
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
在之前的文章中,我们建立自回归模型处理灰度图像,灰度图像只有一个通道。在这篇文章中,我们将讨论如何用多个通道建模图像,比如RGB图像。让我们开始!
如果你对自回归模型还不太了解,请看我们之前翻译的文章:
介绍
正如我们在上一篇文章中所讨论的,自回归生成模型从条件分布的乘积中生成数据,这意味着它们依赖于先前的像素。因此为了训练 PixelCNN,我们需要对生成图像的像素进行排序(例如,从上到下和从左到右)。为了在卷积运算中隐藏“未来”像素,我们屏蔽了卷积层以忽略需要预测的像素之后的信息。模型的第一层不应该访问输入图像的目标像素,因此我们将掩码中的中心像素归零(我们称之为Mask A)。但是在后面的层中,mask中的中心像素已经忽略了输入图像的感兴趣像素,所以不应该归零,所以我们使用了一个Mask B。当处理多通道的图像时, 例如具有三个颜色通道的彩色图像,我们应该使用哪些掩码?
彩色图像
彩色图像由三个通道组成,红色、绿色和蓝色 (RGB)。不同的颜色通道也可以称为子像素。每个子像素并不独立于其他子像素,因为它们在组合时才能构成一致的图像。为了我们可以顺序处理它们并在预测下一个子像素时考虑之前的子像素,子像素也必须进行排序。斌且给需要构建掩码以确保像素的预测不是其输入值的函数。

任何彩色图像都可以分解为 3 个图像 RGB。
按照原论文,我们选择从 R → G → B 对子像素进行排序。在第一个卷积层中,我们使用 Mask A,其中 R 通道将只能访问先前像素的信息,我们称之为上下文 ,G 通道将可以访问上下文和 R 通道,最后,B 通道将可以访问上下文以及 R 和 G 通道。在接下来的卷积层中,前一个卷积层的中心像素还没有“看到”输入的中心像素。因此,不需要将中心子像素归零。这意味着在 Mask B 中,R 通道可以访问上下文和前一层的 R 通道。G 通道可以访问上下文以及 R 和 G 通道,B 通道将可以访问上下文和三个通道。
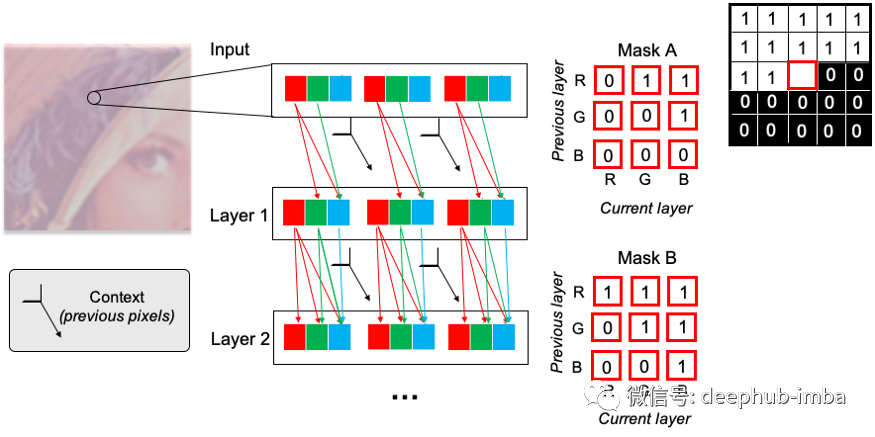
每个子像素的信息访问可视化。Mask A 和 B 的中心像素值不同,具体取决于它们在当前层和前一层中连接的子像素。上下文与所有已经处理过的像素有关。对于一对子像素和特定掩码,红色方块表示中心像素是否被遮挡。黑色方块显示了 A 和 B 的掩码的共同值(所有变化都是中央红色方块)。
在这里,我们展示了如何为具有多个通道的图像构建掩码的一个片段。掩码连接当前层 (i) 的通道时,该通道是比前一层通道 (j) 晚的通道,我们将中心像素归零。对于Mask A,当前层连接上一层中的相同通道时,我们还将中心像素归零。
我们使用的网络架构类似于 Oord 等人提出的单通道生成模型的网络架构。2016 年实现,带有 15 个残差块。与前一篇文章相同。
训练和推理
当我们对彩色图像进行推理时,我们必须预测比单通道图像多三倍的值。这使得训练模型更具挑战性。在这里,我们使用 CIFAR10 数据集训练了我们的 PixelCNN,我们首先将模型过度拟合到前两个训练集图像。

所有生成的图像都是训练示例的近乎完美的副本。在 10 个 epoch 之后,该模型已经学会准确地模仿训练集。但是,当我们尝试预测模型尚未看到的被遮挡图像的下一个像素时,它在生成图片方面做得很差。这是肯定的,因为模型只学会了复制它显示的两个示例。

过拟合的生成模型在预测遮挡图像方面做得很差。接下来,我们使用 50000 个训练图像示例将 PixelCNN 训练了 20 个epoch ,以使我们的模型学习自然图像。

生成的图像看起来不自然,现在的结果并不出色。尽管生成了有趣的图像,但他们似乎并没有学习他们接受训练的自然图像的结构。
在以后的文章中,我们将探索效率低下的原因——比如感受野的盲点,我们将学习新技术来提高生成图像的质量。在这里,我们可以通过将 CIFAR10 图像从每个子像素的原始 256 个强度值量化为每个子像素 8 个强度值来简化问题。我们为 20 个 epoch 训练了相同的模型,并展示了生成的图像是如何随着 epoch 演变的。

训练得越多,结果就越好。在最终epoch 生成的图像已经具有自然的颜色组合。它也不像训练数据中的图像,因此它正在学习数据流形分布。我们现在可以看到模型生成了哪些图像以及它如何预测被遮挡的图像。

上图是在完整的 CIFAR10 数据集上训练的 PixelCNN 生成的图像。

该模型在重新创建图像的遮挡区域方面做得很好。
总结
训练 PixelCNN 来预测彩色图形是一项挑战。虽然将像素强度级别的数量从 256 减少到 8 能够改善结果,但生成的图像仍然不理想。我们在文中简单提到可以通过修复盲点问题来提高性能。所以在接下来的文章中,我们将介绍什么是盲点,然后我们将展示我们如何修复它。所以,请继续关注!
引用
- http://bjlkeng.github.io/posts/pixelcnn/
- https://github.com/bjlkeng/sandbox/blob/master/notebooks/pixel_cnn/pixelcnn_helpers.py
- http://sergeiturukin.com/2017/02/22/pixelcnn.html
- https://github.com/rampage644/wavenet/blob/master/wavenet/models.py
- https://github.com/tensorflow/magenta/blob/master/magenta/reviews/pixelrnn.md
作者:Walter Hugo Lopez Pinaya, Pedro F. da Costa, and Jessica Dafflon
喜欢就关注一下吧:
点个 在看 你最好看!********** **********