
前言
用Python写数据库操作的脚本时,少不了的是写入和读取操作。但这类方法参数说明大多都差不多,例如前段时间写的关于处理JSON文件的两类函数read_json,to_json。读取和写入这两种方法往往都是相对的,而当掌握了Pandas的dataframe数据结构的各种操作时,那么我们的插入方式将可以多种多样,对数据处理的方式也可以相对更加灵活。此篇文章将根据解读官方文档的方式具体使用每个参数的不同赋值,来展示结果。
官方文档:pandas.DataFrame.to_sql
一、函数基本语法
DataFrame.to_sql(name, con, schema=None, if_exists='fail',
index=True, index_label=None, chunksize=None, dtype=None)
该函数的具体功能为实现将pandas的数据结构存储对象Dataframe写入到SQL数据库中。其中我们要写入的SQL数据库中是应该存在数据库和表格的,不然会保存。而且该表是有权限能够写入的,这些是前提条件。
二、参数说明
Parameters:
name : string
Name of SQL table.
con : sqlalchemy.engine.Engine or sqlite3.Connection
Using SQLAlchemy makes it possible to use any DB supported by that library. Legacy support is provided for sqlite3.Connection objects.
schema : string, optional
Specify the schema (if database flavor supports this). If None, use default schema.
if_exists : {‘fail’, ‘replace’, ‘append’}, default ‘fail’
How to behave if the table already exists.
- fail: Raise a ValueError.
- replace: Drop the table before inserting new values.
- append: Insert new values to the existing table.
index : boolean, default True
Write DataFrame index as a column. Uses index_label as the column name in the table.
index_label : string or sequence, default None
Column label for index column(s). If None is given (default) and index is True, then the index names are used. A sequence should be given if the DataFrame uses MultiIndex.
chunksize : int, optional
Rows will be written in batches of this size at a time. By default, all rows will be written at once.
dtype : dict, optional
Specifying the datatype for columns. The keys should be the column names and the values should be the SQLAlchemy types or strings for the sqlite3 legacy mode.
Raises:
ValueError
When the table already exists and if_exists is ‘fail’ (the default).
1.name
该name为SQL表的名字,这是必须输入的参数,指定写入的表。
2.con
con为python连接sql的sqlalchemy.engine,该参数也为必须输入的参数,可以使用SQLAlchemy数据库支持的连接引擎。该引擎可以引入:
from sqlalchemy import create_engine
import pymysql
从而创建连接引擎:
#创建引擎
engine=create_engine('mysql+pymysql://用户名:密码@主机名/数据库?charset=utf8')
3.schema
指定架构(如果database flavor支持此功能)。如果没有,则使用默认架构。pandas中get_schema()方法是可以编写sql的写入框架的,没用传入的话就是普通的Dataframe读入形式。
4.if_exists
该参数为当存在表格时我们应该选择数据以怎样的方式写入到这张表格之中,共有三种方式选择:
- fail:当存在表格时候自动弹出错误ValueError
- replace:将原表里面的数据给替换掉
- append:将数据插入到原表的后面
我们首先引入库来实践操作一下:

这是表格,里面已经有了数据,下面我们进行插入实验:
from sqlalchemy import create_engine
import pymysql
import pandas as pd
import datetime
# 打开数据库连接
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
passwd='xxxx',
charset = 'utf8'
)
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = conn.cursor()
#创建引擎
engine=create_engine('mysql+pymysql://root:xxxx@localhost/mysql?charset=utf8')
date_now=datetime.datetime.now()
data={'id':[888,889],
'code':[1003,1004],
'value':[2000,2001],
'time':[20220609,20220610],
'create_time':[date_now,date_now],
'update_time':[date_now,date_now]}
insert_df=pd.DataFrame(data)
insert_df.to_sql('metric_valuetest',engine,if_exists='fail')
if_exists默认为fail则当存在表时,升起错误

若表格为没有命名的表格,则会自动创建表格:
from sqlalchemy import create_engine
import pymysql
import pandas as pd
import datetime
# 打开数据库连接
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
passwd='xxxx',
charset = 'utf8'
)
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = conn.cursor()
#创建引擎
engine=create_engine('mysql+pymysql://root:xxxx@localhost/mysql?charset=utf8')
date_now=datetime.datetime.now()
data={'id':[888,889],
'code':[1003,1004],
'value':[2000,2001],
'time':[20220609,20220610],
'create_time':[date_now,date_now],
'update_time':[date_now,date_now]}
insert_df=pd.DataFrame(data)
insert_df.to_sql('create_one',engine,if_exists='fail')

但是不推荐这样做,这样做将并不会指定创建表每个字段的详细信息和类型,看DDL就可以看出:
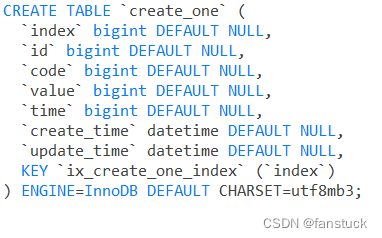
很容易出现问题,我们应该先创建个符合每个字段含义和类型的表格再写入其中。
append直接添加在原来数据后面:
date_now=datetime.datetime.now()
data={'id':[888,889],
'code':[1003,1004],
'value':[2000,2001],
'time':[20220609,20220610],
'create_time':[date_now,date_now],
'update_time':[date_now,date_now],
'source':['python','python']}
insert_df=pd.DataFrame(data)
'''schema_sql={ 'id': sqlalchemy.types.BigInteger(length=20),
'code': sqlalchemy.types.BigInteger(length=20),
'value': sqlalchemy.types.BigInteger(length=20),
'time': sqlalchemy.types.String(length=50),
'create_time': sqlalchemy.types.Datetime(length=50),
'update_time': sqlalchemy.types.Datetime(length=50),
}'''
insert_df.to_sql('metric_valuetest',engine,if_exists='append',index=False)

这里我们首先要吧index索引给关闭,不然会出现:
 index也算进写入mysql数据库中,导致原表中不存在index字段不能插入的问题。
index也算进写入mysql数据库中,导致原表中不存在index字段不能插入的问题。
insert_df.to_sql('metric_valuetest',engine,if_exists='replace',index=False)
replace将直接把原表数据给直接替换掉,要小心使用 。

5.index
默认为True等于存在第一行,列名为index的列,也可以先设定好行索引为哪一列防止插入的时报错。

6.index_label
索引列的列标签。如果未给定任何值(默认值)且index为True,则使用索引名称。如果数据帧使用多索引,则应给出序列。也就是如果设定的index为True,可以给index设定列名。
insert_df.to_sql('reate_one',engine,if_exists='replace',index=True,index_label='god')

7.chunksize
一次将按此大小成批写入行。默认情况下,将一次写入所有行。可以设定一次写入的数量,避免一次写入数据量过大导致数据库崩溃。
8.dtype
指定列的数据类型。键是列名,值是sqlite3模式的SQLAlchemy类型或字符串。可以去 sqlalchemy 的官方文档查看所有的sql数据类型:
‘TypeEngine’, ‘TypeDecorator’, ‘UserDefinedType’, ‘INT’, ‘CHAR’, ‘VARCHAR’, ‘NCHAR’, ‘NVARCHAR’, ‘TEXT’, ‘Text’, ‘FLOAT’, ‘NUMERIC’, ‘REAL’, ‘DECIMAL’, ‘TIMESTAMP’, ‘DATETIME’, ‘CLOB’, ‘BLOB’, ‘BINARY’, ‘VARBINARY’, ‘BOOLEAN’, ‘BIGINT’, ‘SMALLINT’, ‘INTEGER’, ‘DATE’, ‘TIME’, ‘String’, ‘Integer’, ‘SmallInteger’, ‘BigInteger’, ‘Numeric’, ‘Float’, ‘DateTime’, ‘Date’, ‘Time’, ‘LargeBinary’, ‘Binary’, ‘Boolean’, ‘Unicode’, ‘Concatenable’, ‘UnicodeText’, ‘PickleType’, ‘Interval’, ‘Enum’, ‘Indexable’, ‘ARRAY’, ‘JSON’]
from sqlalchemy import create_engine
import sqlalchemy
import pymysql
import pandas as pd
import datetime
from sqlalchemy.types import INT,FLOAT,DATETIME,BIGINT
date_now=datetime.datetime.now()
data={'id':[888,889],
'code':[1003,1004],
'value':[2000,2001],
'time':[20220609,20220610],
'create_time':[date_now,date_now],
'update_time':[date_now,date_now],
'source':['python','python']}
insert_df=pd.DataFrame(data)
schema_sql={ 'id':INT,
'code': INT,
'value': FLOAT(20),
'time': BIGINT,
'create_time': DATETIME(50),
'update_time': DATETIME(50)
}
insert_df.to_sql('create_two',engine,if_exists='replace',index=False,dtype=schema_sql)


点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
版权归原作者 fanstuck 所有, 如有侵权,请联系我们删除。