
文章目录
一.SQL语句简介
1.什么是SQL?
SQL(Structured Query Language):结构化查询语言
其实就是定义了操作所有关系型数据库的规则。每一种数据库操作的方式存在不一样的地方,称为“方言”
2.SQL分类
(1)DDL(Data Definition Language):数据库定义语言
用来定义数据库对象(数据库,表,列)。关键字:create,drop,alter等
(2)DML(Data Manipulation Language):数据库操作语言
用来对数据库表中的数据进行增删改。关键字:insert,delete,update等
(3)DQL(Data Query Language):数据查询语言
用来查询数据表中的记录(数据) 。关键字:select,where等
(4)DCL(Data Control Language):数据控制语言(用的不多,了解即可)
二.MySql常用数据类型

三.数据库操作
1.创建数据库
(1)使用指令创建数据库
CREATEDATABASEIFNOTEXISTS db1;
①创建数据库:
create database 数据库名称
②创建数据库,先判断不存在,再去创建
create database if not exists 数据库名称;
(2)创建一个使用utf8字符集的数据库
CREATEDATABASE db2 CHARACTERSET utf8;
(3)创建一个使用utf_8字符集,并带校对规则的数据库
CREATEDATABASE db3 CHARACTERSET utf8 COLLATE utf8_bin;
(4)校对规则utf8_bin区分大小,默认utf_8_general_ci 不区分大小写(如Tom和tom一样)
2.查询和删除数据库
(1)查看当前数据库服务器中的所有数据库
SHOWDATABASES;
(2)查看创建的db2数据库的定义信息
SHOWCREATEDATABASE db2;
(3)在创建数据库,表的时候,为了避免关键字,可以使用反引号解决(比如数据库名为关键字create)
CREATEDATABASE`create`;
(4)删除数据库
DROPDATABASE db1;
3.备份/恢复数据库
(1)备份,要在DOS下执行指令
mysqldump -u 用户名 -p -B 数据库1,数据库2,数据库n > 文件名.sql;
mysqldump -u root -p -B db2 > d:\\db2.sql;
(2)恢复数据库(注意:要在DOS中进入MySQL命令行再执行)
source d:\\db2.sql;
补充(备份库中的表):mysqldump -u 用户名 -p 数据库 表1 表2 表n > 文件名.sql;
四.表操作
1.创建表
CREATETABLE table_name(
field1 datatype,
field2 datatype,
field3 datatype
)characterset 字符集 collate 校对规则 engine 存储引擎
(1)field:指定列名
(2)datatype:指定列类型(字段类型)
(3)character set:如果不指定则为所在数据库字符集
(4)collate:如果不指定则为所在数据库校对规则
(5)engine:引擎
2.修改/查看表
(1)添加列
ALTER TABLE tablename
ADD (column1 datatype [表达式语句]
,column2 datatype [表达式语句);
-- t_user表上新增一个varchar类型的image列(要求在email后面)ALTERTABLE t_user
ADD image VARCHAR(32)NOTNULLDEFAULT''AFTER email;
(2)修改列
ALTER TABLE tablename
MODIFY (column1 datatype [表达式语句];
,column2 datatype [表达式语句))
(3)删除列
ALTER TABLE tablename
DROP column;
(4)修改表名
RENAME TABLE 表名 to 新表名;
(5)修改表字符集
alter table 表名 character set 字符集;
(6)desc 表名; // 查看表的结构
五.CRUD语句
1.Insert语句
insertinto 表名(列名1,列名2,...列名n)values(值1,值2,...,值n);
细节:
(1)插入的数据要与字段的数据类型相同,比如把‘abc’添加到int类型会报错
(2)数据的长度应在列的规定范围内,例如:不能将一个长度为80的字符串加入到长度为40的列中
(3)在values中列出的数据位置必须与被加入的列的排列位置相对应
(4)字符和日期类型数据应包含在单引号中
(5)列可以插入空值(前提是该字段允许为空)
(6)如果是给表中的所有字段添加数据,可以不写前面的字段名称
insertinto 表名 values(值1,值2,...值n);
(7)默认值的使用,当不给某个字段值时,如果有默认值就会添加,否则报错
2.Delete语句
deletefrom 表名 [where 条件];
(1)如果不加条件,则删除表中所有记录
(2)如果要删除所有记录
①
delete from 表名;
– 不推荐使用。有多少条记录就会执行多少次删除操作
②
TRUNCATE TABLE 表名;
– 推荐使用,效率更高,先删除表,然后再创建一张一样的表
3.Update语句
update 表名 set 列名1 = 值1,列名2 = 值2,…[where 条件];
(1)set子句指示要修改哪些列和要赋予那些值
(2)where子句指定应更新哪些列;如果没有where子句,则更新所有的行
(3)如果需要修改多个字段,可以通过set 字段1=值1,字段2=值2…
4.Select语句
4.1 语法:
select
字段列表
from
表名列表
where
条件列表
groupby
分组字段
having
分组之后的条件
limit
分页限定
4.2 基础查询
(1)多个字段的查询
select 字段名1,字段名2...from 表名;
注意:如果查询所有字段,则可以使用*来替代字段列表
(2)去除重复:distinct
(4)起别名:as(as也可以省略)
select columnname as 别名 from 表名;
4.3 排序查询
(1)语法:order by 子句
select * from 表名 order by 排序字段1 排序方式1,排序字段2 排序方式2..
.
(2)排序方式:
①ASC:升序,默认的
②DESC:降序
(3)order by 子句应位于select语句的结尾
4.4 分页查询
(1)语法:limit 开始的索引,每页查询的条数
(2)公式:开始的索引 = (当前的页码 - 1) * 每页显示的条数
SELECT*FROM t_product WHERESTATUS=1ORDERBY priority DESCLIMIT0,4;
(3)limit是一个MySQL“方言”
六.函数
1.统计函数count
(1)count:返回行的总数
selectcount(*)|count(列名)from table_name [where 条件]
(2)count()和count(列名)的区别?
①count():返回满足条件的记录的行数
②count(列名):统计满足条件的某列有多少个,但是会排除 null
2.合计函数max/min
selectmax(列名)from 表名 [where 条件]
3.分组统计
(1)使用group by子句对列进行分组
select column1,column2,column3 ...from 表名 groupbycolumn;
(3)使用having子句对分组后的结构进行过滤
select column1,column2,column3...from 表名
groupbycolumnhavingAVG(sal)<2000;
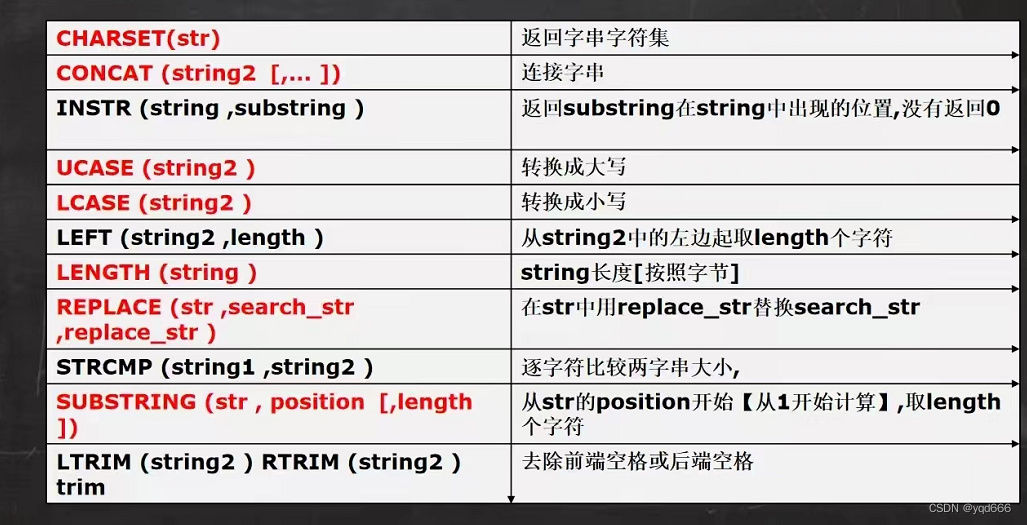
4.字符串相关函数
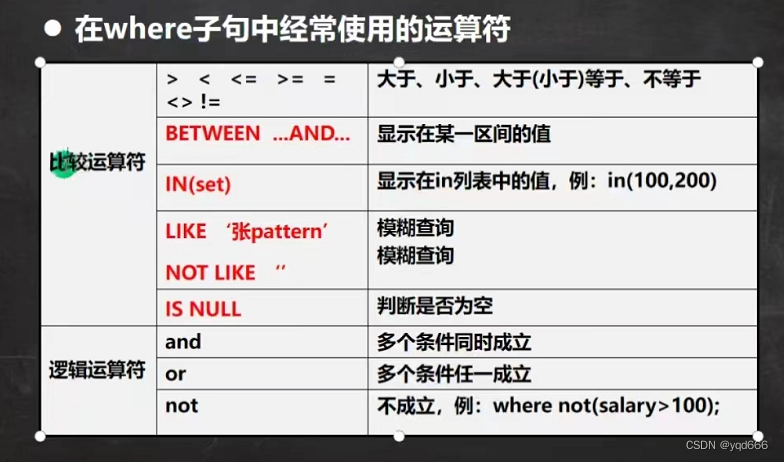
七.索引
1.索引的原理
(1)没有索引为什么会慢?
因为需要全表扫描
(2)使用索引为什么会快?
形成一个索引的数据结构,比如二叉树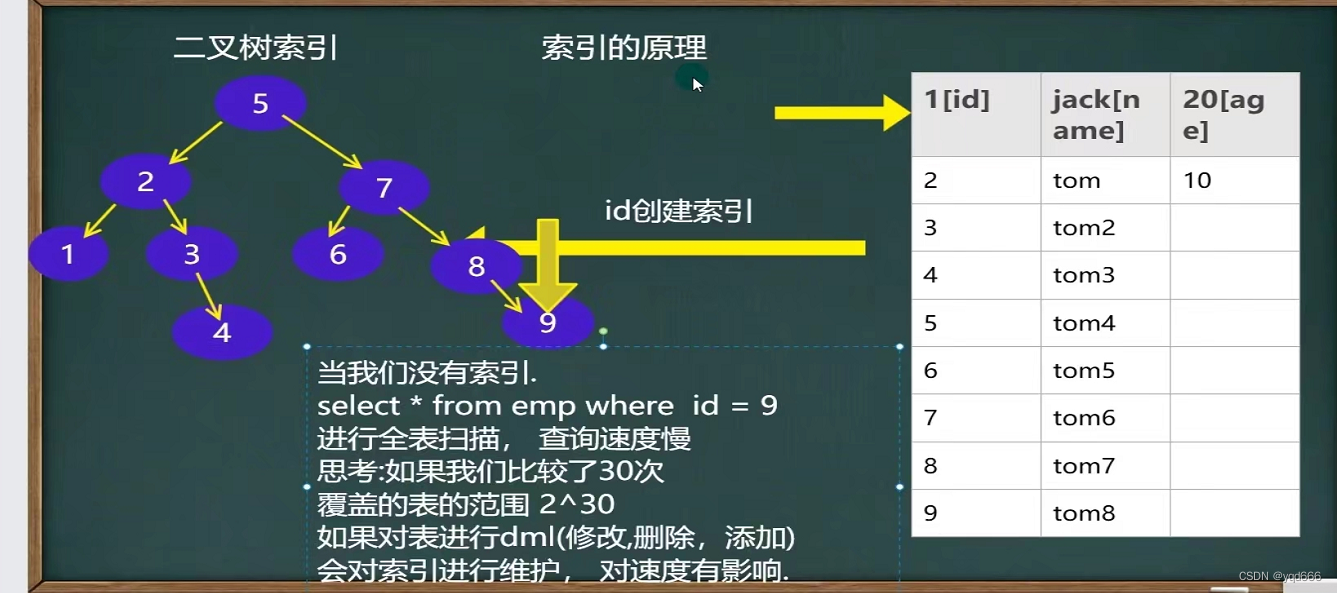
(3)索引的代价
①磁盘占用
②影响dml语句(update、delete、insert)语句的效率
但是我们的项目中主要为查询select语句,所以可以忽略
2.索引的类型
(1)主键索引,主键自动成为主索引(类型Primary key)
(2)唯一索引(UNIQUE)
(3)普通索引(INDEX)
(4)全文索引(FULLTEXT)[适合于MyISAM]
开发中考虑使用:全文搜索Slor和ElasticSearch(ES)
3.创建索引
-- 创建表CREATETABLE t25 (id INT,`name`VARCHAR(32));-- 3.1 查询表中是否有索引SHOW INDEXES FROM t25 ;-- 3.2添加索引-- (1)添加唯一索引CREATEUNIQUEINDEX id_index ON t25 (id);-- (2)添加普通索引方式1CREATEINDEX id_index ON t25 (id);-- (2)添加普通索引方式2ALTERTABLE t25 ADDINDEX id_index (id);-- 如何选择-- 1.如果某列的值,是不会重复的,则优先考虑使用unique索引,否则使用普通索引-- (3)添加主键索引CREATETABLE t26 (id INT,`name`VARCHAR(32));ALTERTABLE t26 ADDPRIMARYKEY(id);
4.删除索引
-- 删除索引DROPINDEX id_index ON t25;-- 删除主键索引ALTERTABLE t26 DROPPRIMARYKEY;-- 修改索引,先删除,再添加新的索引
5.查询索引
-- 查询索引-- 方式1SHOWINDEXFROM t25;-- 方式2SHOW INDEXES FROM t25;-- 方式3SHOWKEYSFROM t25;-- 方式4(索引字段key的值为MUL,该方法没有前面的方法查询结果详细)DESC t25;
6.哪些列上适合使用索引:
(1)较频繁的作为查询条件字段的应该建立索引
(2)唯一性太差的字段不适合单独创建索引,既使频繁作为查询条件
例如性别:select * from emp where sex = ‘男’;
(3)更新非常频繁的字段不适合创建索引
(4)不会出现在where子句中的字段不该创建索引
八.多表查询
下面都已这两张表为例子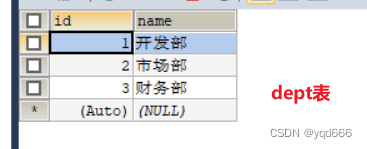
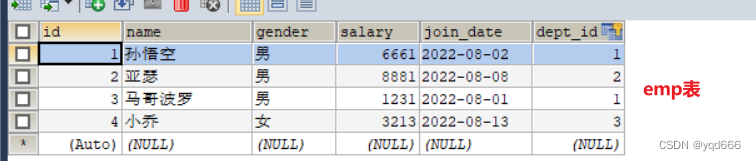
1.内连接查询
(1)隐式内连接:使用where条件消除无用数据
例子:
– 查询所有员工信息和对应的部门信息
SELECT*FROM emp,dept WHERE emp.`dept_id`= dept.`id`;

– 查询员工表的名称、性别,部门表的名称
select emp.`name`,emp.`gender`,dept.`name`from emp,dept where emp.`dept_id`= dept.`id`
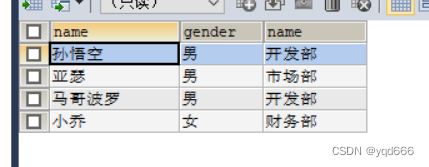
(2)显示内连接
语法:select 字段列表 from 表名1 [inner] join 表名2 on 条件
例如:
-- 查询所有员工信息和对应的部门信息SELECT*FROM emp INNERJOIN dept ON emp.`dept_id`= dept.`id`;-- 或者select*from emp join dept on emp.`dept_id`= dept.`id`;
2.外链接查询(以下面stu和exam两张表为例)
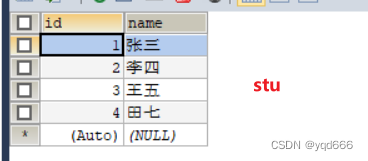
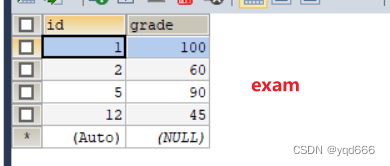
(1)左外链接
①语法:select 字段列表 from 左表 left [outer] join 右表 on 条件;
②查询的是左表所有数据及其交集的部分。
③例子:
-- 查询所有人的成绩,如果没有成绩,也要显示该人的姓名和id,成绩显示为空SELECT stu.`id`,stu.`name`,exam.`grade`FROM stu LEFTJOIN exam ON stu.`id`=exam.`id`;

(2)右外链接:
①语法:select 字段列表 from 左表 right [outer] join 右表 on 条件;
②查询的是右表所有数据及其交集的部分
③例子:
-- 显示所有成绩,如果没有名字匹配显示为空SELECT stu.`id`,stu.`name`,exam.`grade`FROM stu RIGHTJOIN exam ON stu.`id`=exam.`id`;

3.自连接查询
(1)自连接的特点:
①把同一张表当做两张表使用
②需要给表取别名(表名 表列名)
③列名不明确,可以指定列的别名(列名 as 列的别名)
(2)例子:
-- 要求:显示公司员工名字和他的上级的名字select
worker.ename as'职员名',
boss.ename as'上级名'from
emp worker,
emp boss
where
worker.mgr = boss.empno;
九.事务
1.什么是事务:
事务用于保证数据的一致性,它由一组相关的dml语句组成,该组的dml语句要么全部成功,要么全部失败。如:转账就要用事务来处理,用以保证数据的一致性。
2.事务和锁
当执行事务操作时(dml语句),MySQL会在表上加锁,防止其他用户改变表的数据。
3.mysql数据库控制台事务的几个重要操作
(1)start transaction – 开始一个事务
(2)savepoint 保存点名 – 设置保存点
(3)rollback to 保存点名 – 回退事务
(4)rollback – 回退全部事务
(5)commit – 提交事务,所有的操作生效,不能回退
4.事务的隔离级别
多个事务之间是隔离的,相互独立的。但是如果多个事务操作同一批数据,则会引发一些问题,设置不同的隔离级别就可以解决这些问题。
5.存在问题
(1)脏读:当一个事务读取到另一个事务尚未提交的改变(update,insert,delete)时,产生脏读
(2)不可重复度:不可重复读是指在事务1内,读取了一个数据,事务1还没有结束时,事务2也访问了这个数据,修改或删除了这个数据,并提交。紧接着,事务1又读取这个数据。由于事务2的修改,那么事务1两次读到的数据可能是不一样的,因此称为是不可重复读。
(事务1想读取开启事务那一刻的数据,结果却读到了修改或删除后的数据)
(3)幻读:幻读是指在事务1内,读取了一个数据,事务1还没有结束时,事务2也访问了这个数据,添加了这个数据,并提交。紧接着,事务1又读取这个数据。由于事务2的添加,那么事务1两次读到的数据可能是不一样的,因此称为是幻读。
(事务1想读取事务开启那一刻的数据,结果却读到了添加后的数据)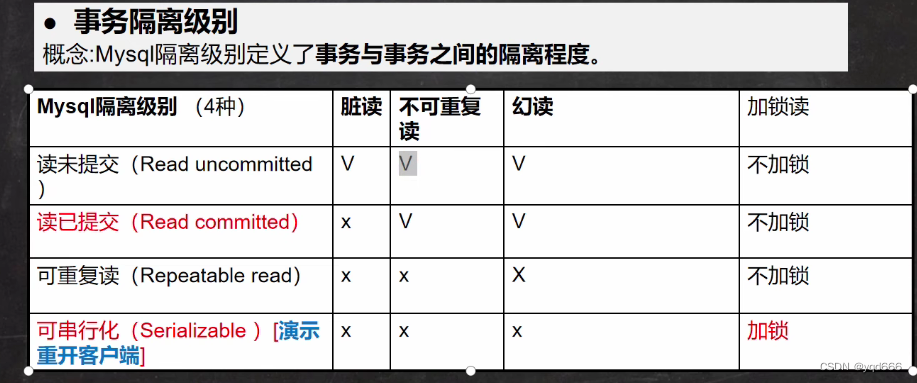
注意:
(1)Oracle默认为读已提交,MySQL默认为可重复读
(2)加锁:如果他发现一个事务中有一张表正在操作,没有提交;另一个事务操作时,他会卡在这个地方,他不会操作
6.存储引擎
(1)InnoDB:
①支持事务
②支持外键
③支持行级锁
(2)MyISAM
①添加速度快
②不支持外键和事务
③支持表级锁
(3)memory
①数据存储在内存中(关闭mysql服务,数据丢失,但表还在)
②执行速度快(没有IO读写)
③默认支持索引(hash表)

版权归原作者 yqd666 所有, 如有侵权,请联系我们删除。