
1 案例描述
当大家想了解某个学校相关的就业招聘等信息时,一般的操作都是先进入学校的官网,找到我们需要的关键字点击进入浏览,每个学校的信息不一样,数据也是相当多。于是我也想知道本校的就业服务相关信息,接下来我就用所学的爬虫知识以我们学校为案例完成这个项目。这也是我第一次发文,肯定不完美,希望大家多多鼓励,我会继续努力的,以后也会在这里和你们一起学习。
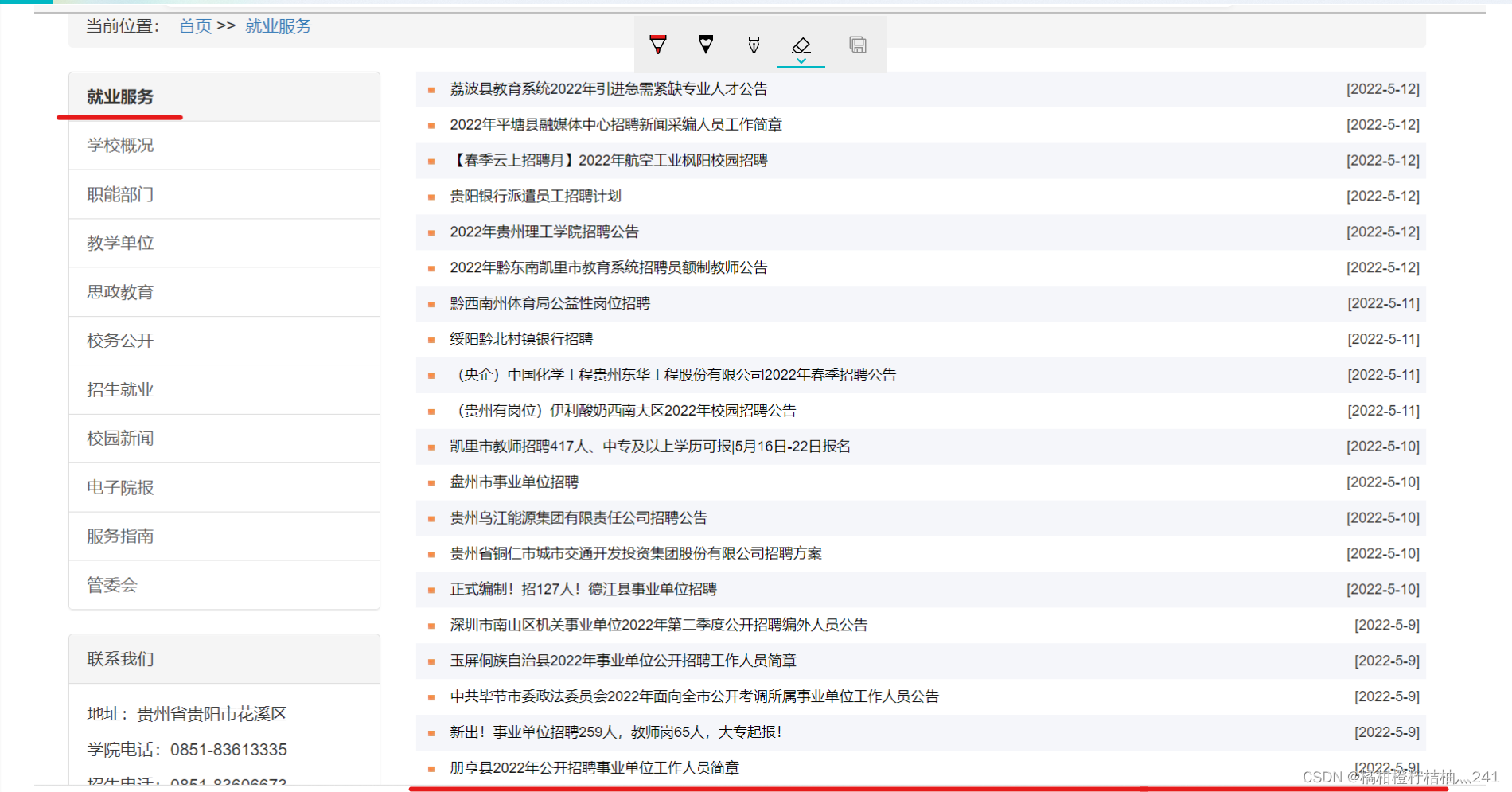
这是我想要得到的数据
2 爬虫
2.1 爬虫的概念
又称网络蜘蛛,就是通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程。
2.2 爬虫的工作原理
爬虫的四个步骤:
(1)获取数据:爬虫程序会根据我们提供的网址,向服务器发起请求,然后给予相应的数据;
(2) 解析数据:爬虫程序会把服务器返回的数据解析成我们能读懂的格式;
(3)提取数据:爬虫程序从中再次提取出我们需要的数据;
(4)储存数据:爬虫程序会把我们最终需要的数据保存或下载下来;
2.3 爬虫的基本流程
(1) 请求网页: 通过 HTTP 库向目标网站发起请求,即发送一个 Request,请求可以包含额外的 headers 等信息,等待服务器响应!
(2) 获得相应内容: 如果服务器能正常响应,会得到一个 Response,Response 的内容便是所要获取的页面内容,类型可能有 HTML,Json 字符串,二进制数据(如图片视频)等类型。
(3) 解析内容: 得到的内容可能是 HTML,可以用正则表达式、网页解析库进行解析。可能是 Json,可以直接转为 Json 对象解析,可能是二进制数据,可以做保存或者进一步的处理。
(4) 存储解析的数据: 数据存储格式有很多,可以存为txt,csv,excel或者直接存为数据库。
3 基本操作
3.1 安装第三方库
Python有很多第三方库,包括我们使用的爬虫、数据分析,还有机器学习之类,Python提供的安装方式多种多样,常用语法为 pip install 库名,或者也可以把第三方库下载到本地,然后安装到如下所示(python文件夹)目录:
下图以jieba安装为例
 ****图1 安装到文件夹 ****
****图1 安装到文件夹 ****
注:此处是python的库存储位置(当pip安装失败(在引用中显示没有该模块)时,可以尝试使用此法)
引用:
 图2 查看安装成功
图2 查看安装成功
安装成功。这样,就可以安装我们所要用到的库。
3.2 库的作用及其使用
此次实战我们需要用到的第三方库有:
# 导入相关模块
from selenium import webdriver
import time
from lxml import etree
import pandas as pd
(1)selenium库作用:用来操控浏览器,模拟人自动化做一些行为动作,主要因为测试直接运行在浏览器中,就可以像用户平常的在操作一样,支持多种浏览器。
selenium库的使用:
from selenium import webdriver # 导入库
br = webdriver.浏览器(传入浏览器的驱动程序) # 声明浏览器
实例化一个浏览器,这样就可以打开一个浏览器对象
br.get("") #引号里面放入你想要打开的网站地址
让浏览器发起一个指定url对应请求
(2)time模块的作用:是系统中自带的模块,让程序暂停执行指定的秒数,适当停留,有一个休眠的过程,看爬取效果。
time模块的使用:
import time # 导包
time.sleep(2) # 让程序睡2秒
每一步操作都可以使用time模块,让模拟更真实
(3)lxml库的作用:解析和提取XML和HTML中的数据,支持Xpath解析方式,利用语法,来定位特定元素及节点信息,效率很高。
lxml库的使用:
from lxml import etree #导入Xpath(将html中的数据进行提取)
tree = etree.HTML(page_text) #实例化一个对象,接收传入的页面源码数据
txt=tree.xpath("") #获取标签
获取标签有两种方法,绝对路径和相对路径。
(4)pandas库的作用:基于numpy的一种工具,为解决数据分析任务而创建的,可以处理csv,excel,html文本等文件。
pandas库的使用:
import pandas as pd #导入已经安装的包
pd.Series(data,index=index,dtype=dtype) #series对象的创建
data:数据,可以是列表,字典或Numpy数组
index:索引,为可选参数
dtype: 数据类型(支持多种类型),为可选参数
import numpy as np
用一维数组创建
dic = {"key1":value1,
"key2":value2,
.....}
fal = pd.Series(dic)
用字典创建,默认以键为index值为data
pd.DataFrame(data,index=index,columns=columns)
data:数据,可以是列表,字典或Numpy数组
index:索引,为可选参数
columns: 列标签,为可选参数
知识当然是无止境的呀,所以小菜鸟所展示的也只是冰山一角,还有很多需要补充的哦。
4 Python代码实现
# 导入相关模块
from selenium import webdriver
import time
from lxml import etree
import pandas as pd
# 定义两个列表,一个存信息,一个存时间
list1=[]
list2=[]
# 封装
def gettxt(page_text):
# 解析数据
tree=etree.HTML(page_text)
# 遍历第一页的信息
for i in range(1,21):
#获取第一页所有招聘信息
txt=tree.xpath('/html/body/div/div[5]/div[2]/ul/li['+str(i)+']/span[1]/a/text()')
#获取第一页所有招聘信息的时间
txt1=tree.xpath('/html/body/div/div[5]/div[2]/ul/li['+str(i)+']/span[2]/text()')
# 列表转字符串,使用str()强转会把[]转进去,所以使用join
txt = "".join(txt)
#替换转义字符
for i in "\t\n":
txt=txt.replace(i,"")
# 使用空列表添加值
list1.append(txt)
list2.append("".join(txt1))
# 利用驱动打开一个网页
bro=webdriver.Edge(executable_path="D:\\vs code\\项目\\msedgedriver")
# 访问页面页数,每次访问一页
for i in range(1,90):
# 向网站发起请求
bro.get("http://www.gzmdrw.cn/rw/welcome/1288759137383718")
# 用page_text属性获取当前页面所对应的源码数据
page_text=bro.page_source
gettxt(page_text)
#字典
data={'信息':list1,'时间':list2}
#DataFrame()函数将字典转换
df=pd.DataFrame(data)
# 存储格式为csv并保存在本地
df.to_csv("就业数据.csv")
# 休眠
time.sleep(2)
#爬取结束退出
bro.quit
得到的运行结果

格式化后的效果

版权归原作者 @橘柑橙柠桔柚 所有, 如有侵权,请联系我们删除。