
目录
参考
经典大数据开发实战(Hadoop &HDFS&Hive&Hbase&Kafka&Flume&Storm&Elasticsearch&Spark)
概念
MapReduce 常用于对大规模数据集(大于 1TB)的并行运算,或对大数据进行加工、挖掘和优化等处理。
MapReduce 将并行计算过程高度抽象到了两个函数 map 和reduce 中,程序员只需负责 map和 reduce 函数的编写工作,而并行程序中的其它复杂问题(如分布式存储、工作调度、负载均衡、容错处理等)均可由MapReduce 框架代为处理,程序员完全不用心。
MapReduce 技术特征:
- 横向扩展,而非纵向扩展过
- 失效被认为是常态、
- 将处理向数据迁移
- 顺序处理数据
- 隐藏系统层细节.
- 平滑无缝的可扩展性。
设计思想
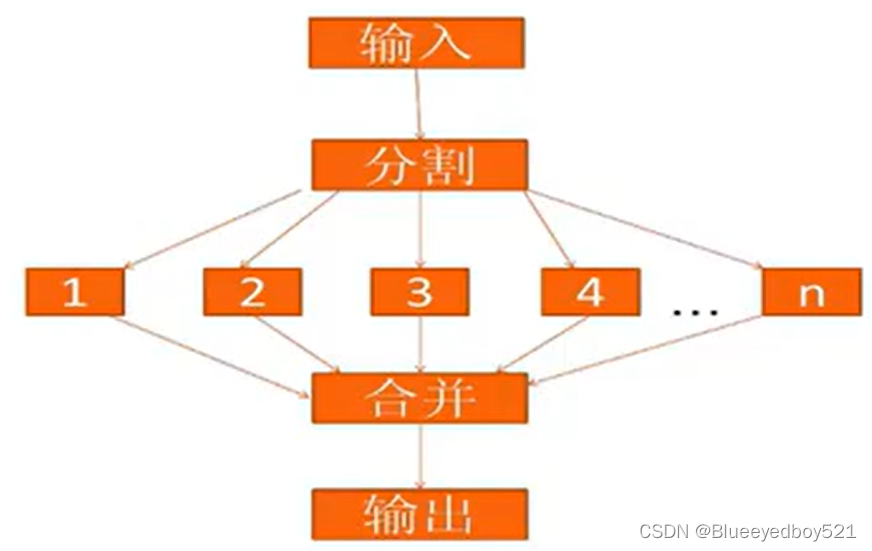
以下例子介绍了求和的思想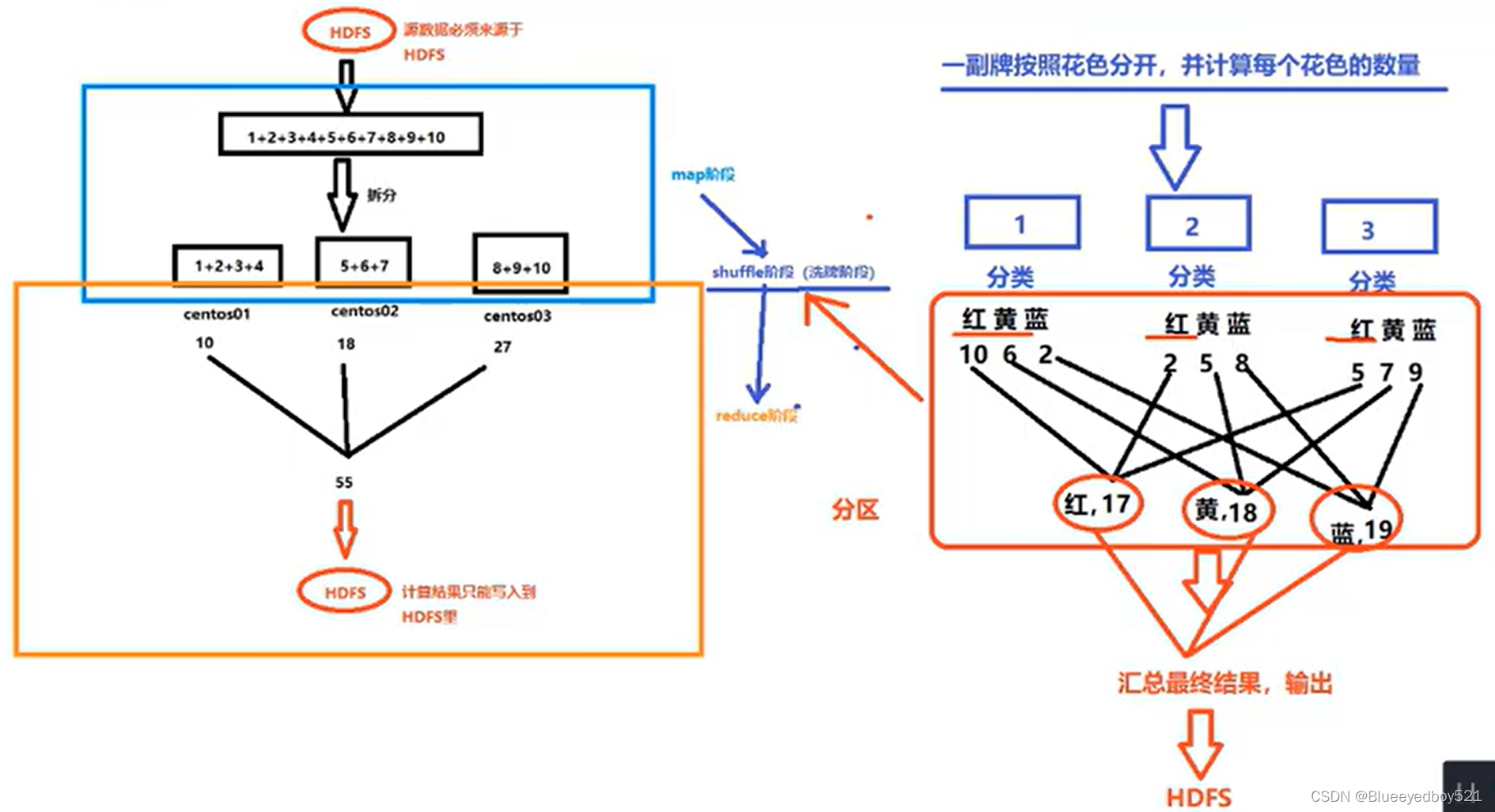
工作原理
MapReduce程序运行于YARN 之上,使用 YARN 进行集群资源管理和调度。每个MapReduce 应用程序会在 YARN 中产生一个名为“MRAppMaster”的进程,该进程是MapReduce 的 ApplicationMaster 实现,它具有 YARN中ApplicationMaster 角色的所有功能,包括管理整个 MapReduce 应用程序的生命周期、任务资源中请、Container 启动与释放等
客户端将 MapReduce 应用程序(jar、可执行文件等)和配置信息提交给 YARN 集群的ResourceManager,ResourceManager 负贵将应用程序和配置信息分发给NodeManager、调度和监控任务、向客户端提供状态和诊断信息等。
计算流程
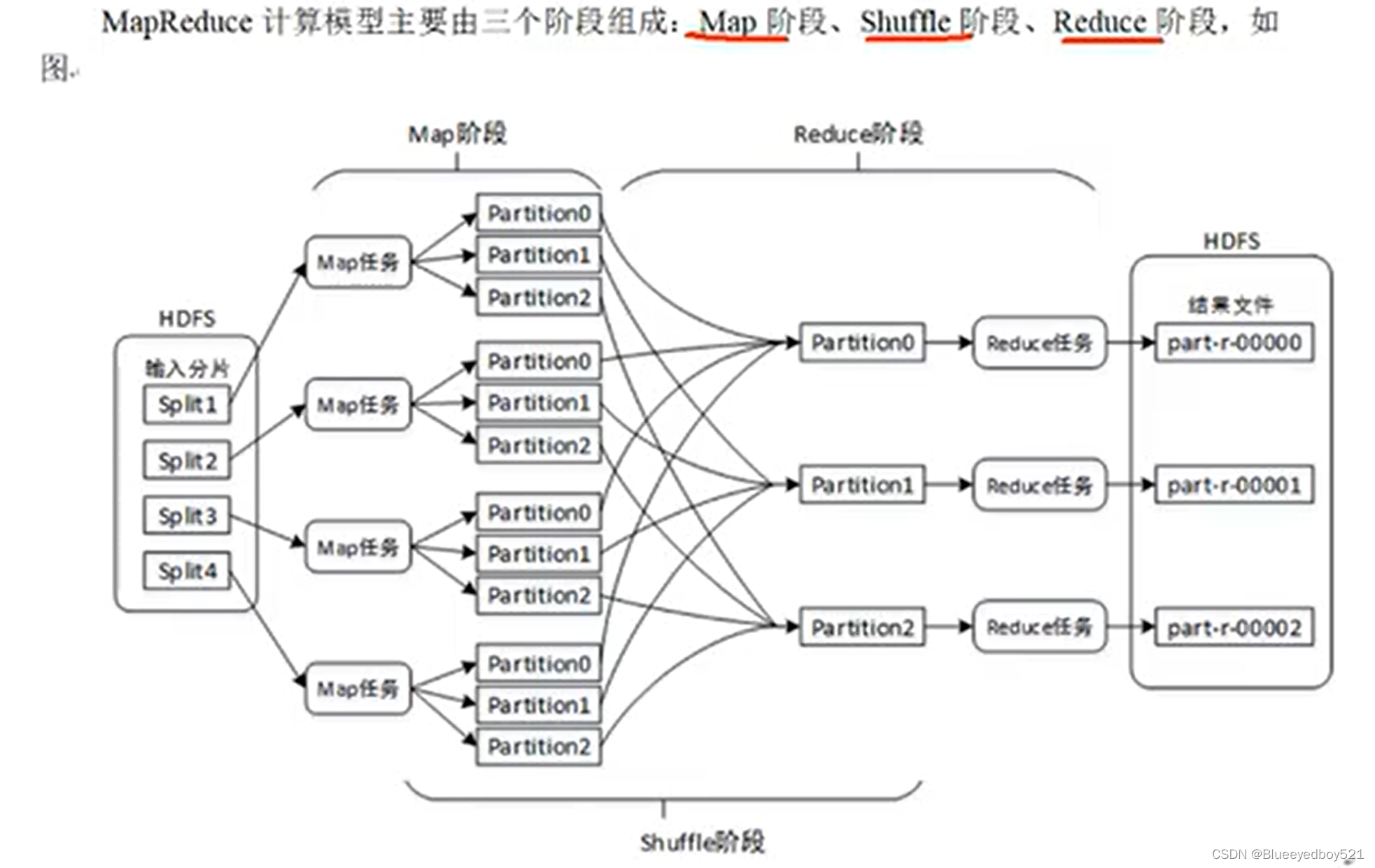
分区数量 == Reduce任务数量
切片机制
https://www.cnblogs.com/jhxxb/p/10790786.html
MapReduce 默认使用 TextInputFommat 进行明片,其机制如下。
(1)简单地按照文件的内容长度进行切片
(2)切片大小,默认等于Block大小,可单独设置
(3)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
例如:
(1)输入数据有两个文件:
filel.txt 320M
file2.txt 10M
(2)经过 FilelnputFormat(TextInputFormat为其实现类)的切片机制运算后,形成的切片信息如下:
filel.txt.splitl--0~128
filel.txt.split2--128~256
filel.txt.split3--256~320
file2.txt.splitl--0~10M
FilelnputFonmat 这个类会将文件在逻辑上进行划分,划分的每一个 split 切片将会被分配给一个Mapper 任务。即文件先被切分成split 切片,而后每一个 split 切片对应一个 Map 任务。.
对于 FilelmputFormmat 这个类,我们需要注意:FilelmputFormat 这个类只划分比 HDFS 的block块(128M)大的文件,所以File的FileInputFommat 划分的结果是这个文件或者是这个文件中的一部分.
如果一个文件的大小比block(18M)块大,FileInputFommat 将按照默认 128M 为一个切片进行划分。
如果一个文件的大小比 block(128M)块小,将不会被FileInputFommat 这个类进行逻辑上的划分,此时每一个小文件都会当一个split 切片并分配一个 Mapper 任务,导致效率低上,这也是Hadoop处理大文件的效率要比处理很多小文件的效率高的原因。
程序
WordCount执行流程
//第一步:指定文件的读取方式和读取路径
job.setInputFormatClass(TextInputFormat.class); // 表示按行执行
TextInputFormat.addInputPath(job, new Path(“hdfs://master:9000/wordcount”));
//TextInputFormat.addInputPath(job, new Path(“file:///D:\mapreduce\input”));
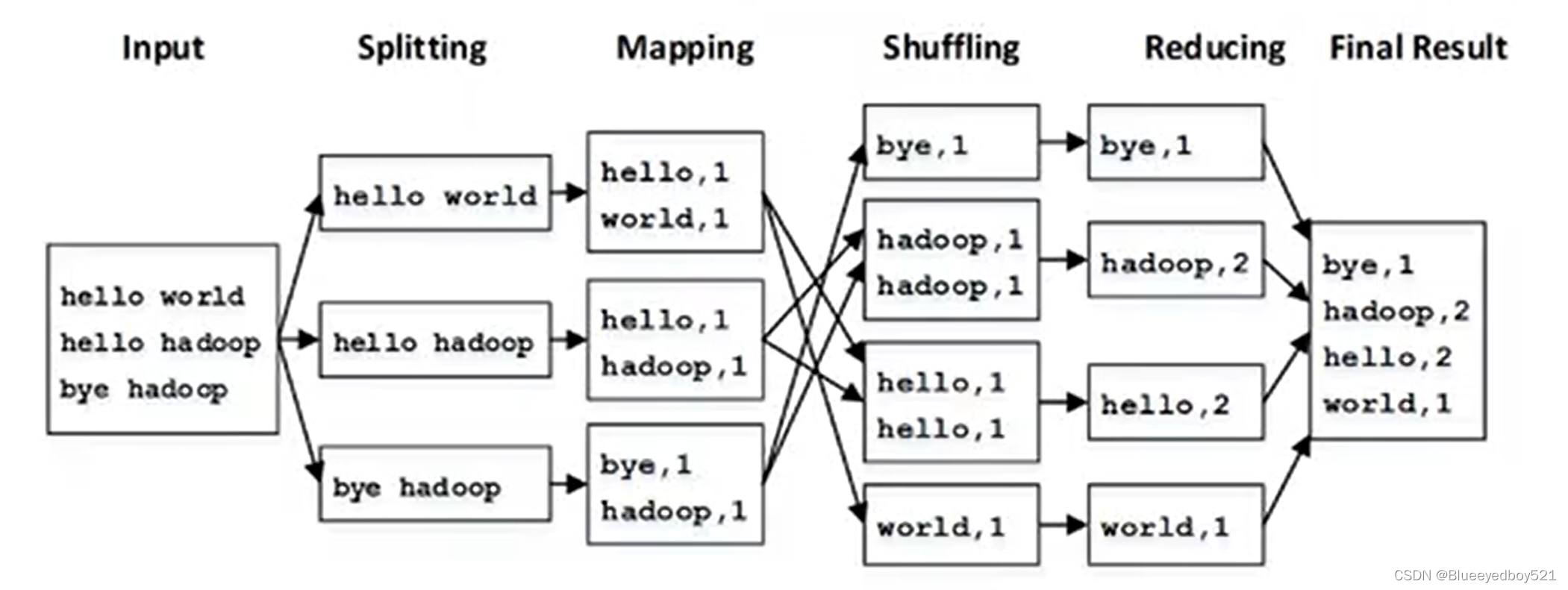
求平均值

版权归原作者 Blueeyedboy521 所有, 如有侵权,请联系我们删除。