

长短期记忆是复杂和先进的神经网络结构的重要组成部分。本文的主要思想是解释其背后的数学原理,所以阅读本文之前,建议首先对LSTM有一些了解。
介绍

上面是单个LSTM单元的图表。我知道它看起来可怕😰,但我们会通过一个接一个的文章,希望它会很清楚。
解释
基本上一个LSTM单元有4个不同的组件。忘记门、输入门、输出门和单元状态。我们将首先简要讨论这些部分的使用,然后深入讨论数学部分。
忘记门
顾名思义,这部分负责决定在最后一步中扔掉或保留哪些信息。这是由第一个s型层完成的。
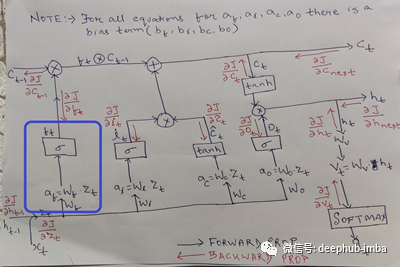
根据h_t-1(以前的隐藏状态)和x_t(时间步长t的当前输入),它为单元格状态C_t-1中的每个值确定一个介于0到1之间的值。

遗忘门和上一个状态
如果为1,所有的信息保持原样,如果为0,所有的信息都被丢弃,对于其他的值,它决定有多少来自前一个状态的信息被带入下一个状态。
输入门
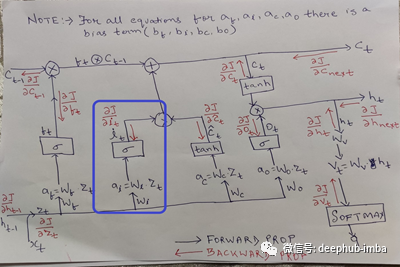
Christopher Olah博客的解释在输入门发生了什么:
下一步是决定在单元格状态中存储什么新信息。这包括两部分。首先,一个称为“输入门层”的sigmoid层决定我们将更新哪些值。接下来,一个tanh层创建一个新的候选值的向量,C~t,可以添加到状态中。在下一步中,我们将结合这两者来创建对状态的更新。
现在这两个值i。e i_t和c~t结合决定什么新的输入是被输入到状态。
单元状态
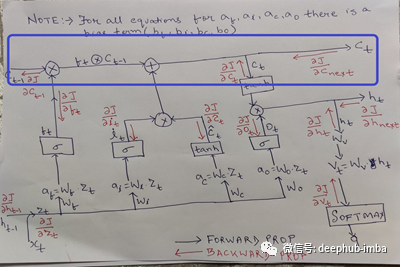
单元状态充当LSTM的内存。这就是它们在处理较长的输入序列时比普通RNN表现得更好的地方。在每一个时间步长,前一个单元状态(C_t-1)与遗忘门结合,以决定什么信息要被传送,然后与输入门(i_t和c~t)结合,形成新的单元状态或单元的新存储器。

状态的计算公式
输出门
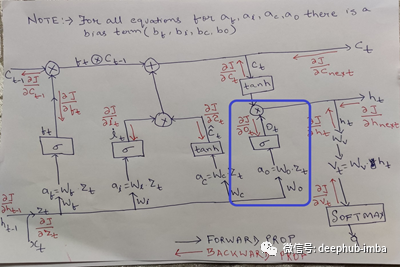
最后,LSTM单元必须给出一些输出。从上面得到的单元状态通过一个叫做tanh的双曲函数,因此单元状态值在-1和1之间过滤。
LSTM单元的基本单元结构已经介绍完成,继续推导在实现中使用的方程。
推导先决条件
推导方程的核心概念是基于反向传播、成本函数和损失。除此以外还假设您对高中微积分(计算导数和规则)有基本的了解。
变量:对于每个门,我们有一组权重和偏差,表示为:
- W_f,b_f->遗忘门的权重和偏差
- W_i,b_i->输入门的权重和偏差
- W_c,b_c->单元状态的权重和偏差
- W_o,b_o->输出门的权重和偏差
- W_v ,b_v -> 与Softmax层相关的权重和偏差
- f_t, i_t,c_tilede_t, o_t -> 输出使用的激活函数
- a_f, a_i, a_c, a_o -> 激活函数的输入
J是成本函数,我们将根据它计算导数。注意(下划线(_)后面的字符是下标)
前向传播推导
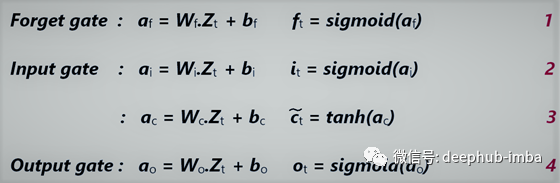
门的计算公式
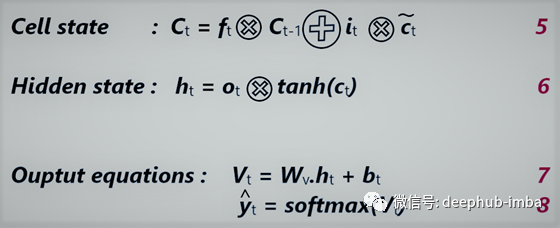
状态的计算公式
以遗忘门为例说明导数的计算。我们需要遵循下图中红色箭头的路径。

我们画出一条从f_t到代价函数J的路径,也就是
f_t→C_t→h_t→J。
反向传播完全发生在相同的步骤中,但是是反向的
f_t←C_t←h_t←J。
J对h_t求导,h_t对C_t求导,C_t对f_t求导。
所以如果我们在这里观察,J和h_t是单元格的最后一步,如果我们计算dJ/dh_t,那么它可以用于像dJ/dC_t这样的计算,因为:
dJ/dC_t = dJ/dh_t * dh_t/dC_t(链式法则)
同样,对第一点提到的所有变量的导数也要计算。
现在我们已经准备好了变量并且清楚了前向传播的公式,现在是时候通过反向传播来推导导数了。我们将从输出方程开始因为我们看到在其他方程中也使用了同样的导数。这时就要用到链式法则了。我们现在开始吧。
反向传播推导
lstm的输出有两个值需要计算。
Softmax:对于交叉熵损失的导数,我们将直接使用最终的方程。
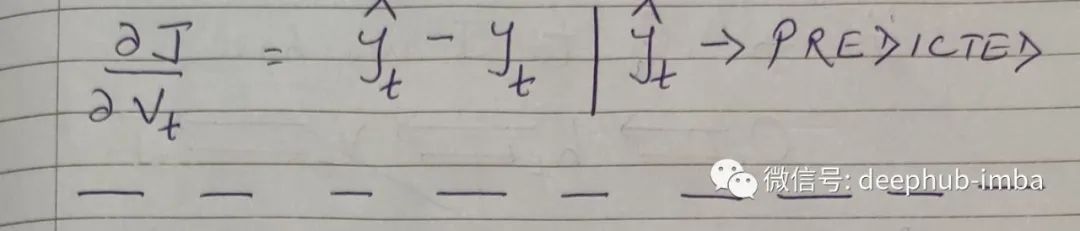
隐藏状态是h_t。h_t是w.r的微分。根据链式法则,推导过程如下图所示。

输出门相关变量:a_o和o_t,微分的完整方程如下:
dJ/dV_t * dV_t/dh_t * dh_t/dO_t
dJ/dV_t * dV_t/dh_t可以写成dJ/dh_t(我们从隐藏状态得到这个值)。
h_t的值= o_t * tanh(c_t) ->所以我们只需要对h_t w.r求导。t o_t。其区别如下:

同样,a_o和J之间的路径也显示出来。微分的完整方程如下:
dJ/dV_t * dV_t/dh_t * d_t /da_o
dJ/dV_t * dV_t/dh_t * dh_t/dO_t可以写成dJ/dO_t(我们从上面的o_t得到这个值)。

C_t是单元的单元状态。除此之外,我们还处理候选单元格状态a_c和c~_t。
C_t的推导很简单,因为从C_t到J的路径很简单。C_t→h_t→V_t→j,因为我们已经有了dJ/dh_t,我们直接微分h_t w.r。t C_t。
h_t = o_t * tanh(c_t) ->所以我们只需要对h_t w.r求导。t C_t。

微分的完整方程如下:
dJ/dh_t * dh_t/dC_t * dC_t/dc~_t
可以将dJ/dh_t * dh_t/dC_t写成dJ/dC_t(我们在上面有这个值)。
C_t的值如图9公式5所示(下图第3行最后一个C_t缺少波浪号(~)符号->书写错误)。所以我们只需要对C_t w.r求导。t c ~ _t。

a_c:如下图所示为a_c到J的路径。根据箭头,微分的完整方程如下:
dJ/dh_t * dh_t/dC_t * dC_t/ da_c
dJ/dh_t * dh_t/dC_t * dC_t/dc_t可以写成dJ/dc_t(我们在上面有这个值)。
所以我们只需要对c~_t w.r求导。t a_c。

输入门相关变量:i_t和a_i
微分的完整方程如下:
d_t / d_t * d_t /di_t
可以将dJ/dh_t * dh_t/dC_t写入为dJ/dC_t(我们在单元格状态中有这个值)。所以我们只需要对C_t w.r求导。t i_t。

a_i:微分的完整方程如下:
dJ/dh_t * dh_t/dC_t * d_t /da_i
dJ/dh_t * dh_t/dC_t * dC_t/di_t可以写成dJ/di_t(我们在上面有这个值)。所以我们只需要对i_t w.r求导。t ai。

遗忘门相关变量:f_t和a_f
微分的完整方程如下:
dJ/dh_t * dh_t/dC_t * dC_t/df_t
可以将dJ/dh_t * dh_t/dC_t写入为dJ/dC_t(我们在单元格状态中有这个值)。所以我们只需要对C_t w.r求导。t f_t。

a_f:微分的完整方程如下:
dJ/dh_t * dh_t/dC_t * df_t/da_t
dJ/dh_t * dh_t/dC_t * dC_t/df_t可以写成dJ/df_t(我们在上面有这个值)。所以我们只需要对f_tw.r求导。t a_f。

Lstm的输入
每个单元格i有两个与输入相关的变量。前一个单元格状态C_t-1和前一个隐藏状态与当前输入连接,即
[h_t-1,x_t] > Z_t
C_t-1:这是Lstm单元的内存。图5显示了单元格状态。c - t-1的推导很简单因为只有c - t和c - t。

Z_t:如下图所示,Z_t进入四个不同的路径,a_f,a_i,a_o,a_c。
Z_t→a_f→f_t→C_t→h_t→J。- >遗忘门
Z_t→a_i→i_t→C_t→h_t→J。- >输入门
Z_t→a_c→c~_t→C_t→h_t→J。->单元状态
Z_t→a_o→o_t→C_t→h_t→J。- >输出门

权重和偏差
W和b的推导很简单。下面的推导是针对Lstm的输出门的。对于其余的门,对权重和偏差也进行了类似的处理。


输入和遗忘门的权重和偏差


输出和输出门的权重和偏差
J/d_W_f = dJ/da_f。da_f / d_W_f ->遗忘门
dJ/d_W_i = dJ/da_i。da_i / d_W_i ->输入门
dJ/d_W_v = dJ/dV_tdV_t/ d_W_v ->输出门
dJ/d_W_o = dJ/da_o。da_o / d_W_o ->输出门
我们完成了所有的推导。但是有两点需要强调
到目前为止,我们所做的只是一个时间步长。现在我们要让它只进行一次迭代。
所以如果我们有总共T个时间步长,那么每一个时间步长的梯度会在T个时间步长结束时相加,所以每次迭代结束时的累积梯度为:

每次迭代结束时的累积梯度用来更新权重

总结
LSTM是非常复杂的结构,但它们工作得非常好。具有这种特性的RNN主要有两种类型:LSTM和GRU。
训练LSTMs也是一项棘手的任务,因为有许多超参数,而正确地组合通常是一项困难的任务。
作者:Rahuljha
deephub翻译组
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********