
如何将20GB的CSV文件放入16GB的RAM中。
如果你对Pandas有一些经验,并且你知道它最大的问题——它不容易扩展。有解决办法吗?
是的-Dask DataFrames。
大多数Dask API与Pandas相同,但是Dask可以在所有CPU内核上并行运行。它甚至可以在集群上运行,但这是另一个话题。
今天你将看到Dask在处理20GB CSV文件时比Pandas快多少。运行时值将因PC而异,所以我们将比较相对值。郑重声明,我使用的是MBP 16”8核i9, 16GB内存。
本文的结构如下:
- 数据集生成
- 处理单个CSV文件
- 处理多个CSV文件
- 结论
数据集生成
我们可以在线下载数据集,但这不是本文的重点。我们只对数据集大小感兴趣,而不是里面的东西。
因此,我们将创建一个有6列的虚拟数据集。第一列是一个时间戳——以一秒的间隔采样的整个年份,其他5列是随机整数值。
为了让事情更复杂,我们将创建20个文件,从2000年到2020年,每年一个。
在开始之前,请确保在笔记本所在的位置创建一个数据文件夹。下面是创建CSV文件的代码片段:
import numpy as np
import pandas as pd
import dask.dataframe as dd
from datetime import datetime
for year in np.arange(2000, 2021):
dates = pd.date_range(
start=datetime(year=year, month=1, day=1),
end=datetime(year=year, month=12, day=31),
freq=’S’
)
df = pd.DataFrame()
df[‘Date’] = dates
for i in range(5):
df[f’X{i}’] = np.random.randint(low=0, high=100, size=len(df)) df.to_csv(f’data/{year}.csv’, index=False)
你现在可以使用一个基本的Linux命令来列出数据目录:
!ls -lh data/
以下是结果:
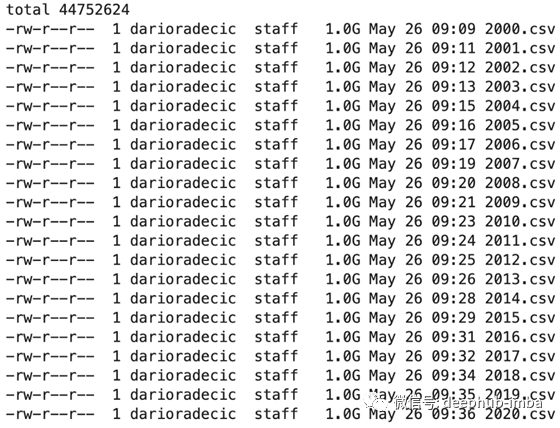
正如您所看到的,所有20个文件的大小都在1GB左右(更准确地说是1.09)。上面的代码片段需要一些时间来执行,但仍然比下载一个20GB文件要少得多。
接下来,让我们看看如何处理和聚合单个CSV文件。
处理单个CSV文件
目标:读取一个单独的CSV文件,分组的值按月,并计算每个列的总和。
用Pandas加载单个CSV文件再简单不过了。read_csv()函数接受parse_dates参数,该参数自动将一个或多个列转换为日期类型。
这个很有用,因为我们可以直接用dt。以访问月的值。下面是完整的代码片段:
%%time
df = pd.read_csv(‘data/2000.csv’, parse_dates=[‘Date’])
monthly_total = df.groupby(df[‘Date’].dt.month).sum()
这是总运行时间:
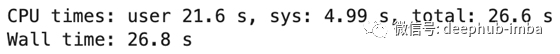
对于1GB的文件来说还不错,但是运行时取决于您的硬件。让我们对Dask做同样的事情。这是代码:
%%time
df = dd.read_csv(‘data/2000.csv’, parse_dates=[‘Date’])
monthly_total = df.groupby(df[‘Date’].dt.month).sum().compute()
与往常一样,在调用compute()函数之前,Dask不会完成任何处理。你可以看到下面的总运行时间:

让我们来比较一下不同点:
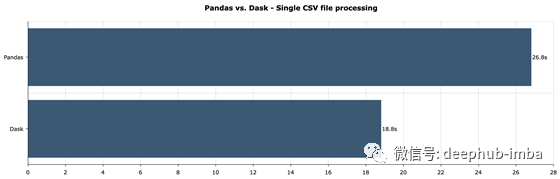
这并不是一个显著的区别,但Dask总体上是一个更好的选择,即使是对于单个数据文件。这是一个很好的开始,但是我们真正感兴趣的是同时处理多个文件。
接下来让我们探讨如何做到这一点。
处理多个CSV文件
目标:读取所有CSV文件,按年值分组,并计算每列的总和。
使用Pandas处理多个数据文件是一项乏味的任务。简而言之,你必须一个一个地阅读文件,然后把它们垂直地叠起来。
如果您考虑一下,单个CPU内核每次加载一个数据集,而其他内核则处于空闲状态。这不是最有效的方法。
glob包将帮助您一次处理多个CSV文件。您可以使用data/*. CSV模式来获取data文件夹中的所有CSV文件。然后,你必须一个一个地循环读它们。最后,可以将它们连接起来并进行聚合。
下面是完整的代码片段:
%%time
import glob
all_files = glob.glob('data/*.csv')
dfs = []
for fname in all_files:
dfs.append(pd.read_csv(fname, parse_dates=['Date']))
df = pd.concat(dfs, axis=0)
yearly_total = df.groupby(df['Date'].dt.year).sum()
下面是运行时的结果:

15分半钟似乎太多了,但您必须考虑到在此过程中使用了大量交换内存,因为没有办法将20+GB的数据放入16GB的RAM中。如果notebook 完全崩溃,使用少量的CSV文件。
让我们看看Dask提供了哪些改进。它接受read_csv()函数的glob模式,这意味着您不必使用循环。在调用compute()函数之前,不会执行任何操作,但这就是库的工作方式。
下面是加载和聚合的完整代码片段:
%%time
df = dd.read_csv(‘data/*.csv’, parse_dates=[‘Date’])
yearly_total = df.groupby(df[‘Date’].dt.year).sum().compute()
下面是运行时的结果:
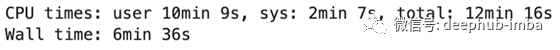
让我们来比较一下不同点:
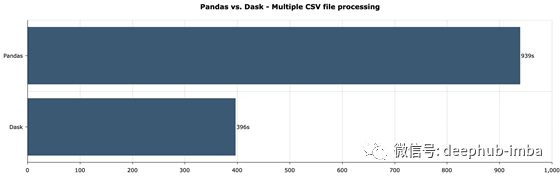
正如您所看到的,当处理多个文件时,差异更显著——在Dask中大约快2.5倍。一个明显的赢家,毋庸置疑。
让我们在下一节结束这些内容。
结论
今天,您学习了如何从Pandas切换到Dask,以及当数据集变大时为什么应该这样做。Dask的API与Pandas是99%相同的,所以你应该不会有任何切换困难。
请记住—有些数据格式在Dask中是不支持的—例如XLS、Zip和GZ。此外,排序操作也不受支持,因为它不方便并行执行。
作者:Dario Radečić
原文地址:https://towardsdatascience.com/dask-dataframes-how-to-run-pandas-in-parallel-with-ease-b8b1f6b2646b
deephub翻译组