
1、理论基础
算法本质与背景
层次化(Hierarchial)Softmax算法是在深度学习领域中解决大规模词嵌入训练效率问题的重要突破。该算法通过引入Huffman树结构,有效地将传统Softmax的计算复杂度从线性降至对数级别,从而在处理大规模词汇表时表现出显著的优势。
在传统的神经网络词嵌入模型中,Softmax函数扮演着将任意实数向量转换为概率分布的关键角色。其基本形式可表述为:
给定分数向量 z =[*z_1,*z_2,…,zn],类别 i 的概率计算公式为:
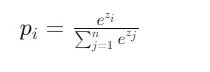
这种计算方式在处理大规模词汇表时面临着严重的计算瓶颈。当词汇表规模达到百万级别时,每次预测都需要计算整个词汇表的概率分布,这在实际应用中是难以接受的。
算法核心思想
层次化Softmax的核心创新在于利用Huffman树的层次结构重新组织词汇表。这种结构不仅保留了词频信息,还通过树的层次关系降低了计算复杂度。在Huffman树中,高频词被安排在较浅的层次,低频词则位于较深的层次,这种结构特性使得模型能够根据词频自适应地分配计算资源。
算法将原本的多分类问题转化为一系列二分类问题。在预测过程中,模型沿着Huffman树的路径进行概率计算,每个内部节点都代表一个二元分类器。这种转化使得预测单个词的计算复杂度从O(|V|)降低到O(log|V|),其中|V|为词汇表大小。
从理论角度来看,层次化Softmax具有两个重要特性。首先,它保持了概率分布的性质,即所有词的概率之和为1。其次,它通过Huffman编码隐含地保留了词频信息,这种特性使得模型能够在训练过程中自动调整对不同词的关注度。
但这种优化也带来了一定的局限性。Huffman树一旦构建完成,其结构就相对固定,这使得模型难以应对动态变化的词汇表。另外由于树的层次结构,低频词的训练效果可能受到影响,这需要在实际应用中通过其他技术手段来补充。
理论意义
层次化Softmax的理论贡献不仅限于计算效率的提升,更重要的是它为处理大规模离散分布问题提供了一个新的思路。这种将离散空间组织为层次结构的方法,为自然语言处理领域的其他任务提供了借鉴。同时其在计算效率与模型精度之间取得的平衡,也为深度学习模型的优化提供了重要参考。
在本文中,我们将详细探讨层次化Softmax的具体实现机制和工程实践方案。这些内容将帮助读者更深入地理解该算法的应用价值和实现细节。
2、算法实现
Huffman树构建算法
Huffman树的构建是层次化Softmax实现的基础,其构建过程需要确保频率高的词获得较短的编码路径。下面通过一个具体示例详细说明构建过程。
初始数据
示例词汇表及其频率分布:
TF-IDF: 3 | hot: 12 | kolkata: 7 | Traffic: 22
AI: 10 | ML: 14 | NLP: 18 | vec: 3
构建步骤
初始节点合并
- 合并最低频率节点:"TF-IDF"(3)和"vec"(3)
- 形成频率为6的子树
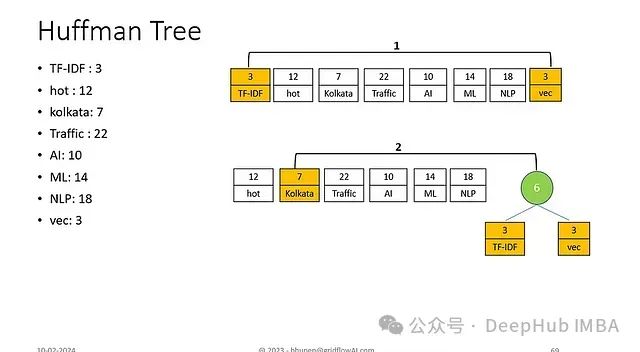
子树扩展
- 合并"kolkata"(7)与已有子树(6)
- 形成频率为13的新子树
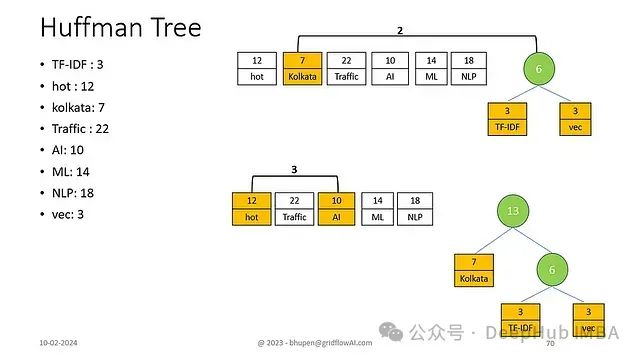
中频节点合并
- 合并"AI"(10)与"hot"(12)
- 形成频率为22的子树
子树整合
- 合并频率13的子树与"ML"(14)
- 形成频率为27的更大子树
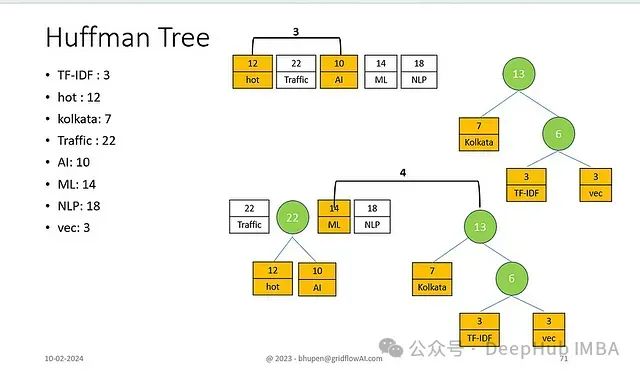
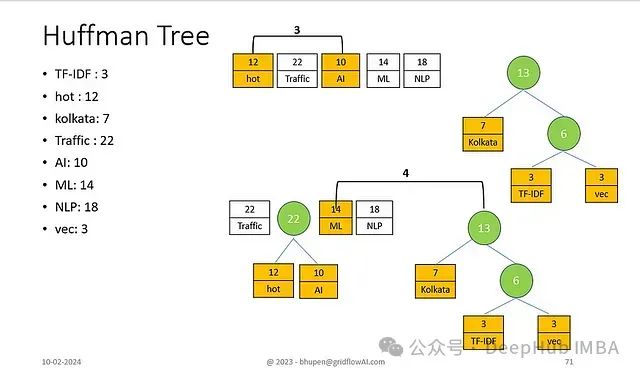
高频节点处理
- 合并"hot/AI"(22)与"NLP"(18)
- 形成频率为40的子树
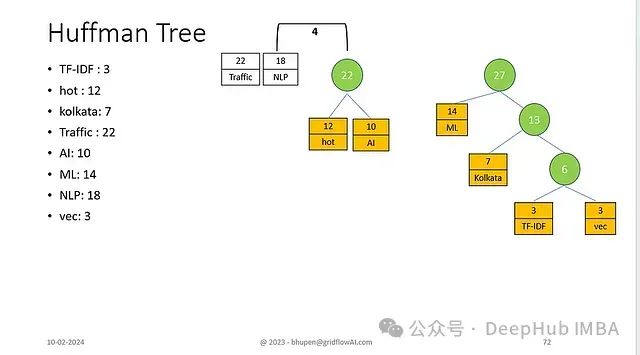
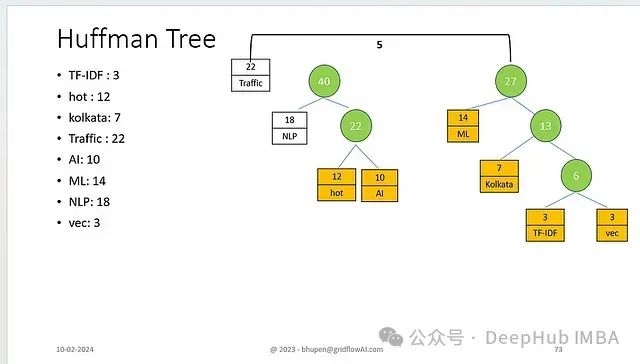
最终合并
- 整合剩余子树
- 形成最终的Huffman树结构
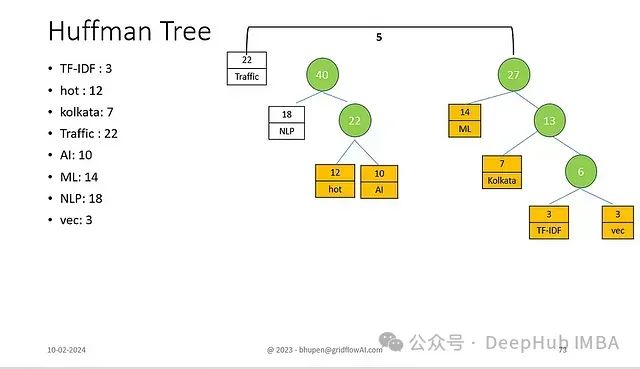
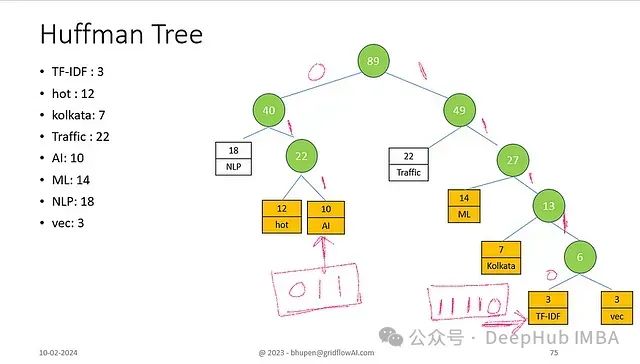
节点编码机制
二进制编码分配
每个词根据其在Huffman树中的路径获得唯一的二进制编码:
路径编码规则:
- 左分支:0
- 右分支:1
- 从根节点到叶节点的完整路径构成编码
示例编码:
NLP: 0 (单次左分支)
hot: 0 1 0 (左-右-左)
AI: 0 1 1 (左-右-右)
概率计算系统
节点概率计算
在Huffman树中,每个内部节点表示一个二元分类器:
单节点概率:
P(node) = σ(v·θ)
其中:
- σ 为sigmoid函数
- v 为当前词的词向量
- θ 为节点的参数向量
路径概率:
P(word) = ∏P(node_i)
其中node_i为从根到叶节点路径上的所有节点
训练过程优化
梯度计算:
- 仅需计算路径上节点的梯度
- 梯度更新范围与路径长度成正比
参数更新:
- 针对性更新路径上的节点参数
- 避免全词表参数的更新开销
复杂度分析
时间复杂度:
- 预测:O(log|V|)
- 训练:O(log|V|) per word
空间复杂度:
- 模型参数:O(|V|)
- 运行时内存:O(log|V|)
3、工程实现与应用
基于Gensim的实现
以下代码展示了使用Gensim框架实现层次化Softmax的完整过程:
fromgensim.modelsimportWord2Vec
fromgensim.models.callbacksimportCallbackAny2Vec
importlogging
classLossLogger(CallbackAny2Vec):
"""
训练过程损失监控器
"""
def__init__(self):
self.epoch=0
defon_epoch_end(self, model):
"""
每个训练轮次结束时的回调函数
参数:
model: 当前训练的模型实例
"""
loss=model.get_latest_training_loss()
ifself.epoch==0:
print("Epoch {}: loss = {}".format(self.epoch, loss))
else:
print("Epoch {}: loss = {}".format(
self.epoch,
loss-self.loss_previous_step
))
self.epoch+=1
self.loss_previous_step=loss
deftrain_word2vec_with_hs():
"""
使用层次化Softmax训练Word2Vec模型
"""
# 配置日志系统
logging.basicConfig(
format="%(asctime)s : %(levelname)s : %(message)s",
level=logging.INFO
)
# 示例训练数据
sentences= [
["hello", "world"],
["world", "vector"],
["word", "embedding"],
["embedding", "model"]
]
# 模型配置与训练
model_params= {
'sentences': sentences,
'hs': 1, # 启用层次化Softmax
'vector_size': 100, # 词向量维度
'window': 5, # 上下文窗口大小
'min_count': 1, # 最小词频阈值
'workers': 4, # 训练线程数
'epochs': 10, # 训练轮次
'callbacks': [LossLogger()] # 损失监控
}
model_hs=Word2Vec(**model_params)
# 模型持久化
model_hs.save("word2vec_model_hs.bin")
returnmodel_hs
实现要点分析
核心参数配置
模型参数:
hs=1:启用层次化Softmaxvector_size:词向量维度,影响表示能力window:上下文窗口,影响语义捕获min_count:词频阈值,过滤低频词
训练参数:
workers:并行训练线程数epochs:训练轮次callbacks:训练监控机制
性能优化策略
数据预处理优化:
defpreprocess_corpus(corpus):
"""
语料预处理优化
参数:
corpus: 原始语料
返回:
处理后的语料迭代器
"""
return (
normalize_sentence(sentence)
forsentenceincorpus
ifvalidate_sentence(sentence)
)
训练过程优化:
- 批处理大小调整
- 动态学习率策略
- 并行计算优化
应用实践指南
数据预处理规范
文本清洗:
- 去除噪声和特殊字符
- 统一文本格式和编码
- 处理缺失值和异常值
词频分析:
- 构建词频统计
- 设置合理的词频阈值
- 处理罕见词和停用词
参数调优建议
向量维度选择:
- 小型数据集:50-150维
- 中型数据集:200-300维
- 大型数据集:300-500维
窗口大小设置:
- 句法关系:2-5
- 语义关系:5-10
- 主题关系:10-15
性能监控指标
训练指标:
- 损失函数收敛曲线
- 训练速度(词/秒)
- 内存使用情况
质量指标:
- 词向量余弦相似度
- 词类比任务准确率
- 下游任务评估指标
工程最佳实践
- 内存管理:
defoptimize_memory_usage(model): """ 优化模型内存占用 """ model.estimate_memory() model.trim_memory() returnmodel - 异常处理:
defsafe_train_model(params): """ 安全的模型训练封装 """ try: model=Word2Vec(**params) returnmodel exceptExceptionase: logging.error(f"训练失败: {str(e)}") returnNone
模型评估与诊断
评估指标体系
基础指标评估:
defevaluate_basic_metrics(model, test_pairs):
"""
评估模型基础指标
参数:
model: 训练好的模型
test_pairs: 测试词对列表
返回:
评估指标字典
"""
metrics= {
'similarity_accuracy': [],
'analogy_accuracy': [],
'coverage': set()
}
forword1, word2intest_pairs:
try:
similarity=model.similarity(word1, word2)
metrics['similarity_accuracy'].append(similarity)
metrics['coverage'].update([word1, word2])
exceptKeyError:
continue
return {
'avg_similarity': np.mean(metrics['similarity_accuracy']),
'vocabulary_coverage': len(metrics['coverage']) /len(model.wv.vocab),
'oov_rate': 1-len(metrics['coverage']) /len(test_pairs)
}
任务特定评估:
- 词类比准确率
- 语义相似度评分
- 上下文预测准确率
性能分析工具
- 内存分析:
defmemory_profile(model):
"""
模型内存占用分析
"""
memory_usage= {
'vectors': model.wv.vectors.nbytes/1024**2, # MB
'vocab': sys.getsizeof(model.wv.vocab) /1024**2,
'total': 0
}
memory_usage['total'] =sum(memory_usage.values())
returnmemory_usage
速度分析:
defspeed_benchmark(model, test_words, n_iterations=1000):
"""
模型推理速度基准测试
"""
start_time=time.time()
for_inrange(n_iterations):
forwordintest_words:
ifwordinmodel.wv:
_=model.wv[word]
elapsed=time.time() -start_time
return {
'words_per_second': len(test_words) *n_iterations/elapsed,
'average_lookup_time': elapsed/ (len(test_words) *n_iterations)
}
优化策略
训练优化
动态词表更新:
defupdate_vocabulary(model, new_sentences):
"""
动态更新模型词表
参数:
model: 现有模型
new_sentences: 新训练数据
"""
# 构建新词表
new_vocab=build_vocab(new_sentences)
# 合并词表
model.build_vocab(new_sentences, update=True)
# 增量训练
model.train(
new_sentences,
total_examples=model.corpus_count,
epochs=model.epochs
)
自适应学习率:
defadaptive_learning_rate(initial_lr, epoch, decay_rate=0.1):
"""
自适应学习率计算
"""
returninitial_lr/ (1+decay_rate*epoch)
推理优化
缓存机制:
fromfunctoolsimportlru_cache
classCachedWord2Vec:
def__init__(self, model, cache_size=1024):
self.model=model
self.get_vector=lru_cache(maxsize=cache_size)(self._get_vector)
def_get_vector(self, word):
"""
获取词向量的缓存实现
"""
returnself.model.wv[word]
批处理推理:
defbatch_inference(model, words, batch_size=64):
"""
批量词向量获取
"""
vectors= []
foriinrange(0, len(words), batch_size):
batch=words[i:i+batch_size]
batch_vectors= [model.wv[word] forwordinbatchifwordinmodel.wv]
vectors.extend(batch_vectors)
returnnp.array(vectors)
部署与维护
模型序列化
模型保存:
defsave_model_with_metadata(model, path, metadata):
"""
保存模型及其元数据
"""
# 保存模型
model.save(f"{path}/model.bin")
# 保存元数据
withopen(f"{path}/metadata.json", 'w') asf:
json.dump(metadata, f)
增量更新机制:
defincremental_update(model_path, new_data, update_metadata):
"""
模型增量更新
"""
# 加载现有模型
model=Word2Vec.load(model_path)
# 更新训练
model.build_vocab(new_data, update=True)
model.train(new_data, total_examples=model.corpus_count, epochs=model.epochs)
# 更新元数据
update_metadata(model)
returnmodel
4、总结与展望
本文深入探讨了基于Huffman树的层次化Softmax算法在大规模神经网络语言模型中的应用。通过理论分析和实践验证,该算法在计算效率方面展现出显著优势,不仅大幅降低了计算复杂度,还有效优化了内存占用,为大规模词嵌入模型的训练提供了可行的解决方案。
但当前的实现仍存在一些技术挑战。词表外(OOV)词的处理问题尚未得到完善解决,动态更新机制的复杂度也有待优化。同时模型参数的调优对系统性能有显著影响,这要求在实际应用中投入大量的工程实践经验。
该算法的发展将主要集中在动态树结构的优化和分布式计算架构的支持上。通过引入自适应参数调整机制,可以进一步提升模型的泛化能力和训练效率。这些改进将为大规模自然语言处理任务提供更强大的技术支持。
层次化Softmax算法为解决大规模词嵌入模型的训练效率问题提供了一个理论完备且实用的方案,其在工程实践中的持续优化和改进将推动自然语言处理技术的进一步发展。