
数据集可以讲述很多故事。要想了解这些故事的展开,最好的方法就是从检查变量之间的相关性开始。在研究数据集时,我首先执行的任务之一是查看哪些变量具有相关性。这让我更好地理解我正在使用的数据。这也是培养对数据的兴趣和建立一些初始问题来尝试回答的好方法。简单地说,相关性是非常重要的。
Python的最大好处就库多,有很多库已经为我们提供了快速有效地查看相关性所需的工具。让我们简要地看看什么是相关性,以及如何使用热图在数据集中找到强相关性。
什么是相关性?
相关性是一种确定数据集中的两个变量是否以任何方式关联的方法。关联具有许多实际应用。我们可以查看使用某些搜索词是否与youtube上的观看次数相关。或者查看广告是否与销售相关。建立机器学习模型时,相关性是确定特征的重要因素。这不仅可以帮助我们查看哪些要素是线性相关的,而且如果要素之间的相关性很强,我们可以将其删除以防止信息重复。
您如何衡量相关性?
在数据科学中,我们可以使用r值,也称为Pearson的相关系数。这可测量两个数字序列(即列,列表,序列等)之间的相关程度。
r值是介于-1和1之间的数字。它告诉我们两列是正相关,不相关还是负相关。越接近1,则正相关越强。接近-1时,负相关性越强(即,列越“相反”)。越接近0,相关性越弱。
r值公式

让我们通过一个简单的数据集进行相关性的可视化
它具有以下列,重量,年龄(以月为单位),乳牙数量和眼睛颜色。眼睛颜色列已分类为1 =蓝色,2 =绿色和3 = 棕色。
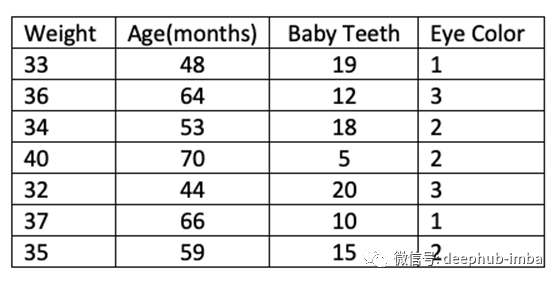
让我们使用以上数据绘制3个散点图。我们将研究以下3种关系:年龄和体重,年龄和乳牙以及年龄和眼睛的颜色。
年龄和体重
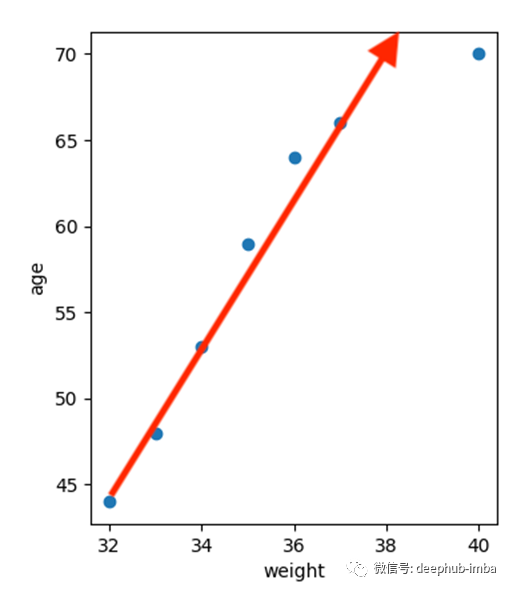
当我们观察年龄和体重之间的相关性时,图上的点开始形成一个正斜率。当我们计算r值时,得到0.954491。随着r值如此接近1,我们可以得出年龄和体重有很强的正相关关系的结论。一般情况下,这应该是正确的。在成长中的孩子中,随着年龄的增长,他们的体重开始增加。
年龄和乳牙

相反,年龄和乳牙散点图上的点开始形成一个负斜率。该相关性的r值为-0.958188。这表明了很强的负相关关系。直观上,这也是有道理的。随着孩子年龄的增长,他们乳牙会被替换掉。
年龄和眼睛颜色
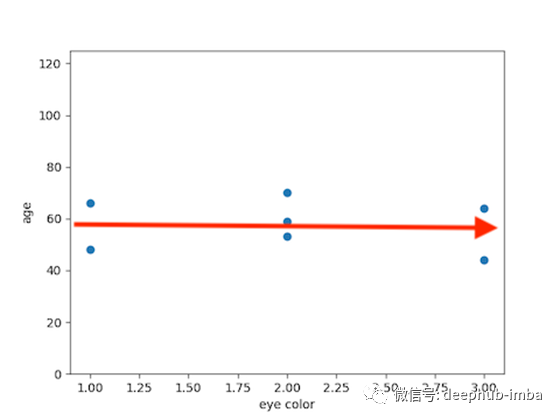
在上一个散点图中,我们看到一些点没有明显的斜率。该相关性的r值为-0.126163。年龄和眼睛颜色之间没有显著的相关性。这也应该说得通,因为眼睛的颜色不应该随着孩子长大而改变。如果这种关系显示出很强的相关性,我们会想要检查数据来找出原因。
使用Python查找相关性
让我们看看一个更大的数据集,并且使用Python的库查找相关性。
我们将使用来自于一个Kaggle上关于流媒体平台上的电影数据集。这个数据集包含哪些电影来自于哪个平台,它还包括关于每部电影的一些不同的列,如名称、IMDB分数等。
导入数据和简单的清洗
我们将首先导入数据集,然后使用PANDAS将其转换为DataFrame。
import pandas as pd
movies = pd.read_csv("MoviesOnStreamingPlatforms_updated.csv")
Rotten Tomatoes列(烂番茄,国外著名的电影评分网站)是一个字符串,让我们将数据类型改为浮点数。
movies['Rotten Tomatoes'] =
movies['Rotten Tomatoes'].str.replace("%" , "").astype(float)
Type列似乎没有正确输入,让我们删除它。
movies.drop("Type", inplace=True, axis=1)
好了,现在可以进行我们的工作了!
使用core()方法
使用Pandas correlation方法,我们可以看到DataFrame中所有数字列的相关性。因为这是一个方法,我们所要做的就是在DataFrame上调用它。返回值将是一个新的DataFrame,显示每个相关性。
corr()方法有一个参数,允许您选择查找相关系数的方法。默认方法是Pearson方法,但您也可以选择Kendall或Spearman方法。
correlations = movies.corr()
print(correlations)\\ID Year IMDb Rotten Tomatoes Netflix \
ID 1.000000 -0.254391 -0.399953 -0.201452 -0.708680
Year -0.254391 1.000000 -0.021181 -0.057137 0.258533
IMDb -0.399953 -0.021181 1.000000 0.616320 0.135105
Rotten Tomatoes -0.201452 -0.057137 0.616320 1.000000 0.017842
Netflix -0.708680 0.258533 0.135105 0.017842 1.000000
Hulu -0.219737 0.098009 0.042191 0.020373 -0.107911
Prime Video 0.554120 -0.253377 -0.163447 -0.049916 -0.757215
Disney+ 0.287011 -0.046819 0.075895 -0.011805 -0.088927
Runtime -0.206003 0.081984 0.088987 0.003791 0.099526
Hulu Prime Video Disney+ Runtime
ID -0.219737 0.554120 0.287011 -0.206003
Year 0.098009 -0.253377 -0.046819 0.081984
IMDb 0.042191 -0.163447 0.075895 0.088987
Rotten Tomatoes 0.020373 -0.049916 -0.011805 0.003791
Netflix -0.107911 -0.757215 -0.088927 0.099526
Hulu 1.000000 -0.255641 -0.034317 0.033985
Prime Video -0.255641 1.000000 -0.298900 -0.067378
Disney+ -0.034317 -0.298900 1.000000 -0.019976
Runtime 0.033985 -0.067378 -0.019976 1.000000
输出的列太多,使其难以读取。这只是9个变量的相关性,结果是一个9x9的网格。你能想象看到20或30个吗?这将是非常困难的。
输出
如果我们不调用打印,只是让Jupyter格式返回。
movies.corr()

我们还可以通过使用列名进行切片来单独检查每个变量。
print(correlations["Year"])
//
ID -0.254391
Year 1.000000
IMDb -0.021181
Rotten Tomatoes -0.057137
Netflix 0.258533
Hulu 0.098009
Prime Video -0.253377
Disney+ -0.046819
Runtime 0.081984
如果仅查看1个变量的相关性,则它较易读且足够。但是,必须有一种更简单的方法来查看整个数据集。
使用Seaborn进行可视化
我们可以通过seaborn快速生成热图。为什么使用seaborn?因为seaborn是基于matplotlib开发的并且提供了更多的扩展功能,最主要是的,它比matplotlib漂亮。
#always remember your magic function if using Jupyter
%matplotlib inline
import seaborn as sns
import matplotlib.pyplot as plt
sns.heatmap(correlations)
plt.show()
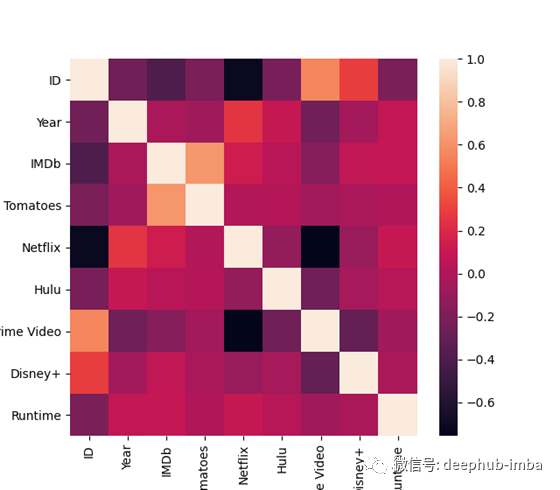
我们的发现
现在我们可以快速看到一些相关性。
- IMDb和烂番茄之间有很强的正相关性。以及主要视频和ID之间的强正相关性。
- Netflix与Year之间存在轻微的正相关。
- Netflix与ID,Netflix和Prime Video之间的强烈负相关
- Year和Prime Video,Disney Plus和Prime Video,Hulu和Prime Video以及Netflix和ID之间存在轻微的负相关。
- runtime 与任何流平台之间都没有关联
- Netflix与年份之间没有关联
有了这些信息,我们可以进行一些观察。
- 由于ID与所显示的两个平台之间的正相关和负相关性很强,因此先按顺序添加数据,然后依次添加Netflix和Prime Video。如果我们要用这些数据来构建模型,则最好在将其拆分为测试和训练数据之前将其打乱。
- 看起来Netflix有较新的电影。这可能是要探索的假设。
- 与其他流媒体平台相比,Netflix和亚马逊似乎拥有最多的独特电影。要探索的另一个假设。
- 不同的平台似乎不会根据评论者的得分来选择电影。我们可以探索另一个很酷的假设。
在几秒钟内,我们就能看到如何输入数据,并至少可以探索3个想法。
结论
通过使用seaborn的热图,我们可以轻松地看到最相关的位置。这对于了解一个新的数据集是非常有帮助的
作者:Jeremiah Lutes
deephub翻译组
原文地址: https://towardsdatascience.com/correlation-is-simple-with-seaborn-and-pandas-28c28e92701e