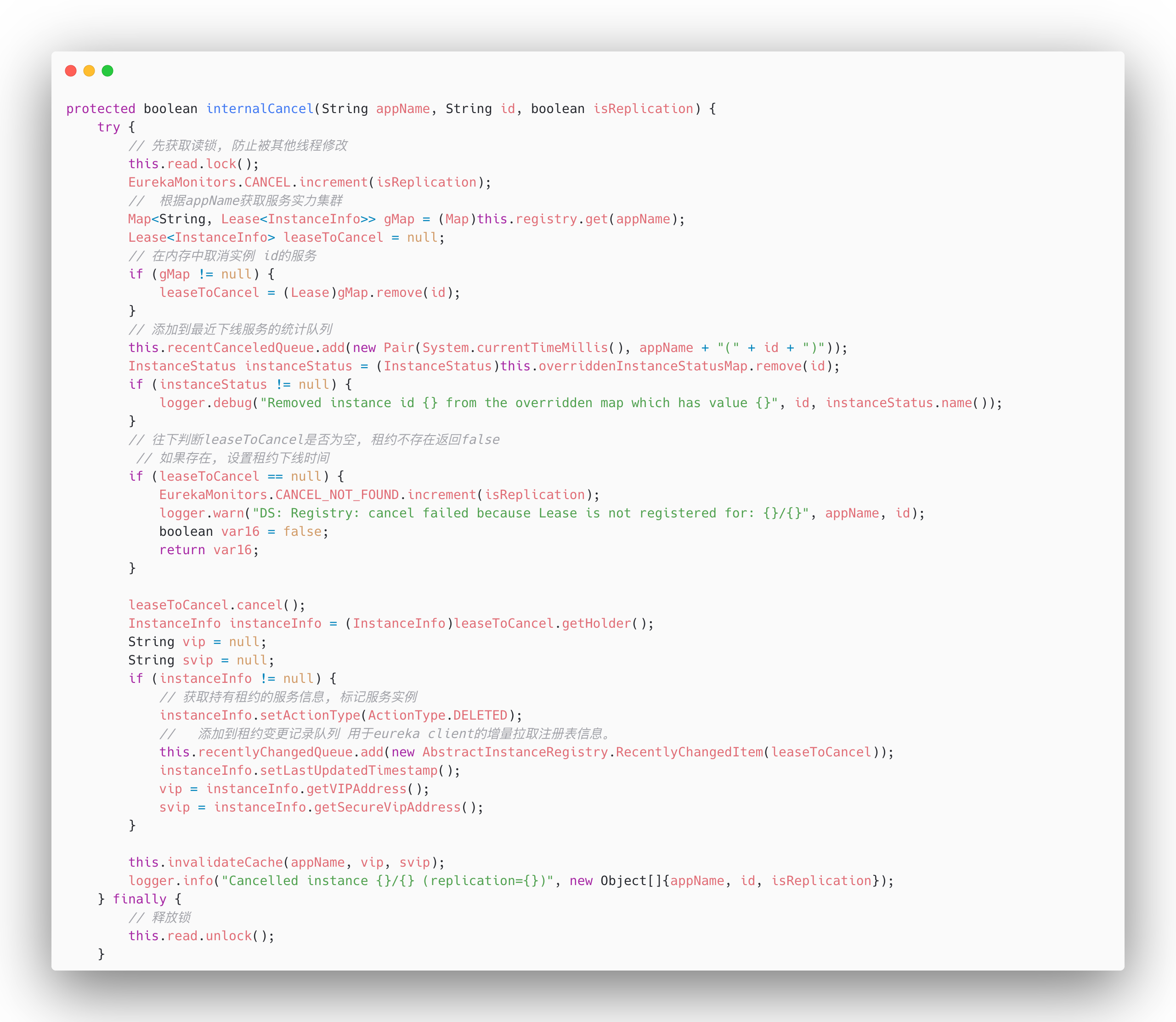
这一段代码还是略微有些致命的,冗长的业务逻辑在try{ }中让人对这里的锁欲罢不能。但是如果我们对其进行一定的抽取,变成下面这样:

这样我们清洗地获知,这里的read锁住的是 **doInternalCancel **方法中的业务,并且最终我们能保证read锁在finnally中得到了释放。
19、魔法值用常量表示
代码中 updateTime、desc、asc等均属于魔法值:

应当抽取到常量中进行保存:

20、远程接口超时机制
微服务之间进行rpc调用的时候,又或者在调用第三方提供的接口的时候,需要设置超时时间,并对调用出错的接口采取降级策略,防止因为各种原因,导致线程”卡死“在那。
21、只Select需要的字段
后端开发编写查询时,不要总是查询全字段。在有些行业中,存在某个字段中的可能是个text或者longblob,但对于某些接口并不需要查询它。如果一把查出来,会极大增加网络传输的负担。同时,不但会导致覆盖索引不生效,也会给数据库增加不必要的开销。
因此,建议使用什么字段查询什么字段,比如SQL中只查需要的接口。或者Wrapper中指定查询字段。

22、不要循环调用数据库
这是常见的导致接口慢的原因之一,对数据库的访问涉及到连接的建立和释放,数据库执行sql以及磁盘I/O等工作。放到循环中做,会极大地影响到查询的效率。
正确的方法应该先批量查出来,然后转成map,最后对数据进行集中处理。
23、避免多表join
如上面代码所示,原本也可以将两张表根据人员的id进行关联查询。但是不推荐这么处理,阿里也有明确禁止多表join的操作。

之所以会**禁用**,是因为join的效率比较低。MySQL是使用了嵌套循环的方式来实现关联查询的,也就是for循环会套for循环的意思。用第一张表做外循环,第二张表做内循环,外循环的每一条记录跟内循环中的记录作比较,符合条件的就输出,这种效率肯定低。
正确地做法是在数据库设计层面尽量将同一业务领域的对象设计到一张表中,并通过缓存的形式将关联数据在内存中进行组装,最终达到单表查库,在代码中进行数据拼接。
另外还有一个比较合适的解决方案,就是**基于Elasticsearch对多表关联查询进行优化**。
24、null值判断
空指针是代码开发中的一个难题,也是一个常见的话题,作为程序员的入门级异常,具有一定工作经验的程序员应该要主动防止空指针的抛出。
NullPointException产生的原因:
- 数据返回对象为null
- 自动拆箱导致空指针
- rpc调用返回的对象可能为空
所以在这些场景下,需要强制判断是否为null。当然也有更优雅的方式:使用Optional来优雅地进行null值判断。比如下面这段代码:

使用Optional进行优化后可以变成下面这样:

25、资源释放写到finally
比如在使用juc工具类或者进行I/O操作的时候,需要主动释放资源,为了能够保证资源能够被真正释放,那么就需要在finally中写代码保证资源释放。


26、使用线程池代替手动创建线程
使用线程池有以下好处:
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统 的稳定性,使用线程池可以进行统一的分配,调优和监控。

所以为了达到更好的利用资源,提高响应速度,我们应该尽量使用线程池的方式来代替手动创建线程。
27、考虑线程安全问题
在实际开发中,需要多考虑业务是否有线程安全、集合读写安全等问题。如果有不得不使用异步的理由,那么必须用线程安全的集合、并且通过同步原语、加锁、volatile、CAS、JUC工具类等手段来保证不会出现线程安全问题。
例如JDK1.8中,ConcurrentHashMap对线程安全的保障就是建立在为Segment加锁和CAS之上的。
if (casTabAt(tab, i, null, new Node<K, V>(hash, key, value, null)))
break;
synchronized (f) {
if (tabAt(tab, i) == f) {
//...
}
}

28、慎用异步
刚刚也提到了,使用多线程的前提是我们有充足的理由并能确保线程安全。但与此同时,也会带来更多的问题。
事务问题
一旦使用了异步,就会导致两个线程不是同一个事务的,导致异常之后无法正常回滚数据。
cpu负载过高
如果在某一时间点,同时开很多线程去跑业务代码,那么可能会导致系统的cpu飙升。所以必须得用线程池去调度。
意想不到的异常
使用异步后,日志打印将变得不再规律,并且如果涉及到调用外部接口,这种场景下一旦发生大量异常,会导致出现很多错误数据。需要谨慎地编排相关的业务逻辑。
虽然说慎用,但是在综合评估后如果能避免以上问题,也是可以使用异步的高性能来加快我们系统的业务处理能力的。
29、减小加锁的粒度
我们应当尽量减少加锁的范围,只给需要加锁的代码上锁。
打个比方
每个人都要上卫生间,人就是不同的线程,卫生间就是资源,你上卫生间要把门锁上吧,这就是加锁。只要你人在里面,这个卫生间就被你锁住了,只有你出来之后别人才能用。有人说,“我上厕所不关门”,那没的说,我们也只能想象一下。 其实也有办法,找个帮你看门的,有人来就让他等,直到你告知看门的说你出来了,再让别的人进去。有如自旋+CAS,借助ComapreAndSwap机器命令实现。
什么是锁的粒度?
其实就是你要加锁的范围,比如你在家上卫生间,你只要锁住卫生间就可以了,不需要将整个家锁住不让别人进来,卫生间就是加锁的粒度。
如何减少加锁的粒度?
其实卫生间并不只用来上厕所,同样也还能洗澡、洗手。我们可以通过拉一个浴帘的方式去实现,你在卫生间里洗澡,别人其实也可以同时进去洗手,也就是将卫生间的使用场景进行隔离。最理想的情况下,马桶、浴缸还有洗手池可以同时给三个人用,只是这三个人做的事都不一样。 这个就是对卫生间使用更细粒度的锁,实现了卫生间资源的最大化使用。
代码例子
比如CopyOnWriteArrayList#addAll方法。

其中:
final ReentrantLock lock = this.lock;
lock.lock();
完全可以放到方法第一行去,但是作者并没有这么做,而是减少了其锁住的代码范围。
因为前面的代码只是一些对象声明、判断,并不存在线程安全问题。这样做减少了锁的范围,可以降低锁争用和占有的时间。
30、合理拷贝对象
开发工作中,经常遇到JavaBean的转换,一个一个set要写不少代码,属实麻烦。所以一般会使用属性拷贝的一些工具,比如说Spring提供的BeanUtils来拷贝。这个工具类底层是通过反射来进行属性拷贝的,对简单且小的对象使用起来非常舒适,但大量的复杂对象会存在性能问题。
所以我们尽量在实际工作中要酌情考虑是否适用使用类似的工具类。
另外几个处理复杂对象拷贝的值得提倡的做法是
- 在编辑器层面使用JavaBean的转换工具类
- 高性能的MapStruct框架
它们的共性是通过getter/setter的方式进行对象复制,而不是通过反射,速度更快并且稳定。
检查
通常为了保证软件的交付质量,一般开发团队都有指定的负责人对组内成员的代码进行审查。结合个人经验,通常从以下几个层面去逐步深入。
注意事项
要有礼貌
审查是为了共同进步,好的代码能帮助审查人学习到新的编码思路。有问题的代码能帮助作者及时修复并提升自身的编码质量,同时也会让审查人进行反思。
不要把代码审查作为展示你高超技术能力的借口,更不要持技凌人。总的来说:
** 要有礼貌:**提供友好的改进建议。
** 要谦虚:**当你的建议只是一个意见,而不是你的交流障碍时,要诚实。
最终能让团队成员能普遍将代码审查视作一次双向学习的机会。
一次不宜过多
每次审查的代码量不要太多,避免反馈同一时间太多,导致对最终结果产生负面影响。当然第一次启动审查的时候,可以根据自身项目情况选择全量审查,今后按小批量审查即可。
解铃还须系铃人
如果在审查中发现问题,务必由原作者进行确认,除非人已经远走高飞了则由当前责任人确认。
这样做有两个目的:
- 确认问题确实存在,保证问题被解决
- 让原作者了解问题和不足,帮助其成长
桌面检查
桌面检查是一种传统的检查方法,也可以成为自查。由程序员自身检查自己编写的程序,自己对源代码进行分析检验并根据相关的文档内容去检验程序汇总是否有错误。 桌面检查应该是质量把控的第一关,有编写代码的人根据一定的标准自行评估检查,如果这一步能够形成一种良好的习惯,后续的工作会省不少心。
代码走查
代码走查也被称为“代码走读”,一般是由开发人员和测试人员进行相互走查。具体做法就是针对代码,在假想的输入情况下,逐行的浏览代码,走查代码中潜在的缺陷,并记录结果的过程。 代码走查通常以小组会议方式进行,每组3-5人。与代码审查不同的是,走查要求与会者扮演计算机的角色让测试用例沿被测程序的逻辑运行,是在模拟动态测试;而代码审查更多的是静态测试。
方法
主要包含14项内容:
- 文档和源程序代码
- 检查项目
- 检查功能
- 检查界面
- 检查流程
- 检查提示信息
- 函数检查
- 数据类型与变量检查
- 条件判断检查
- 循环检查
- 输入输出检查
- 注释检查
- 程序(模块)检查
- 数据库检查。
编译器工具
这里推荐两个自动检查代码质量的编辑器插件,操作方便功能全面,目前也属于比较值得信赖的插件:
FindBugs
FindBugs 是由马里兰大学提供的一款开源 Java 静态代码分析工具。FindBugs 通过检查类文件或 JAR 文件,将字节码与一组缺陷模式进行对比从而发现代码缺陷,完成静态代码分析。FindBugs 既提供可视化 UI 界面,同时也可以作为 IDEA 插件使用。
阿里巴巴P3C代码规范扫描插件
P3C插件是阿里巴巴p3c项目组进行研发。这个项目组是阿里巴巴开发爱好者自发组织形成的虚拟项目组,根据《阿里巴巴Java开发规范》转化而成的自动化插件,并且实现了部分自动编程。
源代码审计
建议使用sonarqube结合scanner对本地源代码进行审查。
SonarQube 是一个开源的代码分析平台, 用来持续分析和评测项目源代码的质量。 通过SonarQube我们可以检测出项目中重复代码, 潜在bug, 代码规范,安全性漏洞等问题, 并通过SonarQube web UI展示出来,通过自带的web系统可查看代码审查的结果,并给出BUG的修改建议。
可以参考一下我的这一篇从部署到应用的博文:本地部署sonarqube并进行代码审查
版权归原作者 豆皮哥 所有, 如有侵权,请联系我们删除。