
Kafka安装配置
安装
kafka官网https://kafka.apache.org/downloads
wget https://archive.apache.org/dist/kafka/2.7.2/kafka_2.12-2.7.2.tgz
tar xf kafka_2.12-2.7.2.tgz -C /usr/local/ #将kafka安装到了**/usr/local**目录下
mv /usr/local/kafka_2.12-2.7.2 /usr/local/kafka #新建存放日志和数据的文件夹
mkdir /usr/local/kafka/logs
配置
afka的主配置文件为/usr/local/kafka/config/server.properties,这里以节点kafkazk1为例,重点介绍一些常用配置项的含义:
broker.id=1
port=19092 #当前kafka对外提供服务的端口默认是9092
host.name=10.0.0.6 #这个参数默认是关闭的,在0.8.1有个bug,DNS解析问题,失败率的问题。
listeners=PLAINTEXT://10.0.0.6:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400 #发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能
socket.receive.buffer.bytes=102400 #kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
socket.request.max.bytes=104857600 #这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小
log.dirs=/usr/local/kafka/logs
#消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个
num.partitions=6 #默认的分区数,一个topic默认1个分区数
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
default.replication.factor=2 #kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务
message.max.byte=5242880 #消息保存的最大值5M
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
replica.fetch.max.bytes=5242880 #取消息的最大直接数
log.retention.hours=168 #默认消息的最大持久化时间,168小时,7天
log.segment.bytes=1073741824 #这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件
log.retention.check.interval.ms=300000 #每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除
log.cleaner.enable=false #是否启用log压缩,一般不用启用,启用的话可以提高性能
log.segment.bytes=1073741824 #这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件
zookeeper.connect=localhost:2181 #不是集群,所以可以写成localhost
#zookeeper.connect=10.0.0.6:2181,10.0.0.7:2181,10.0.0.8:2181 #集群
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0 auto.create.topics.enable=true
delete.topic.enable=true
每个配置项含义如下:
broker.id:每一个broker在集群中的唯一表示,要求是正数。当该服务器的IP地址发生改变时,broker.id没有变化,则不会影响consumers的消息情况。listeners:设置kafka的监听地址与端口,可以将监听地址设置为主机名或IP地址,这里将监听地址设置为IP地址。log.dirs:这个参数用于配置kafka保存数据的位置,kafka中所有的消息都会存在这个目录下。可以通过逗号来指定多个路径, kafka会根据最少被使用的原则选择目录分配新的parition。需要注意的是,kafka在分配parition的时候选择的规则不是按照磁盘的空间大小来定的,而是根据分配的 parition的个数多小而定。num.partitions:这个参数用于设置新创建的topic有多少个分区,可以根据消费者实际情况配置,配置过小会影响消费性能。这里配置6个。log.retention.hours:这个参数用于配置kafka中消息保存的时间,还支持log.retention.minutes和 log.retention.ms配置项。这三个参数都会控制删除过期数据的时间,推荐使用log.retention.ms。如果多个同时设置,那么会选择最小的那个。log.segment.bytes:配置partition中每个segment数据文件的大小,默认是1GB,超过这个大小会自动创建一个新的segment file。zookeeper.connect:这个参数用于指定zookeeper所在的地址,它存储了broker的元信息。 这个值可以通过逗号设置多个值,每个值的格式均为:hostname:port/path,每个部分的含义如下: - hostname:表示zookeeper服务器的主机名或者IP地址,这里设置为IP地址。- port: 表示是zookeeper服务器监听连接的端口号。- /path:表示kafka在zookeeper上的根目录。如果不设置,会使用根目录。auto.create.topics.enable:这个参数用于设置是否自动创建topic,如果请求一个topic时发现还没有创建, kafka会在broker上自动创建一个topic,如果需要严格的控制topic的创建,那么可以设置auto.create.topics.enable为false,禁止自动创建topic。delete.topic.enable:在0.8.2版本之后,Kafka提供了删除topic的功能,但是默认并不会直接将topic数据物理删除。如果要从物理上删除(即删除topic后,数据文件也会一同删除),就需要设置此配置项为true。
设置环境变量
$ vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
#生效
$ . /etc/profile
启动脚本
$ vim /usr/lib/systemd/system/kafka.service
[Unit]
Description=Apache Kafka server (broker)
After=network.target zookeeper.service
[Service]
Type=simple
User=root
Group=root
ExecStart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties
ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh
Restart=on-failure
[Install]
WantedBy=multi-user.target
$ systemctl daemon-reload
启动kafka
在启动kafka集群前,需要确保ZooKeeper集群已经正常启动。接着,依次在kafka各个节点上执行如下命令即可。这里将kafka放到后台运行,启动后,会在启动kafka的当前目录下生成一个nohup.out文件,可通过此文件查看kafka的启动和运行状态。通过jps指令,可以看到有个Kafka标识,这是kafka进程成功启动的标志。
$ cd /usr/local/kafka
$ nohup bin/kafka-server-start.sh config/server.properties &
# 或者
$ systemctl start kafka
$ jps
21840 Kafka
15593 Jps
15789 QuorumPeerMain
Kafka相关知识
下图展示了Kafka的相关术语以及之间的关系:
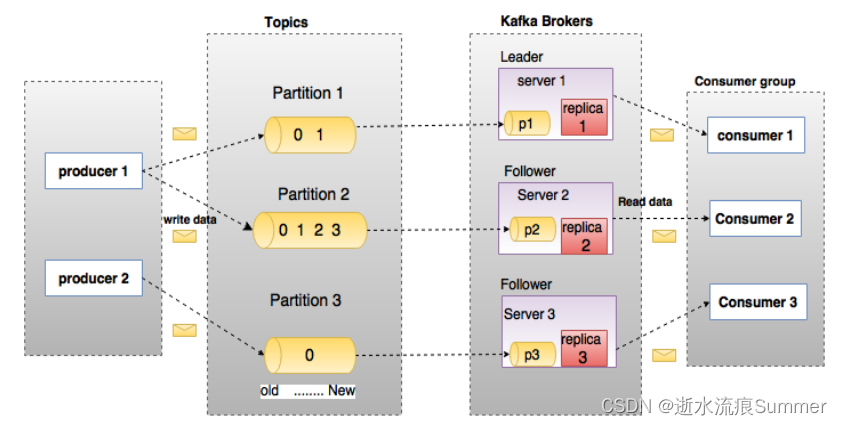
上图中一个topic配置了3个partition。Partition1有两个offset:0和1。Partition2有4个offset。Partition3有1个offset。副本的id和副本所在的机器的id恰好相同。
如果一个topic的副本数为3,那么Kafka将在集群中为每个partition创建3个相同的副本。集群中的每个broker存储一个或多个partition。多个producer和consumer可同时生产和消费数据。
broker
Kafka 集群包含一个或多个服务器,服务器节点称为broker。
broker存储topic的数据。如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
类似于数据库的表名
Partition
topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
Producer
生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
Consumer
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
Leader
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
Follower
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
相关参考链接:Kafka详解(包括kafka集群搭建)-CSDN博客
https://www.cnblogs.com/duanxz/p/4492870.html
Java kakfa配置application.yml
spring:
kafka:
bootstrap-servers: 10.0.0.6:9092
producer:
acks: all
retries: 0
batch-size: 16384
buffer-memory: 33554432
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
properties:
linger.ms: 1
pom.xml依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-kafka</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.integration</groupId>
<artifactId>spring-integration-kafka</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.integration</groupId>
<artifactId>spring-integration-kafka</artifactId>
<version>${spring-integration.version}</version><!--$NO-MVN-MAN-VER$ -->
</dependency>
**发送kafka消息工具类实现 **
package com.test.util;
/*发送kafka消息工具类*/
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import com.test.common.util.JsonUtil;
import lombok.extern.slf4j.Slf4j;
@Slf4j
@Component
@EnableKafka
public class KafkaSender {
@Autowired(required = false)
private KafkaTemplate<String, Object> template;
@Value("${kafka.debug:true}")
private boolean kafka_send_debug;
public void sendMsgAsyncAndLog(String topic, Object msg) {
if (kafka_send_debug) {
log.info("sendMsgAsyncAndLog to {} msg: {}", topic, JsonUtil.objToStr(msg));
}
sendMsgAsync(topic, msg, new ListenableFutureCallback<SendResult<String, Object>>() {
@Override
public void onSuccess(SendResult<String, Object> result) {
log.info("sendMsgAysnc suc! msg:{}", msg);
}
@Override
public void onFailure(Throwable ex) {
log.error(ex.getMessage(), ex);
log.error("sendMsgAysnc error! msg:{}", msg);
}
});
}
public void sendMsgAsync(String topic, Object msg, ListenableFutureCallback<SendResult<String, Object>> callback) {
if (this.template != null) {
ListenableFuture<SendResult<String, Object>> future = this.template.send(topic, msg);
future.addCallback(callback);
}
}
}
监听topic并消费示例
package com.receive.test.listener;
/*监听kafka topic消息并消费*/
import java.util.Optional;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import com.test.route.RouteDeal;
import lombok.extern.slf4j.Slf4j;
@Slf4j
@Component
public class TestKafkaListener {
@Autowired
private RouteDeal routeDeal;
@KafkaListener(topics = { "topic.test_topic" })
public void kakfaListenerDeal(ConsumerRecord<?, String> record) {
try {
Optional<String> kafkaMessage = Optional.ofNullable(record.value());
if (kafkaMessage.isPresent()) {
String message = kafkaMessage.get();
if (Boolean.getBoolean("debug_log")) {
log.info("receive log: {}", message);
}
routeDeal.putEle(message);
}
} catch (Exception e) {
log.error(e.getMessage(), e);
}
}
}
Kafka调试
kefka提供了多个命令用于查看、创建、修改、删除topic信息,也可以通过命令测试如何生产消息、消费消息等,这些命令位于kafka安装目录的bin目录下,这里是**/usr/local/kafka/bin,**包括createKafkaOnly.sh createKafka.sh deleteKafka.sh 创建与删除topic。
登录任意一台kafka集群节点,切换到此目录下,即可进行命令操作。
下面列举kafka的一些常用命令的使用方法。
(1)显示topic列表
#kafka-topics.sh --zookeeper 10.0.0.6:2181,10.0.0.7:2181,10.0.0.8:2181 --list
$ kafka-topics.sh --zookeeper 10.0.0.6:2181 --list
topic123
(2)创建一个topic,并指定topic属性(副本数、分区数等)
#kafka-topics.sh --create --zookeeper 10.0.0.6:2181,10.0.0.7:2181,10.0.0.8:2181 --replication-factor 1 --partitions 3 --topic topic123
$ kafka-topics.sh --create --zookeeper 10.0.0.6:2181 --replication-factor 1 --partitions 3 --topic topic123
Created topic topic123.
#--replication-factor表示指定副本的个数
(3)查看某个topic的状态
#kafka-topics.sh --describe --zookeeper 10.0.0.6:2181,10.0.0.7:2181,10.0.0.8:2181 --topic topic123
$ kafka-topics.sh --describe --zookeeper 10.0.0.6:2181 --topic topic123
Topic: topic123 PartitionCount: 3 ReplicationFactor: 1 Configs:
Topic: topic123 Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: topic123 Partition: 1 Leader: 1 Replicas: 1 Isr: 1
Topic: topic123 Partition: 2 Leader: 1 Replicas: 1 Isr: 1
(4)生产消息 阻塞状态
#kafka-console-producer.sh --broker-list 10.0.0.6:9092,10.0.0.7:9092,10.0.0.8:9092 --topic topic123
$ kafka-console-producer.sh --broker-list 10.0.0.6:9092 --topic topic123
(5)消费消息 阻塞状态
#kafka-console-consumer.sh --bootstrap-server 10.0.0.6:9092,10.0.0.7:9092,10.0.0.8:9092 --topic topic123
$ kafka-console-consumer.sh --bootstrap-server 10.0.0.6:9092 --topic topic123
#从头开始消费消息
#kafka-console-consumer.sh --bootstrap-server 10.0.0.6:9092 --topic topic123 --from-beginning
$ kafka-console-consumer.sh --bootstrap-server 10.0.0.6:9092,10.0.0.7:9092,10.0.0.8:9092 --topic topic123 --from-beginning
(6)删除topic
#kafka-topics.sh --delete --zookeeper 10.0.0.6:2181,10.0.0.7:2181,10.0.0.8:2181 --topic topic123
$ kafka-topics.sh --delete --zookeeper 10.0.0.6:2181 --topic topic123
(7)其他
#kafka查看topic里n条消息
sh kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic_name --from-beginning --max-messages n
#模拟发送数据
/home/kafka/software/kafka/bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic topic_name
#消费数据
/home/kafka/software/kafka/bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic topic_name --from-beginning
#查看topic列表
/home/kafka/software/kafka/bin/kafka-topics.sh --list --zookeeper localhost:2181
kafka启动常见问题

1.端口被占用Socket server failed to bind to 0.0.0.0:9092: Address already in use.
解决办法:netstat -nltp | grep 9092 找到并kill掉对应的进程,重新启动kafka进程。
2.配置文件错误,如示例将log.retention.hours的值配置成了字母,实际应该是数值类型,导致kafka无法启动
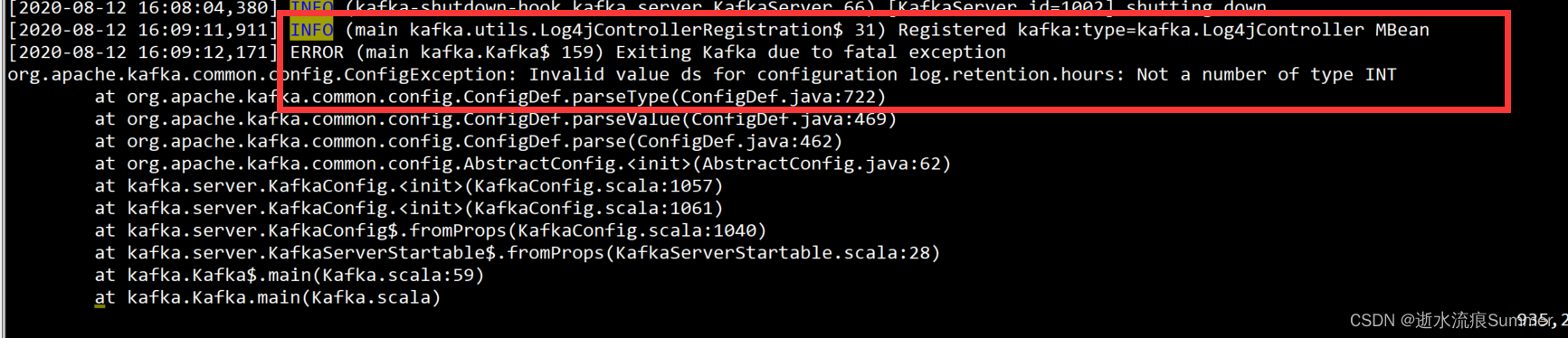
解决办法:修改错误的配置,重新启动kafka进程
3.节点已注册
从kafka的server.log日志中发现如下信息,这种方式一般是因为磁盘问题,回想下是否进行过磁盘的重分配,将原来其它节点的磁盘,分配给了现在的节点,这种现象一般发生在单机版kafka多broker节点的场景
此时如果将磁盘分配还原成最开始的分配方式并启动kafka进程后,会出现下面第二张图的问题,出现了同一个kafka主题分区有两个目录的情况
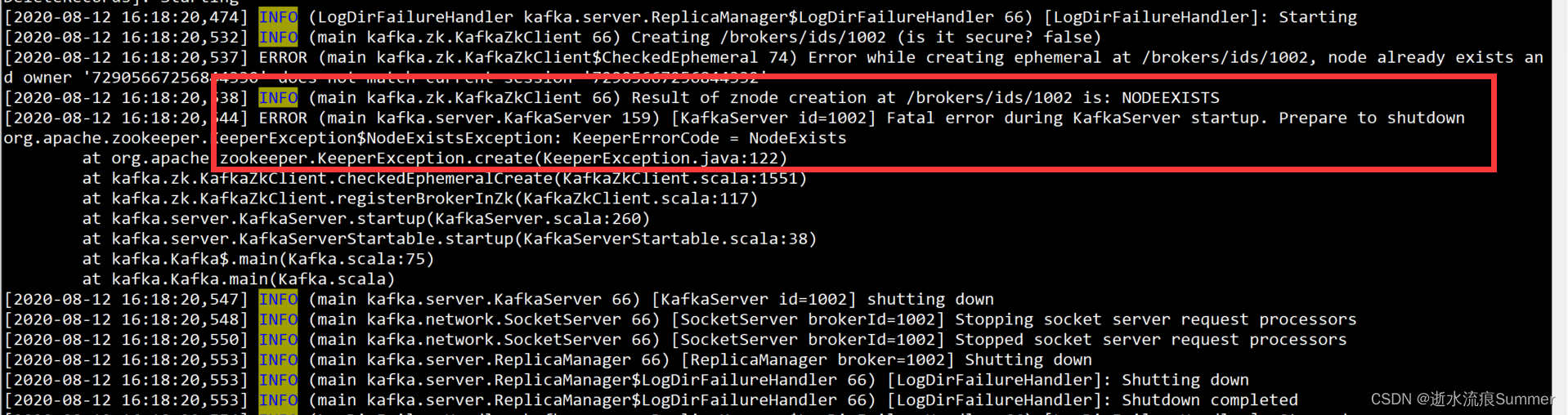
解决办法:如果是初次部署,还没有流量进来,先卸载kafka节点,再重新部署;
其它情况,先停kafka服务,删除两个相同的目录中的一个,只保留其中一个目录即可,然后重启kafka进程
4. 当日志出现类似于这样的ERROR信息时,可能是出现了脏副本
Exiting because log truncation is not allowed for partition test01-1, current leader's latest offset 28025 is less than replica's latest offset 28402
出现这样的错误信息后,kafka启动会失败,这时,server.properties文件中添加参数unclean.leader.election.enable=true,启动kafka服务即可以启动
5. 当出现下面的报错时,需要检查目录的权限
FATAL Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server.KafkaServer) java.io.IOException: Permission denied
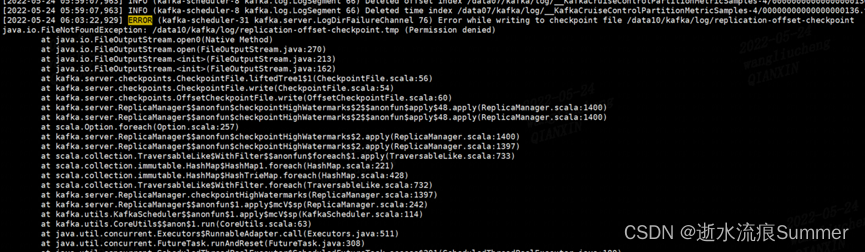
6. 当出现下面的报错时,需要检查磁盘问题
org.apache.kafka.common.KafkaException: java.io.IOException: Input/output error
版权归原作者 逝水流痕Summer 所有, 如有侵权,请联系我们删除。