
一 需求
这个案例的需求很简单
现在这里有一个文本wordcount.txt,内容如下
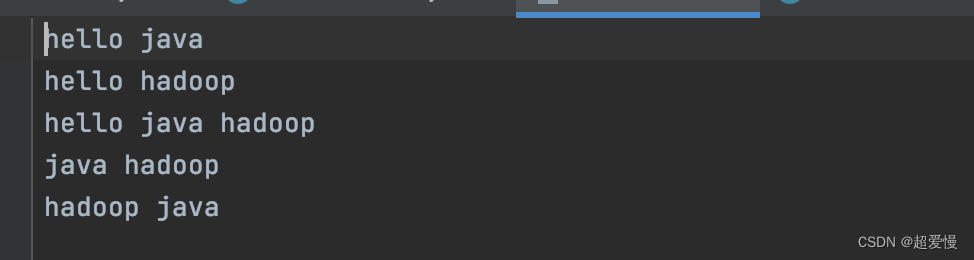
现要求你使用 mapreduce 框架统计每个单词的出现个数
这样一个案例虽然简单但可以让新学习大数据的同学熟悉 mapreduce 框架
二 准备工作
(1)创建一个 maven 工程,maven 工程框架可以选择quickstart
(2)在properties中添加 hadoop.version,导入依赖,pom.xml内容如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>maven_hadoop</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<hadoop.version>3.1.3</hadoop.version>
</properties>
</project>
(3)准备数据,创建两个文件夹 in,out(一个是输入文件,一个是输出文件),输入文件放在 in 文件夹中
三 编写 WordCountMapper 类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
// <0, hello java, hello, 1 >
// <0, hello java, java, 1 >
// alt + ins
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
Text text = new Text();
IntWritable intWritable = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
System.out.println("WordCountMap stage Key:"+key+" Value:"+value);
String[] words = value.toString().split(" "); // "hello java"--->[hello,java]
for (String word :
words) {
text.set(word);
intWritable.set(1);
context.write(text,intWritable); //<hello,1>,<java,1>
}
}
}
四 编写 WordCountReducer 类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReduce extends Reducer<Text, IntWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
System.out.println("Reduce stage Key:" + key + " Values:" + values.toString());
int count = 0;
for (IntWritable intWritable :
values) {
count+=intWritable.get();
}
LongWritable longWritable = new LongWritable(count);
System.out.println("ReduceResult key:"+key+" resultValue:"+longWritable.get());
context.write(key,longWritable);
}
}
五 编写WordCountDriver 类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
// 设置job的map阶段 工作任务
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置job的reduce阶段 工作任务
job.setReducerClass(WordCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 指定job map阶段的输入文件的路径
FileInputFormat.setInputPaths(job, new Path("D:\\bigdataworkspace\\kb23\\hadoopstu\\in\\wordcount.txt"));
// 指定job reduce阶段的输出文件路径
Path path = new Path("D:\\bigdataworkspace\\kb23\\hadoopstu\\out1");
FileSystem fileSystem = FileSystem.get(path.toUri(), conf);
if (fileSystem.exists(path))
fileSystem.delete(path,true);
FileOutputFormat.setOutputPath(job, path);
// 启动job
job.waitForCompletion(true);
}
}
本文转载自: https://blog.csdn.net/jojo_oulaoula/article/details/132565795
版权归原作者 超爱慢 所有, 如有侵权,请联系我们删除。
版权归原作者 超爱慢 所有, 如有侵权,请联系我们删除。