
自从 Sora 发布以来,AI 视频生成的热度不减,社区中涌现了大量类 Sora 的开源项目。
前不久,快手开放了可灵视频生成模型的内测,不过可灵是闭源的,相信很多小伙伴还没拿到内测名额。
今天给大家分享一款开源的视频生成模型,来自阿里云团队,4月刚开源,目前已迭代到 V3 版本。
我们先来感受一下效果:
EasyAnimate-v3-DemoShow
项目简介
市面上的 AI 视频生成模型大都基于 Diffusion Transformer 结构,也即采用 Transformer 结构取代了 UNet 作为扩散模型的基线。
EasyAnimate 也不例外,它通过扩展 DiT 框架引入了运动模块,增强了对时间动态的捕捉能力,确保生成视频的流畅性和一致性。
功能简介:单张图像 + 文本描述,生成高分辨率的超长视频。

使用限制:目前的视频生成模型必须得上 GPU,不同配置下能生成的分辨率和时长如下图所示,大家可以参照自己的机器配置进行生成:
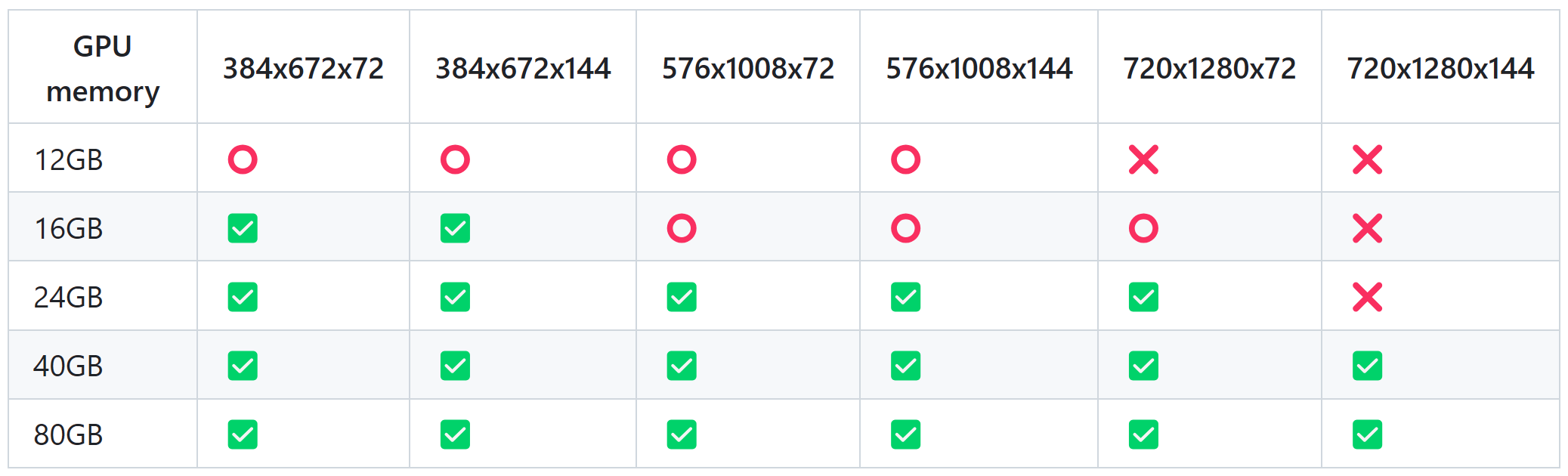
其中,✅ 代表可以在
low_gpu_memory_mode=False
下运行,⭕️ 可以在
low_gpu_memory_mode=True
下运行,❌ 无法运行。当然,
low_gpu_memory_mode=True
会把部分参数放到 CPU,运行速度较慢。此外,确保显卡支持 bfloat16。
部署实战
Docker 部署
这里我们选择 Docker 部署,因为无需配置本地环境,且有效实现了环境隔离,方便快速测试,用完即删。主打一个高效~
拉取镜像
终端执行如下命令拉取镜像:
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
注:该镜像有 19.8G,把项目所需环境都打包好了,下载得有一会儿。
进入容器
终端执行如下命令进入容器:
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 100g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
部分参数解释如下:
- –network host:使用宿主机的网络配置,使容器直接使用宿主机的网络,方便进行网络通信。
- –gpus all:允许容器使用所有可用的 GPU,如果需要指定特定编号的 GPU,修改为’“device=0,1”'。
- –security-opt seccomp:unconfined:禁用 seccomp 安全限制,允许容器执行更多系统调用,适用于需要较高权限的应用。
- –shm-size 200g:设置共享内存大小为 200GB,适合需要大量内存的应用,需要根据你的机器配置适当调整。
**切记:一定要指定
--shm-size
,如果不指定,Docker 默认的共享内存大小只有 64MB,这种应用是玩不转的,会报错提示内存不足。**
如何查看机器还剩多少内存(以 GB 为单位)?
$ free -h
total used free shared buff/cache available
Mem: 125Gi 6.4Gi 15Gi 39Mi 104Gi 118Gi
Swap: 2.0Gi 325Mi 1.7Gi
其中的
available
是可用内存。
下载代码和模型
git clone https://github.com/aigc-apps/EasyAnimate.git
cd EasyAnimate
mkdir models/Diffusion_Transformer
wget https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/EasyAnimateV3-XL-2-InP-512x512.tar -O models/Diffusion_Transformer/EasyAnimateV3-XL-2-InP-512x512.tar
cd models/Diffusion_Transformer/
tar -xvf EasyAnimateV3-XL-2-InP-512x512.tar
cd ../../
Gradio 应用展示
我们先在本地测试一下:
python predict_t2v.py
目前项目还在持续迭代中,如果遇到报错,需要查看一下代码和配置文件,并做相应修改,上述脚本采用的配置文件为:
config/easyanimate_video_slicevae_motion_module_v3.yaml
,需要在最后加上一行:
enable_multi_text_encoder: false
。
跑 384x672 分辨率的模型,显存大约需要占用 11.5G:
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.14 Driver Version: 550.54.14 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4080 On | 00000000:18:00.0 Off | N/A |
| 66% 64C P2 278W / 320W | 11503MiB / 16376MiB | 100% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
结果默认保存在
samples/easyanimate-videos
文件夹下。
root@ps:~/EasyAnimate# ls samples/easyanimate-videos/
00000001.mp4
因为我们是在容器中跑的代码, 如何把 docker 容器中的文件传到宿主机上查看呢?
需要使用 docker cp 命令,语法如下:
docker cp <container_id_or_name>:<path_in_container> <path_on_host>
# 举个例子
docker cp fea230d1bc40:/root/EasyAnimate/samples/easyanimate-videos/00000001.mp4 ./
最后,为了方便可视化展示,一键启动 Gradio WebUI 界面:
python app.py
浏览器中打开
127.0.0.1:7860
,下方红色箭头处选择下载好的模型:
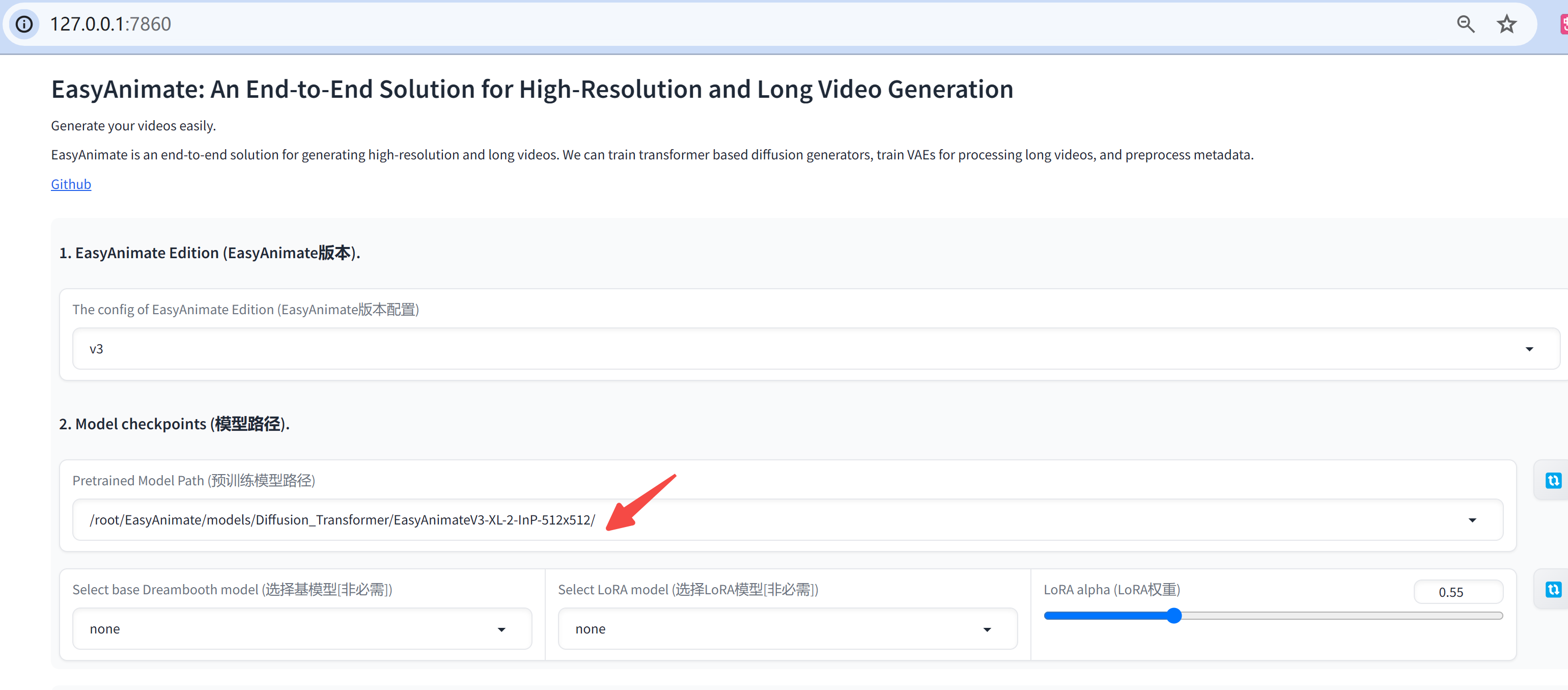
和 Stable Diffusion 的使用方式一致,填入正向和负向提示词,选择一张参考图,开始视频生成。
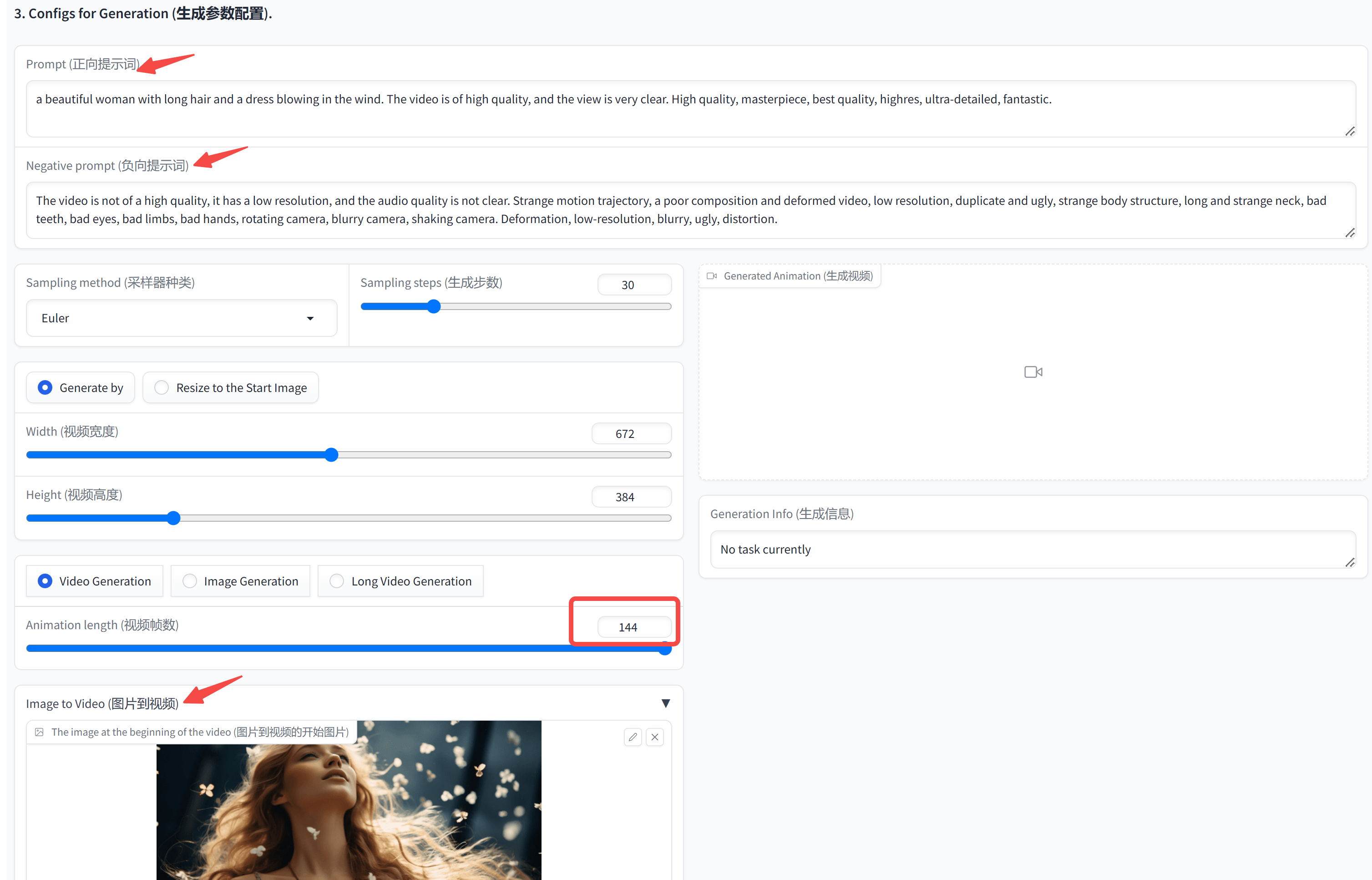
我的是 16G 的 4080 显卡,默认 24 FPS 共 144 帧,也就是 6S 的视频,大约需要 188s 能处理完成。
最终效果给大家展示下:
easyanimate_v3_test
目前来看,还不是特别稳定,期待官方的 V4 版本~
写在最后
不得不说,最近 AI 视频生成领域的进展也非常喜人,EasyAnimate 作为一款开源模型,在视频的流畅性和一致性方面,初步效果已经颇具潜力。
本文通过简单的Docker部署,带领大家快速上手体验。
对于探索 AI 视频生成的小伙伴来说,EasyAnimate 无疑是一个值得尝试的工具。
如果本文对你有帮助,欢迎点赞收藏备用!
版权归原作者 AI码上来 所有, 如有侵权,请联系我们删除。