
ICLR 2021,它包含了860篇论文,8个研讨会和8个受邀演讲。全部看完这些论文需要花费很长的时间,所以这里总结了10篇论文,希望对你有所帮助!
一年前,ICLR 2020会议是第一个完全在线的大型会议,它为所有虚拟的会议设定了令人惊讶的高标准。今年又再次完成了在线会议,而且看起来非常棒:Transformers 出现在标题中的频率降低了……因为它们已经无处不在!计算机视觉,自然语言处理,信息检索,机器学习理论,强化学习……应有尽有!今年这一版内容的多样性令人瞠目结舌。
当谈到被邀请的演讲时,演讲阵容也令人兴奋:Timnit Gebru将在开幕式上谈论我们如何能超越机器学习中的公平言论,这将在大会上引发一些关于这个话题的讨论。研讨会也比以往任何时候都多,包括基于能源的模型,对ML论文的反思和AI的责任。
在Zeta Alpha的AI Research Navigator的帮助下,我们通过引用,Twitter受欢迎程度,作者影响力,演示以及该平台的一些建议,浏览了最相关的ICLR论文。我们确定了一些我们要强调的非常酷的作品;有些已经众所周知,有些更像是一颗隐藏的宝石。当然,这些选择并不旨在成为一个全面的概述-我们将在许多主题上都缺失,例如神经体系结构搜索,机器学习理论,强化学习或图NN等,以下是我的十大建议,如果你有兴趣的话,请继续阅读。
1、An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
By Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai et al.
直接应用于图像补丁并在大型数据集上进行过预培训的Transformers在图像分类方面确实非常有效。
→为什么→第一篇论文,展示纯净的Transformers如何可以在(大)大图像上改进最佳的CNN,从而引发了过去几个月的快速“视觉Transformers革命”。
💡关键见解→事实证明,迁移学习对Transformers非常有效:所有NLP的最新技术都融合了某种形式的迁移,例如自监督式预训练。从广义上讲,人们发现网络越大越好,网络可以传输的越好,而对于大型NN而言,Transformers是首屈一指的。
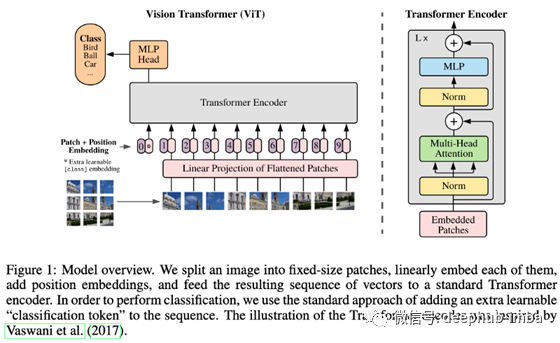
在此愿景的驱使下,作者展示了纯Transformer如何通过将图像作为一系列补丁嵌入(只是补丁像素的线性投影)进行馈送并直接在大量监督数据上进行训练而在图像分类中表现出色( ImageNet)。该论文暗示,该模型可以从自我监督的预训练中受益,但无法为其提供完整的实验。
结果表明,当模型离开数据约束机制时,ViT的表现将优于CNN,优于CNN +注意机制。甚至可以提高计算效率!在众多有趣的实验中,作者展示了来自注意力的感受场如何在各个层次上发展:最初是非常变化的(全局+局部),后来又在网络中专门研究局部注意力。
2、Rethinking Attention with Performers
By Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis et al.
这是一种线性的全等级注意力Transformer,它通过可证明的随机特征近似方法,而无需依赖稀疏性或低等级。
complexity of full attention复杂性仍然使许多机器学习研究人员无法深入理解。高效的Transformer已经问世了很长时间³,但是尚无任何提案明显主导这个领域……吗?
与高效Transformer的其他建议不同,表演者无需依靠特定的试探法来获取注意力,例如将注意力限制在较低等级的逼近上或强制稀疏。取而代之的是,作者提出了将自我关注机制分解成下面的矩阵的矩阵,这些矩阵的综合复杂度是线性的。序列长度L:O(Ld²log(d))而不是O(L²d)。
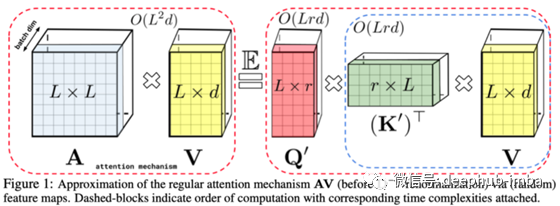
这种分解依赖太多的技巧,但是因为名字的缘故,我们谈论的是核,随机正交向量和三角软最大近似。所有服务于FAVOR+建筑,有非常严格的理论保证来估计自我关注。。
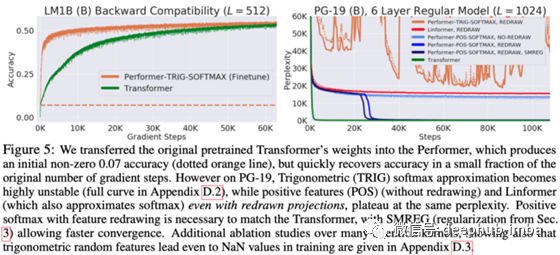
在实际实验中,这项工作将Performer与现有的高效Transformer(如Linformer¹和Reformer²)进行了比较,在建模非常长的依赖关系至关重要的任务(例如研究蛋白质序列)中,其性能要优于现有架构。最后,此方法的最大吸引力之一是,您可以将现有的经过预训练的Transformer与新的线性注意力机制一起使用,只需进行一些微调即可恢复大多数原始性能,如下所示。
3、PMI-Masking: Principled masking of correlated spans
By Yoav Levine et al.
相关标记的联合掩蔽显著加快和改善BERT的预处理。
一个非常干净和直接的想法加上同样显著的结果。它有助于我们理解掩蔽语言建模训练前的目标。
作者不是随机屏蔽令牌,而是识别——仅使用语料库统计——高度相关的令牌的范围。为了做到这一点,他们创建了一个扩展到任意长度跨度的标记对之间的点态互信息,并展示了如何训练具有该目标的BERT比均匀掩蔽、全字掩蔽、随机跨度掩蔽等替代方法更有效地学习。
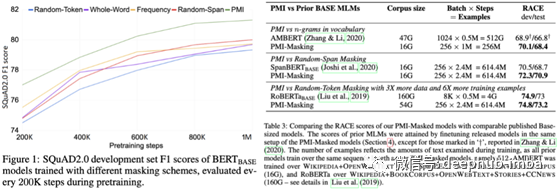
理论上,这个策略是有效的,因为你阻止了模型使用非常浅显的单词关联来预测掩蔽词,而这些单词经常相邻出现,这迫使模型学习语言中更深层的关联。在下面的图中,你可以看到Transformer如何更快地学习。
4、Recurrent Independent Mechanisms
By Anirudh Goyal, Jordan Hoffmann, Shagun Sodhani et al.
学习独立运行且很少交互的递归机制可以更好地归纳到分发样本之外。
如果人工智能想以某种方式类似于人类的智能,它需要推广到训练数据分布之外。这篇论文(最初从现在开始发布了一年多了)提供了洞察力,经验基础以及这种概括的进展。
循环独立机制是添加了一个注意力瓶颈模块的神经网络。这种方法通过人脑如何处理世界而获得启发。也就是说,主要是通过确定只会稀疏地和因果地相互作用的独立机制。例如,一组反弹的球可以在很大程度上相互独立建模,直到它们彼此碰撞,这是一个稀疏发生的事件。
RIM是递归网络的一种形式,其中大多数状态大部分时间都是自己发展的,并且只能通过注意力机制稀疏地交互,注意力机制可以是自上而下的(直接在隐藏状态之间)或自下而上的(在输入要素之间和在输入特征之间)。隐藏状态)。当输入数据分布发生变化时,该网络显示出比常规RNN更强的泛化能力。。
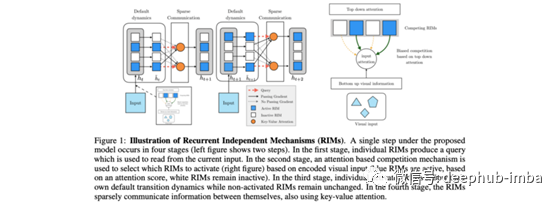
关于Transformer的一个重要结论是,神经网络中归纳偏差的重要性被夸大了。然而,这在对域内模型进行基准测试时是正确的。本文展示了如何,为了证明强先验(如注意力瓶颈模块)的有效性,一个人需要走出训练领域,而目前大多数ML/RL系统都没有以这种方式进行基准测试。
虽然结果可能并不是最让人印象深刻,本文——以及后续工作(见下文)——提出了一个雄心勃勃的议程的前进道路是什么把我们的ML系统变成类似于我们的大脑,我甚至可以说合并的最好美好的符号人工智能与过去十年的DL革命。我们应该庆祝这样的尝试!
5、Score-Based Generative Modeling through Stochastic Differential Equations
By Yang Song et al.
用于从基于得分的模型进行训练和采样的通用框架,该框架统一并泛化了以前的方法,允许进行似然计算,并实现可控的生成。
GAN仍然是怪异的创造...欢迎使用替代方法,这是非常有前途的:将数据转换为噪声很容易,将噪声转换为图像是...生成建模!这就是本文所做的。
我不能说我完全理解所有细节,因为很多数学我还不太理解。但是要点很简单:您可以将图像转换为“噪声”,作为“扩散过程”。想一想各个水分子如何在流动的水中移动:存在一定的确定性水流,该流动遵循一定的梯度,周围还附加了一些随机的摆动。您可以对像素图像进行相同的处理,将它们扩散,以至最终像易处理的概率分布中的噪声一样。可以将此过程建模为物理学中已知的随机微分方程,基本上是一个微分方程,在每个时间点都有一些增加的抖动。
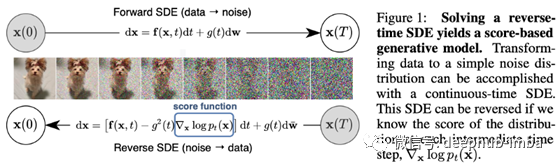
现在,如果我告诉您这种随机扩散过程是……可逆的!您基本上可以从这种噪声中采样,然后以备份的方式来制作图像。就像这样,作者在CIFAR-10上获得的SOTA初始评分为9.89,FID为2.20。背后还有很多事情要做……您真的需要查看本文!

6、Autoregressive Entity Retrieval
By Nicola De Cao, Gautier Izacard, Sebastian Riedel, Fabio Petroni.
我们通过以自回归的方式从左到右生成其唯一的名称标识符来解决实体检索问题,并且以显示SOTA的上下文为条件,该结果表明20多个数据集仅占最新系统内存的一小部分。
一种全新的直接实体检索方法,令人惊讶地打破了一些现有的基准。
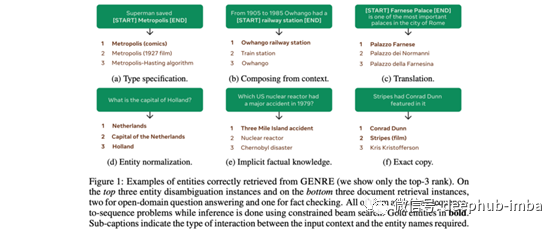
实体检索是找到自然语言所指的精确实体的任务(有时可能会有歧义)。现有的方法将其视为一个搜索问题,即从给定的一段文本中检索一个实体。直到现在。这项工作建议通过自回归生成实体标识符来寻找实体标识符:类似于markdown语法
[entity](identifier generated by the model)
。没有搜索+重新排序,什么都没有,简单明了。实际上,这意味着实体及其上下文的交叉编码,其优势是内存占用随词汇表大小线性扩展(不需要在知识库空间中做大量点积),而且不需要对负数据进行抽样。
从经过预训练的BART开始,他们会微调最大化具有实体的语料库的自回归生成的可能性。推断时他们使用约束 beam search来防止模型生成无效的实体(即不在KB中)。结果令人印象深刻,请参见下表中的示例。
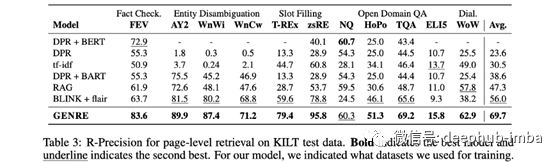
7、Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval
By Lee Xiong, Chenyan Xiong et al.
使用ANCE改进密集文本检索,该算法使用异步更新的ANN索引选择具有较大梯度范数的全局底片。
信息检索比“计算机视觉”更能抵抗“神经革命”。自从Bert以来,密集检索技术的发展是巨大的,这就是一个很好的例子。
训练模型进行密集检索时,通常的做法是学习与查询文档距离在语义上相关的嵌入空间。对比学习是做到这一点的一种标准技术:最小化正查询文档对的距离,并最小化负样本对的距离。但是,负面样本通常是随机选择的,这意味着它们的信息量不是很高:大多数时候,负面文献显然与查询无关。
本文的作者建议在训练期间从最近邻居中抽取否定词,从而得出接近查询的文档(即当前模型认为相关的文档)。实际上,这意味着在训练过程中需要非同步地更新语料库的索引(每次迭代更新索引将非常慢)。幸运的是,结果证实了BM25基准最终将如何被抛弃!
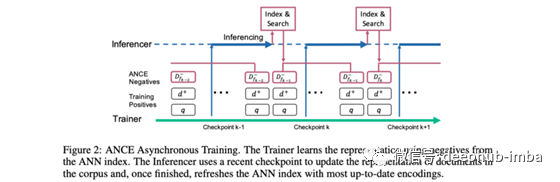
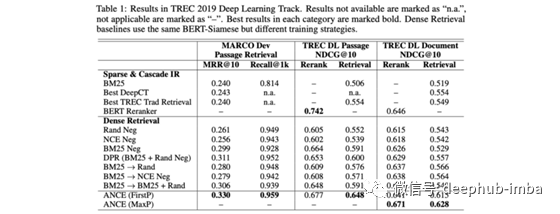
8、Image Augmentation Is All You Need: Regularizing Deep Reinforcement Learning from Pixels
By Denis Yarats, Ilya Kostrikovm, and Rob Fergus.
作者首次成功演示了可以将图像增强应用于基于图像的Deep RL,以实现SOTA性能。
您要支持什么?基于模型还是没有模型的RL?在回答问题之前,请先阅读本文!
现有的无模型RL能够成功地从状态输入中学习,但很难直接从图像中学习。直观地说,这是因为当从早期回放缓冲中学习时,大多数图像都是高度相关的,呈现出非常稀疏的奖励信号。该工作表明无模型方法如何极大地受益于像素空间的增强,从而在学习中变得更有效率,与DeepMind控制套件上现有的基于模型的方法相比,实现具有竞争力的结果;
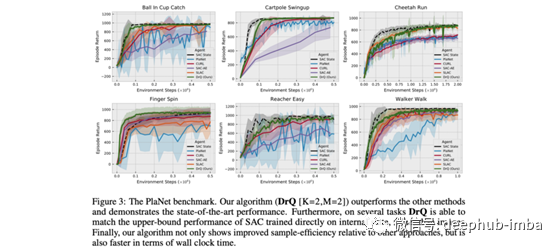
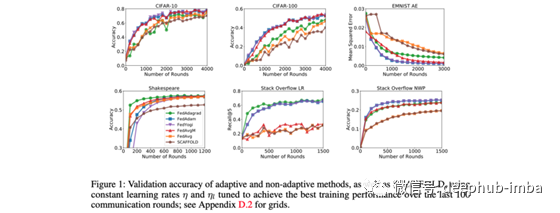
9、Adaptive Federated Optimization
By Sashank J. Reddi, Zachary Charles et al.
我们提出了自适应联邦优化技术,并着重强调了它们在诸如FedAvg之类的流行方法上的改进性能。
联邦学习是一种ML范例,其中由服务器托管的中央模型由多个客户端以分布式方式进行训练。例如,每个客户端可以在自己的设备上使用数据,计算梯度w.r.t。损失函数,并将更新的权重传达给中央服务器。这个过程提出了许多问题,例如如何结合来自多个客户的体重更新。
本文在解释联邦优化器的当前状态方面做得很出色,构建了一个简单的框架来讨论它们,并显示了一些关于收敛性保证的理论结果和经验结果,以表明它们提出的自适应联邦优化器比现有的优化器(如FedAvg⁸)更好地工作。本文介绍的联邦优化框架与客户端(ClientOpt)和服务器(ServerOpt)使用的优化器无关,并且使他们能够将诸如动量和自适应学习率之类的技术插入联合优化过程中。但是有趣的是,他们展示的结果始终使用传统的SGD作为ClientOpt,并使用自适应优化器(ADAM,YOGI)作为ServerOpt。
10、Can a Fruit Fly Learn Word Embeddings?
By Yuchen Liang et al.
一个来自果蝇大脑的网络motif可以学习单词嵌入。
单词可以非常有效地表示为稀疏二进制向量(甚至上下文化!)这项工作在精神上非常类似于Word2Vec,以及GloVe¹⁰,因为单词嵌入是通过非常简单的神经网络学习的,并聪明地使用共并发语料库统计来实现的。
该建筑的灵感来自于果蝇的生物神经元的组织方式:感觉神经元(PN)与肯扬细胞(KC)相连,而肯扬细胞与前配对外侧神经元(APL)相连,APL负责周期性地关闭大部分的KC,只留下少量的激活。
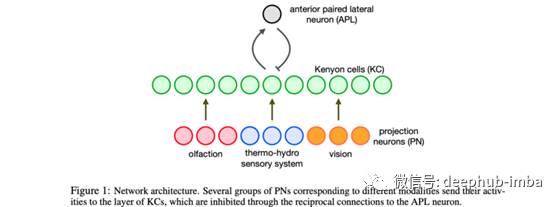
将此转换为语言,单词在PN神经元中表示为单词袋上下文和中间单词的一个热向量的连接(见下图)。然后将该向量视为训练样本,将其投影到KC神经元上并进行稀疏化(只有top-k值存活)。该网络通过最小化能量函数来训练,该能量函数使共享上下文的单词在KC空间中彼此靠近。
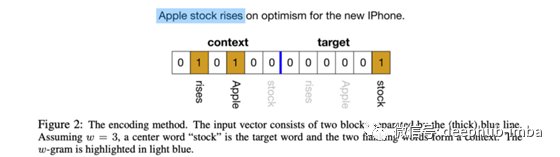
有趣的是,这允许动态生成上下文化的单词嵌入(😉),因为在推理过程中,单词袋上下文对给定单词可能是不同的。

最后,我想提一下,阅读ICLR的论文是多么令人愉悦的一件事,因为它们比arxiv.org的普通出版物要精致得多。不管怎样,这个集合到这里就结束了,但是会议还有很多值得探索的地方,
引用
[1] Linformer: Self-Attention with Linear Complexity — By Sinong Wang et al. 2020
[2] Reformer: The Efficient Transformer — By Nikita Kitaev et al. 2020
[3] Efficient Transformers, a Survey — By Yi Tay et al. 2020
[4] Big Bird: Transformers for Longer Sequences — By Manzil Zaheer et al. 2020
[5] BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension — By Mike Lewis, Yinhan Liu, Naman Goyal et al. 2019
[6] DeepMind Control Suite — By Yuval Tassa et al. 2018
[7] Model-Based Reinforcement Learning for Atari — By Łukasz Kaiser, Mohammad Babaeizadeh, Piotr Miłos, Błaz ̇ej Osiński et al. 2019
[8] Communication-Efficient Learning of Deep Networks from Decentralized Data — By H.BrendanMcMahan et al. 2016
[9] Efficient Estimation of Word Representations in Vector Space — By Tomas Mikolov et al. 2013
[10] GloVe: Global Vectors for Word Representation — By Jeffrey Pennington, Richard Socher, Christopher Manning 2014
[11] Adam: A Method for Stochastic Optimization — By Diederik P. Kingma et al. 2015
本文作者:Sergi Castella i Sapé
原文地址:https://towardsdatascience.com/iclr-2021-a-selection-of-10-papers-you-shouldnt-miss-888d8b8099dd
deephub翻译组