

Transformers是机器学习(ML)中一个令人兴奋的(相对)新的部分,但是在理解它们之前,有很多概念需要分解。这里我们关注的是基本的Self-Attention机制是如何工作的,这是Transformers模型的第一层。本质上,对于每个输入向量,Self-Attention产生一个向量,该向量在其邻近向量上加权求和,其中权重由单词之间的关系或连通性决定。
内容列表
- 介绍
- 自我关注-数学
- 引用文章
介绍
Transformers是一种ML架构,已经成功地应用于各种NLP任务,尤其是序列到序列(seq2seq)任务,如机器翻译和文本生成。在seq2seq任务中,目标是获取一组输入(例如英语单词)并产生一组理想的输出(德语中的相同单词)。自2017年发布以来,他们已经占领了seq2seq的主流架构(LSTMs),几乎无所不在地出现在任何关于NLP突破的新闻中(比如OpenAI的GPT-2甚至出现在主流媒体上!)。

图1:机器翻译 英->德
本篇将作为一个非常温和、渐进的介绍Transformer架构背后的数学、代码和概念。没有比注意力机制更好的开始了,因为:
最基本的transformers 完全依赖于注意力机制
Self-Attention的数学表示
我们需要一个ML系统来学习单词之间的重要关系,就像人类理解句子中的单词一样。在图2.1中,你我都知道“The”指的是“animal”,因此应该与这个词有很强的联系。如图中的颜色编码所示,该系统知道“animal”、“cross”、“street”和“the”之间存在某种联系,因为它们都与句子的主语“animal”有关。这是通过Self-Attention来实现的

图2.1:“The”注意力集中在了哪些词?
在最基本的层面上,Self-Attention是一个过程,其中一个向量序列x被编码成另一个向量序列z(图2.2)。每一个原始向量只是一个代表一个单词的数字块。它对应的z向量既表示原始单词,也表示它与周围其他单词的关系。
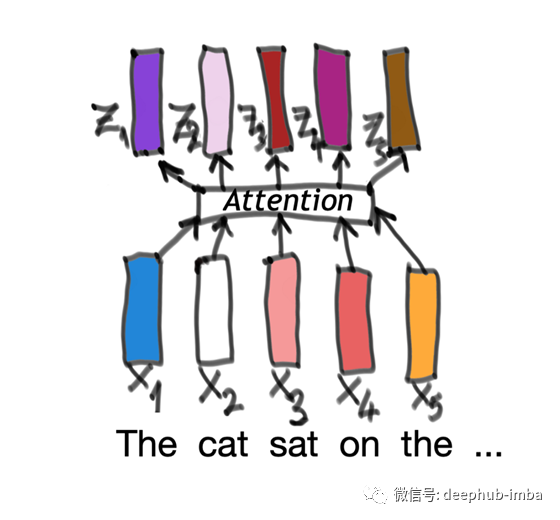
图2.2:把一系列的输入向量变成另一个长向量序列
向量表示空间中的某种事物,如海洋中的水粒子流或地球周围任何点的重力效应。你可以把单词看作是整个单词空间中的向量。每个词向量的方向都有意义。向量之间的相似性和差异性对应于单词本身的相似性和差异性。
让我们先看前三个向量,特别是向量x2,我们的“cat”向量,是如何变成z2的。对于每个输入向量,将重复所有这些步骤。
首先,我们将向量x2乘以一个序列中的所有向量,包括它本身。我们将对每个向量和x2的转置(对角翻转)做一个乘积(图2.3)。这和做点积是一样的,你可以把两个向量的点积看作是衡量它们有多相似。
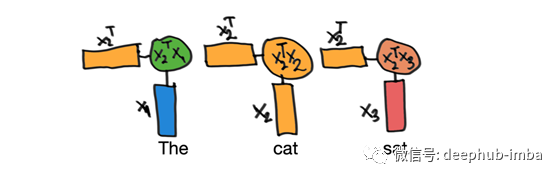
图2.3 转置乘法(上标“T”=“转置”)
两个向量的点积与它们之间夹角的余弦成正比(图2.4),因此它们在方向上越接近,点积就越大。如果它们指向同一个方向,那么角A为0⁰,余弦为0⁰等于1。如果它们指向相反的方向(因此A=180⁰),那么余弦值为-1。
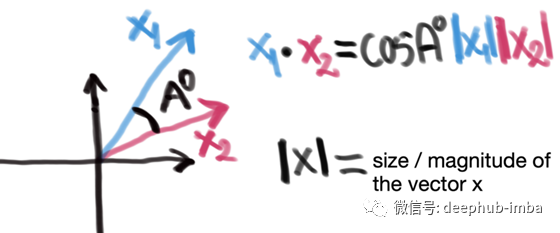
图2.4 向量点积
如果你想要一个更直观的观点,Bloem的文章(地址参看引用段)讨论了自我关注如何类似于推荐系统决定电影或用户的相似性。
所以我们一次只关注一个词,然后根据它周围的词来确定它的输出。这里我们只看前面和后面的单词,但我们可以选择在将来拓宽这个窗口。

图2.5-每个j-th向量的原始权重
如果我们关注的单词是“cat”,那么我们要复习的单词序列是“the”,“cat”,“sat”。我们要问的是“cat”这个词应该分别关注“the”、“cat”和“sat”(与图2.1所示类似)。
将关注的单词向量的转置和它周围的单词序列相乘将得到一组3个原始权重(图2.5)。两个词的权重是如何成比例的。我们需要对它们进行规范化,以便它们更易于使用。我们将使用softmax公式(图2.6)来实现这一点。这将数字序列转换为0,1的范围内,其中每个输出与输入数字的指数成比例。这使得我们的权重更容易使用和解释。

图2.6:通过softmax函数将原始权重标准化
现在我们取归一化的权重(j序列中每个向量对应一个),分别将它们与x输入向量相乘,将它们的乘积相加,结果就完成了!我们有一个输出z向量,(图2.5)!当然,这只是x2的输出向量(“cat”)——这个操作将对x中的每个输入向量重复,直到我们得到图2.2中所说的输出序列。
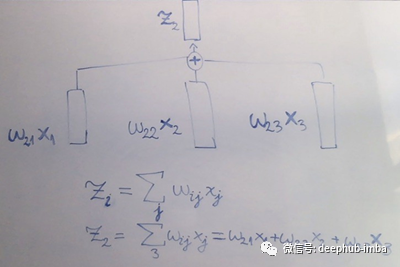
图2.7:最终得到新的向量序列z的操作
这种解释到目前为止可能引发了一些问题:
我们计算的权重不是很大程度上依赖于我们如何确定原始输入向量吗?
为什么我们要依赖向量的相似性?如果我们想在两个“不相似”的单词之间找到联系,比如“the cat sit on the matt”的宾语和主语,该怎么办?
在后面的文章中,我们将讨论这些问题。我们将根据每个向量的不同用法对其进行转换,从而更精确地定义单词之间的关系,这样我们就可以得到如图2.8所示的输出。
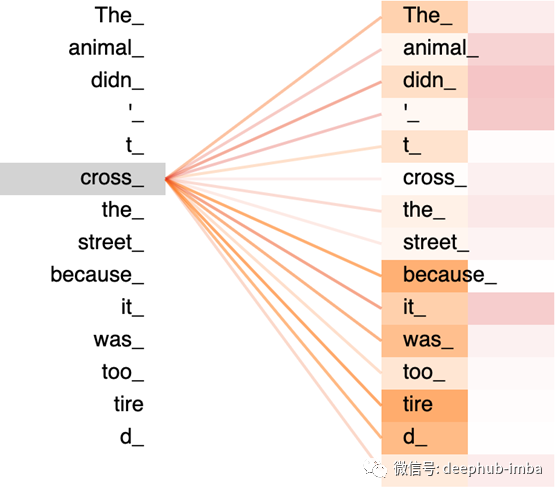
图2.8 -橙色栏中的“cross”和粉色栏中的“cross”关注的是哪个单词?
引用
- Alammar J. The Illustrated Transformer. (2018) https://jalammar.github.io/illustrated-transformer/ [accessed 27th June 2020]
- Bloem P. Transformers from Scratch. (2019) http://www.peterbloem.nl/blog/transformers .[accessed 27th June 2020]
- Vaswani A. et al. Dec 2017. Attention is all you need. 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA. https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf [accessed 27th June 2020]. arXiv:1706.03762
- Vaswani A. et al. Mar 2018 arXiv:1803.07416 .
作者:Ioana
deephub翻译组
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
喜欢就请三连暴击!********** **********