
前言
本篇文章主要整理Hive数据倾斜的解决指南
一、什么是数据倾斜
数据倾斜是指在并行计算模式下(map-reduce框架,数据被切分为N个片段,分发到不同的计算节点上,单独计算),部分节点处理的数据量远大于其他节点,造成该节点计算压力过大,从而导致少数节点的运行时长远远超过其他节点的平均运行时长,进而影响整体任务产出时效,造成任务延迟,这个现象就是数据倾斜。
简单来说,**数据倾斜是大量的相同key被partition分配到一个分区里**,造成了 ' 一个人累死,其他人闲死 ' 的情况,**数据倾斜的本质就是计算节点间的数据分配不均衡**。
二、发生数据倾斜的表现
数据倾斜一般出现在 join/group by/distinct 等聚合操作时,大量的相同key被分配到少量的 reduce 去处理。导致绝大多数task执行得都非常快,但个别 task执行的极慢,原本能正常执行的作业,某天突然爆出 OOM(内存溢出)异常。**任务进度长时间维持在 99%**

任务监控页面,发现只有少量(1 个或几个)reduce 子任务未完成。因为其处理的数据量和其他 reduce 差异过大。单一 reduce 的记录数与平均记录数差异过大,通常可能达到 3 倍甚至更多。 最长时长远大于平均时长。可以查看具体 job的**reducer counter 计数器**协助定位。
2.1 MapReduce任务
主要表现在reduce阶段长时间维持在99%(或100%),检查任务监控页面后发现:
- 仅有1个或几个reduce子任务卡住
- 各种container容器报错OOM
- 未完成的reduce子任务处理的数据量与远远超过其它正常的reduce
2.2 Spark任务
- 绝大多数task执行得都非常快,但个别task执行的极慢
- 单个Executor执行时间特别久,整体任务卡在某个stage不能结束
三、如何定位发生数据倾斜的代码

(1)通过观察 log view,配合explain执行计划以及log执行日志,去定位数据倾斜发生在第几个stage中(定位运行最长的job stage),进一步查看该stage各instance实例的执行时长,找到耗时最长的instance的输出日志StdOut,然后再进一步定位发生倾斜的sql代码,引发倾斜的算子如下:
(2)数据倾斜只会发生在shuffle中,常用的可能会触发 shuffle 操作的算子有:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition 等。出现数据倾斜时,可能就是代码中使用了这些算子。
四、发生数据倾斜的原因
从map-shuffle-reduce阶段出发,分析发生倾斜的原因
Map阶段:在map阶段出现倾斜的原因一种是上游数据分布不均,小文件过多。另一种情况是在map端聚合的时候,某些mapper读取的文件找那个,某些值量级过导致长尾。
Join阶段:Join阶段最容易出现数据倾斜,大部分情况是在关联的时候出现热点值导致的数据倾斜,或者大小表关联导致的数据倾斜等。
Reduce阶段:在map阶段聚合导致的key值分布不均匀。join阶段产生很多null值,被分发到同一个reduce实例导致的数据倾斜,动态分区导致小文件过多产生的数据倾斜。
总结,无论是MR还是Spark任务进行计算的时候,一旦触发Shuffle动作,所有相同key的值就会拉取到一个或几个节点上,就容易发生单个节点处理数据量爆增的情况。此外,根据explain执行计划,得出Hive的执行是分阶段的,当前stage阶段的map处理数据量的差异取决于上一个 stage 的 reduce 输出,所以如何将数据均匀的分配到各个reduce中,就是解决数据倾斜的根本所在。

** 一般而言,导致数据倾斜的因素往往是以下几种情况:**
3.1 key分布不均匀
**3.1.1 **某些key存在大量相同值
3.1.2 存在大量异常值或空值
当数据仓库中某个字段存在大量空值时,这些空值会在数据计算和聚合操作中引起不平衡的情况。例如,在使用聚合函数(如SUM、COUNT、AVG等)对该字段进行计算时,空值并不会被包括在内,导致计算结果与实际情况不符。
3.2 业务数据本身的特性
例如某个城市订单量大幅提升几十倍甚至几百倍,对该城市的订单统计聚合时,容易发生数据倾斜。
3.3 SQL语句本身就有数据倾斜
两个表中关联字段存在大量空值,或是关联字段的数据不统一导致的倾斜。
3.4 建表时考虑不周
例如不合理的分区策略:建表分区时没有考虑数据的实际分布,导致分区不均匀。
四、触发数据倾斜的SQL操作
- Join
- GroupBy
- Count(Distinct)
- ROW_NUMBER(TopN)
- 动态分区(待补充)
其中出现的频率排序为**
join > groupby > count(distinct) > row_number > 动态分区。
**
五、数据倾斜的解决方案
5.1 Map长尾优化
5.1.1 Map读取数据量不均匀
上游数据分布不均,小文件过多,使用下面的参数设置小文件合并,让每个mapper实例读取的数据量大致相同。
#Map前进行小文件合并
#CombineHiveInputFormat底层是 Hadoop的CombineFileInputFormat方法,该方法是在mapper中将多个文件合成一个split切片作为输入
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- 默认开启
#每个Map最大的输入数据量(这个值决定了合并后文件的数量,会影响mapper数量)
set mapred.max.split.size=256*1000*100; -- 默认是256M
当出现文件过大,mapper实例过少会导致map端读取数据很慢,此时可以**适量缩小 mapred.max.split.size**的值来增加map实例的数量,从而提升数据读取效率。
5.2 Join长尾优化
5.2.1 关联键存在空值
场景:日志表log中user_id常会有信息丢失的问题,如果直接取其中的user_id 和users 用户表中的user_id 关联,会出现数据倾斜的问题。
解决方法一:给空值进行随机赋值、增加reduce个数
sql优化如下:
#===空值替换成随机值,不影响计算结果,可以将空值打散到多个joinner中
select *
from log a
left join users b
on coalesce(a.user_id, rand() * 9999) = b.user_id;
#===同时增加reduce个数,提高并行度
set mapred.reduce.tasks = [num]
5.2.2 大表关联小表
优化方案一:使用Map Join
1)Map Join工作机制
大表关联小表时,可以使用mapjoin hint ,使用hadoop中DistributedCache(分布式缓存)将小表广播到每个map任务节点,转换成哈希表加载到内存中**,**之后在mapper端和大表的分散数据做笛卡尔积,直接输出结果。

2)Map Join Hint语法
select /*+ mapjoin(b,c)*/ --mapjoin hint 定义小表,多个小表用逗号分隔
...
from t0 a
left join t1 b
on a.id = b.id
left join t2 c
on a.id = c.id;
# MapJoin中多个小表用半角逗号(,)分隔,例如/*+ mapjoin(a,b,c)*/。
3)Map Join的特点
- 要使用hadoop中的DistributedCache(分布式缓存)把小数据分布到各个计算节点,每个map节点都要把小数据库加载到内存,按关键字建立索引。
- Map Join没有reduce任务,所以map直接输出结果,即有多少个map任务就会产生多少个结果文件
- Hive3.1.2版本已经对Map Join进行了优化,小表放在左边和右边已经没有区别;参与Map Join的小表的行数不超过 2 万条,大小不超过 25M为宜
- MapJoin在Map阶段会将指定表的数据全部加载在内存中,因此指定的表仅能为小表且表被加载到内存后占用的总内存不得超过512 MB(默认)。由于MaxCompute是压缩存储,因此小表在被加载到内存后,数据大小会急剧膨胀。
4)参数配置
#设置自动选择 Mapjoin,默认为true
set hive.auto.convert.join = true;
#大表小表的阈值设置(默认25M以下认为是小表)
set hive.mapjoin.smalltable.filesize = 25*1000*1000;
5.2.3 大表关联大表
在下面这个表中,
eleme_uid
中存在很多热点数据,容易发生数据倾斜
SELECT
eleme_uid,
...
FROM (
SELECT
eleme_uid,
...
FROM <viewtable>
)t1
LEFT JOIN(
SELECT
eleme_uid,
...
FROM <customertable>
) t2
on t1.eleme_uid = t2.eleme_uid;
可以通过如下四种方法来解决:
序号方案说明方案一手动切分热点值将热点值分析出来后,从主表中过滤出热点值记录(倾斜数据)单独MapJoin,再将剩余的非热点值记录进行普通的MergeJoin,最后将两份结果集进行union all合并方案二
Bucket Join
分桶join方案三
SMB Join
分桶join且sort排序方案四设置SkewJoin参数set hive.optimize.skewjoin=true;方案五SkewJoin Hint使用Hint提示:
/*+ skewJoin(<table_name>[(<column1_name>[,<column2_name>,...])][((<value11>,<value12>)[,(<value21>,<value22>)...])]*/
。SkewJoin Hint的方式相当于多了一次找倾斜Key的操作,会让Query运行时间加长;如果用户已经知道倾斜Key了,就可以通过设置SkewJoin参数的方式,能节省一些时间
优化方案一:手动切分热值
将热点值分析出来后,从主表中过滤出热点值记录,先进行MapJoin,再将剩余非热点值记录进行MergeJoin,最后合并两部分的Join结果。具体可以参考如下代码示例:
SELECT
/*+ MAPJOIN (t2) */
#---第二步:对过滤出来的热点表单独进行MapJoin
eleme_uid,
...
FROM (
SELECT
eleme_uid,
...
FROM <viewtable>
#---第一步1:将热点值eleme_uid从主表中过滤出来
WHERE eleme_uid = <skewed_value>
)t1
LEFT JOIN(
SELECT
eleme_uid,
...
FROM <customertable>
#---第一步2:将热点值eleme_uid从主表中过滤出来
WHERE eleme_uid = <skewed_value>
) t2
on t1.eleme_uid = t2.eleme_uid
#---第四步:将两端join结果集进行union all合并
UNION ALL
#---第三步:非热点数据做普通的merge join
SELECT
eleme_uid,
...
FROM (
SELECT
eleme_uid,
...
FROM <viewtable>
WHERE eleme_uid != <skewed_value>
)t3
LEFT JOIN(
SELECT
eleme_uid,
...
FROM <customertable>
WHERE eleme_uid != <skewed_value>
) t4
on t3.eleme_uid = t4.eleme_uid
优化方案二:使用****Bucket Join
如果使用上述方案一,过滤出的热点表t2依旧是一张大表(不满足mapJoin小表的数据量限制的话)这种场景下,可以将两张表的数据构建为桶表进行Bucket Map Join,避免数据倾斜。
- 语法:clustered by column
- 参数设置:set hive.optimize.bucketmapjoin = true;
- 要求:分桶字段 = Join字段 ,桶的个数相等或者成倍数
优化方案三:使用****Sort Merge Bucket Join
** Sort Merge Bucket Join:基于有序的数据Join**
- 语法:clustered by column sorted by (column )
- 参数设置:
set hive.optimize.bucketmapjoin = true;
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
- 要求:分桶字段 = 排序字段= Join字段 ,两表的桶的个数相等或者成倍数
- 举例:
# 创建分桶表 bigtable_buck1
create table bigtable_buck1(
id bigint,
t bigint,
uid string,
keyword string,
url_rank int,
click_num int,
click_url string
)
clustered by(id)
sorted by(id)
into 6 buckets
row format delimited fields terminated by '\t';
# 加载数据
load data local inpath '/opt/module/data/bigtable' into table
bigtable_buck1;
#创建分桶表bigtable_buck2,分桶数和bigtable_buck1的分桶数为倍数关系
create table bigtable_buck2(
id bigint,
t bigint,
uid string,
keyword string,
url_rank int,
click_num int,
click_url string
)
clustered by(id)
sorted by(id)
into 6 buckets
row format delimited fields terminated by '\t';
#加载数据
load data local inpath '/opt/module/data/bigtable' into table
bigtable_buck2;
#================ SMB Join调优步骤
#设置参数
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
# SMB Join
insert overwrite table jointable
select b.id,
b.t,
b.uid,
b.keyword,
b.url_rank,
b.click_num,
b.click_url
from bigtable_buck1 s
join bigtable_buck2 b
on b.id = s.id;
优化方案四:使用Skew Join
Skew Join是Hive中一种专门为了避免数据倾斜而设计的特殊的Join过程。这种Join的原理是将Map Join和Reduce Join进行合并,如果某个值出现了数据倾斜,就会将产生数据倾斜的数据单独使用Map Join来实现其他没有产生数据倾斜的数据由Reduce Join来实现,这样就避免Reduce Join中产生数据倾斜的问题,最终将Map Join的结果和Reduce Join的结果进行Union合并。相关参数配置:
#-- 开启运行过程中skewjoin
set hive.optimize.skewjoin=true;
#-- 如果这个key的出现的次数超过这个范围
set hive.skewjoin.key=100000;
#-- 在编译时判断是否会产生数据倾斜
set hive.optimize.skewjoin.compiletime=true;
#-- 不合并,提升性能
set hive.optimize.union.remove=true;
#-- 如果Hive的底层走的是MapReduce,必须开启这个属性,才能实现不合并
set mapreduce.input.fileinputformat.input.dir.recursive=true;
优化方案五:使用SkewJoin Hint
- 语法:
select /*+ skewJoin(<table_name>[(<column1_name>[,<column2_name>,...])][((<value11>,<value12>)[,(<value21>,<value22>)...])]*/
在**
select
语句中使用上述的Hint提示才会执行MapJoin**,其中
table_name
为倾斜表名,
column_name
为倾斜列名,
value
为倾斜Key值。使用示例如下。
- 举例:
#=========性能效率 方法1 < 方法2 <方法3
#=========下面三个级别的hint,指定热点信息越详细,效率越高。
#-- 方法1:Hint表名(注意Hint的是表的别名)。
select /*+ skewjoin(a)*/ ... from t0 a join t1 b on a.id = b.id and a.code = b.code;
#-- 方法2:Hint表名和认为可能产生倾斜的列,下面认为a表的id和code列 存在倾斜
select /*+ skewjoin(a(id,code))*/ ... from t0 a join t1 b on a.id = b.id and a.code = b.code;
#-- 方法3:Hint表名和列,并提供产生倾斜的列的值,如果是string类型需要加引号,
#--此案例 认为 (a.id=1 and a.code='xxx') 和 (a.id=3 and a.code='yyy') 的值出现倾斜
select /*+ skewjoin(a(id,code)((1,'xxx'),(3,'yyy')))*/ ... from t0 a join t1 b on a.id = b.id and a.code = b.code;
ps: SkewJoin Hint方法直接指定值的处理效率比手动切分热值方法和设置SkewJoin参数方法高
5.2.4 大表关联中表
优化方案一:使用Distributed MapJoin
1)Distributed MapJoin工作机制
Distributed MapJoin是MapJoin的升级版,适用于大表Join中表的场景,核心目的是为了减少大表侧的Shuffle和排序。
2)Distributed MapJoin Hint语法
select /*+distmapjoin(<table_name>(shard_count=<n>,replica_count=<m>))*/

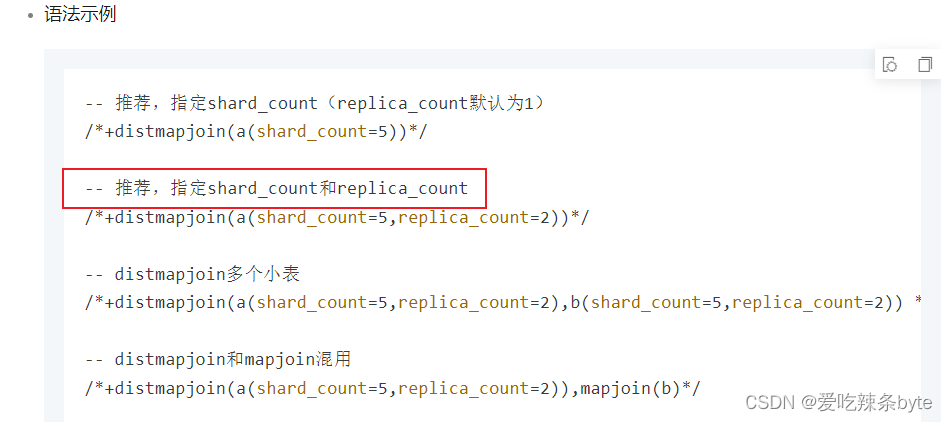
3)注意事项:
- Join两侧的表数据量要求不同,大表侧数据在10 TB以上,中表侧数据在[1 GB, 100 GB]范围内。
- SQL任务运行时间在20分钟以上,建议使用Distributed MapJoin进行优化。
4)sql举例:
#========案例:如下示例中t0为大表,t1为中表
SELECT /*+distmapjoin(t1)*/
request_datetime
,host
,URI
,eagleeye_traceid
from <viewtable>
t0
LEFT join (
SELECT
traceid,
eleme_uid,
isLogin_is
from <servicetable>
where ds = '${today}'
AND hh = '${hour}'
) t1 on t0.eagleeye_traceid = t1.traceid
WHERE ds = '${today}'
AND hh = '${hour}'
5.3 Reduce长尾优化
5.3.1 GroupBy数据倾斜
如果分组字段本身存在大量重复值(该字段值也叫做热点key值),group by底层走shuffle,分组聚合会出现数据倾斜的现象,可以使用如下三种方案解决:
序号方案说明方案一开启Map端聚合set hive.map.aggr=true;方案二数据倾斜时自动负载均衡set hive.groupby.skewindata = true;方案三添加随机数,两阶段聚合热点key加随机数,阶段拆分,两阶段聚合
优化方案一:开启Map端聚合
#--开启Map端聚合,默认为true
set hive.map.aggr = true;
#--在Map 端预先聚合操作的条数
set hive.groupby.mapaggr.checkinterval = 100000;
该参数可以将顶层的聚合操作放在 Map 阶段执行,从而减轻shuffle清洗阶段的数据传输和 Reduce阶段的执行时间,提升总体性能
** 优化方案二:**数据倾斜时自动负载均衡
#---有数据倾斜的时候自动负载均衡(默认是 false)
set hive.groupby.skewindata = true;
开启该参数以后,当前程序会自动通过两个MapReduce来运行
- 第一个MapReduce自动进行随机分布到Reducer中(负载均衡),每个Reducer做部分聚合操作,输出结果
- 第二个MapReduce将上一步聚合的结果再按照业务(group by key)进行处理,保障相同的key分发到同一个reduce做最终聚合。
** 该参数的优化原理是:将M->R阶段 拆解成 M->R->R阶段**
引入两级reduce:
- 第一阶段的shuffle key = group key + 随机数,将热点数据打散,多个reduce并发做部分聚合;
- 第二阶段的shuffle key = group key,保障相同key分发到同一个reduce做最终聚合;
优化方案三:添加随机数,两阶段聚合
#===============优化前
insert overwrite table tblB partition (dt = '2022-10-19')
select
cookie_id,
event_query,
count(*) as cnt
from tblA
where dt >= '20220718'
and dt <= '20221019'
and event_query is not null
group by cookie_id, event_query
#===============优化后
insert overwrite table tblB partition (dt = '2022-10-19')
select
split(tkey, '_')[1] as cookie_id,
event_query,
#--- 第二阶段2:求出最终的聚合值
sum(cnt) as cnt
from (
select
concat_ws('_', cast(ceiling(rand() * 99) as string), cookie_id) as tkey,
event_query,
#---第一阶段2:先局部聚合得到cnt
count(*) as cnt
from tblA
where dt >= '20220718'
and dt <= '20221019'
and event_query is not null
#--- 第一阶段1:添加[0-99]随机整数,将热点Key值:cookie_id 进行打散( M -->R)
group by concat_ws('_', cast(ceiling(rand() * 99) as string), cookie_id),
event_query
) temp
#--- 第二阶段1:对拼接的key值进行切分,还原原本的key值split(tkey, '_')[1] =cookie_id ( R -->R)
group by split(tkey, '_')[1], event_query;
优化思路为:
- ** **第一阶段:对需要聚合的Key值添加随机后缀进行打散,基于加工后的key值进行初步聚合(M-->R1)
- ** **第二阶段:对加工后的key值进行切分还原,对第一阶段的聚合值进行再次聚合,求出最终结果值(R1-->R2)
5.3.2 Count Distinct
** **
count(distinct 大量重复值) 的情景会出现数据倾斜,例如下面的sql语句:
select ds
,count(distinct shop_id) AS cnt
from demo_data0
group by ds;
** 可以使用如下三种方案解决:**
序号方案说明方案一参数调优, 添加数据倾斜时自动负载均衡的参数set hive.groupby.skewindata = true;方案二添加随机数,两阶段聚合
对group by分左右字段拼接随机数
方案三类似两阶段聚合group by与distinct的字段数据都均匀
优化方案一:参数调优
添加数据倾斜时自动负载均衡的参数,如下:
#---有数据倾斜的时候自动负载均衡(默认是 false)
set hive.groupby.skewindata = true;
开启该参数以后,当前程序会启动两个MapReduce来运行
- 第一个MapReduce自动进行随机分布到Reducer中(负载均衡),每个Reducer做部分聚合操作,输出结果
- 第二个MapReduce将上一步聚合的结果再按照业务(group by key)进行处理,保障相同的key分发到同一个reduce做最终聚合。
** 该参数的优化原理是:将M->R阶段 拆解成 M->R->R阶段**
引入两级reduce:
- 第一阶段的shuffle key = group key + 随机数,将热点数据打散,多个reduce并发做部分聚合;
- 第二阶段的shuffle key = group key,保障相同key分发到同一个reduce做最终聚合;
** 优化方案二:**添加随机数,两阶段聚合
若
cookie_id
字段数据不均匀,较通用的方式是队group by 分组字段值拼接随机数。
#===============优化前
insert overwrite table tblB partition (dt = '2022-10-19')
select
cookie_id,
event_query,
count(*) as cnt
from tblA
where dt >= '20220718'
and dt <= '20221019'
and event_query is not null
group by cookie_id, event_query
#===============优化后
insert overwrite table tblB partition (dt = '2022-10-19')
select
split(tkey, '_')[1] as cookie_id,
event_query,
#--- 求出最终的聚合值
sum(cnt) as cnt
from (
select
concat_ws('_', cast(ceiling(rand() * 99) as string), cookie_id) as tkey,
event_query,
#---将热点Key值:cookie_id 进行打散后,先局部聚合得到cnt
count(*) as cnt
from tblA
where dt >= '20220718'
and dt <= '20221019'
and event_query is not null
#--- 第一阶段:添加[0-99]随机整数,将热点Key值:cookie_id 进行打散( M -->R)
group by concat_ws('_', cast(ceiling(rand() * 99) as string), cookie_id),
event_query
) temp
#--- 第二阶段:对拼接的key值进行切分,还原原本的key值split(tkey, '_')[1] =cookie_id ( R -->R)
group by split(tkey, '_')[1], event_que
优化思路为:
- ** **第一阶段:对需要聚合的Key值添加随机后缀进行打散,基于加工后的key值进行初步聚合(M-->R1)
- ** **第二阶段:对加工后的key值进行切分还原,对第一阶段的聚合值进行再次聚合,求出最终结果值(R1-->R2)
优化方案三:类似两阶段聚合
如果group by字段数相对均匀,则可以采用如下方式优化,先groupby两分组字段(ds和shop_id)再使用
count(distinct)
命令
SELECT ds
,count(*) AS cnt
FROM(SELECT ds
,shop_id
FROM demo_data0
group by ds ,shop_id
)
group by ds;
5.3.3 ROW_NUMBER(计算TopN)
Top10的伪代码如下:
SELECT main_id
,type
FROM (SELECT main_id
,type
,ROW_NUMBER() OVER(PARTITION BY main_id ORDER BY type DESC ) rn
FROM <data_demo2>
) A
WHERE A.rn <= 10;
当发生数据倾斜时,可以通过以下几种方式解决:
序号方案说明方案一sql写法的两阶段聚合增加随机列或拼接随机数,将其作为分区(partition)中的一个参数
优化方案一:sql写法的两阶段聚合
为了使得Map阶段中的partition各分组数据尽可能均匀,增加随机列或拼接随机数,将其作为分区(partition)中的一个参数
SELECT main_id
,type
FROM (SELECT main_id
,type
#--第二阶段1:在第一阶段的结果集上,对热点key分区,继续排序
,ROW_NUMBER() OVER(PARTITION BY main_id ORDER BY type DESC ) rn
FROM (SELECT main_id
,type
FROM(SELECT main_id
,type
#--第一阶段2:对热点key和随机数一起分区排序,得到初步的排名rn
,ROW_NUMBER() OVER(PARTITION BY main_id,src_pt ORDER BY type DESC ) rn
FROM (SELECT main_id
,type
#--第一阶段1:ceil(rand()*10) 生成[1,10]之间的随机整数
,ceil(rand()*10) AS src_pt
FROM data_demo2
)
) B
#--第一阶段3:先过滤一波数据,输出结果集
WHERE B.rn <= 10
)
) A
#--第二阶段2:过滤,得到最终的结果集
WHERE A.rn <= 10;
5.3.4 动态分区写入数据倾斜
动态分区导致的小文件问题、数据倾斜问题的解决方案见文章:
Hive——动态分区导致的小文件问题-CSDN博客文章浏览阅读502次,点赞12次,收藏10次。Hive——动态分区导致的小文件问题https://blog.csdn.net/SHWAITME/article/details/136113037?spm=1001.2014.3001.5502
参考文章:
https://blog.51cto.com/alanchan2win/6453458
Hive/MaxCompute SQL性能优化(三):数据倾斜优化实战_maxcompute,sql实战-CSDN博客
3年数据工程师总结:Hive数据倾斜保姆教程(手册指南)
浅谈离线数据倾斜 - 京东云开发者的个人空间 - OSCHINA - 中文开源技术交流社区
JOIN时常见的数据倾斜场景及解决办法_云原生大数据计算服务 MaxCompute(MaxCompute)-阿里云帮助中心Hive/MaxCompute SQL性能优化(一):什么是数据倾斜_maxcompute 数据倾斜-CSDN博客
版权归原作者 吵吵叭火 所有, 如有侵权,请联系我们删除。