
机器学习小项目:从NIFTY指数的当日股价预测股票收盘价格,对比各种模型在时序数据预测的效果
如果你像我一样涉足股票交易,你可能想知道如何在收盘时判断股票的走势——它会在收盘价上方收盘,还是不会?因为确实存在日内模式——人们总是告诉你股票交易活动是“波浪式”的,而且在午餐时间事情往往会放慢一点,并且在接近尾声的时候可能会发生大的波动。
对于这个项目——(谷歌 Colab 笔记本在后面公开)——我使用 NIFTY 指数(印度),我们正在查看每分钟的数据。我们根据开盘价对每个时间序列进行标准化,因此每个点只是它与开盘价之间的差值。印度指数开盘6小时15分钟左右,意思是应该有375分钟。我使用了 2018 年至 2019 年的数据,并在数据点少于 372 个(只有 1 或 2 个)的任何一天删除。那么问题就变成了——我们需要多少历史窗口来预测股票的最终走势?你能在第一个小时之后说出来吗?或者机器可以在 6.25 小时中的 3 小时后学习模式吗?
我将尝试使用 sktime 库(一个时间序列库)以及 XGBoost 和 keras-TCN(一个时间卷积网络库)为 NIFTY 回答这个问题。我将在这里重点介绍的是 ROCKET transform 和时间序列分类器。这里实际上有大量有趣的时间序列分类器,其中许多属于符号表示类型(将时间序列表示为字母或符号序列,如 DNA)。我发现在这个时间序列中,它们中的大多数都没有太大的竞争力,所以我专注于实际上足够好用的 2 个,可以在现实生活中部署。
数据
数据来自这个 Kaggle,我们使用 NIFTY,而不是 BANK NIFTY 作为我们选择的指数。此外,我们只训练 2018-2019 年,将这个集合 80/20 划分,不做任何打乱,这样我们就可以看到过去训练的东西如何推广到未来,即,看看是否有某种概念漂移继续。
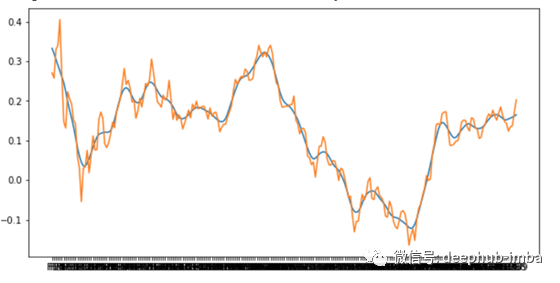
预处理数据——只需从其余的值中减去第一个值,使其等于 0,然后删除该列。将第一个 X 小时数作为您的训练数据。我从 4 小时开始,这意味着 239 个时间点(第 240 个是您要预测的时间点)。然后,通过除以 100 来缩放数字,以获得大致在 [0,1] 范围内的数字。要创建二进制目标变量,只需将收盘价与开盘价进行比较,如果收盘价更高,我们编码为 1,否则为 0。此外,您可能想尝试使用 tsmoothie 的 LOWESS 来平滑时间序列.它在大局中没有太大变化。这是一个每日时间序列及其平滑版本的图:
Sktime 分类器要求数据以一种奇怪的格式存储——一个 Pandas DataFrame,除了每个时间戳的一列(239 个特征,一个形状数组 (N, 239),你有 1 列,其中每一行或每个元素 该列本身就是一个pandas Series,意思是一个 (N,1) 数组,其中单个特征是 239 个元素系列。
模型选择
以下是我使用的模型以及它们的配置方式。
ROCKET——这个基于随机卷积核,所以基本上,它就像一个浅层卷积神经网络,没有非线性激活、扩张或任何花哨的东西。它被认为是快速和 SOTA 的,而且效果很好。默认情况下,ROCKET 使用 10000 个内核。从技术上讲,我使用的是 MINIROCKET,它会生成特征——但是你仍然必须选择一个分类器来从这些特征中学习。为此,他们推荐Ridge 分类器或逻辑回归。我发现使用 RidgeCV() 可以获得不错的性能,并且它比 LogisticRegressionCV 更快。代码看起来像这样:
rocket = MiniRocket(random_state = 2468)
trainx_transform = rocket.fit_transform(Xtrain_sktime)
valx_transform = rocket.transform(Xtest_sktime)
clf = RidgeClassifierCV(alphas = np.logspace(-4,4, num = 100), normalize = True)
clf.fit(trainx_transform, ytrain_sktime)
predicted = clf.predict(valx_transform)
print("Accuracy with Rocket: %2.3f" % accuracy_score(ytest_sktime, predicted))
print("Matthews CC:%2.3f" % matthews_corrcoef(ytest_sktime, predicted))
Time Series Forest——这个很有趣——它不是将每个时间戳作为一个特征并将其扔到基于树的分类器中,而是获取时间序列的间隔(模型的 HP 有多少个间隔),并找到一些特殊的特征 像每个人的平均值、偏差和斜率这样的统计数据,并将它们用作特征。这意味着保留时间戳的顺序,而如果您只是将每个时间戳视为一个独立的特征,那么您的算法并不关心它们的排列顺序。然后将这些特征交给 DecisionTreeClassifier。代码如下所示:
steps = [
("extract",RandomIntervalFeatureExtractor(n_intervals = "sqrt",features=[np.mean, np.std, _slope])),("clf", DecisionTreeClassifier())]
time_series_tree = Pipeline(steps)
tsf = TimeSeriesForestClassifier(estimator=time_series_tree,
n_estimators = 100,
criterion = "entropy",
bootstrap=True,
oob_score=True,
random_state = 2222,
n_jobs=-1)
tsf.fit(Xtrain_sktime, ytrain_sktime)
print("Accuracy: ", accuracy_score(ytest_sktime, tsf.predict(Xtest_sktime)))
print("MCC: ", matthews_corrcoef(ytest_sktime, tsf.predict(Xtest_sktime)))
XGBoost——我还用 XGBClassifier() 训练了一个模型,使用每个时间戳作为一个特征。
TCN——为简单起见,我使用基于 keras/tensorflow 的库 keras-tcn。它使用扩张的内核。我没有更改任何默认设置,只是确保最后一层使用 log-loss 作为损失函数。代码如下所示:
i = Input(shape=(trainx.shape[-2], 1))
m = TCN()(i)
m = Dense(1, activation = 'sigmoid')(m)
early_stopping = EarlyStopping(patience = 50, restore_best_weights=True, min_delta = 0.000)
reduceLR = ReduceLROnPlateau(factor = 0.5, patience = 5, min_delta = 0.01)
from keras.optimizers import *
model = Model(inputs=[i], outputs=[m])
model.summary()
model.compile(loss = "binary_crossentropy", optimizer = Adam(lr = 1e-3)
model.reset_states()
model.fit(trainx, trainy,validation_data = (valx, y_test),
shuffle = True,
callbacks = [early_stopping, reduceLR],
batch_size = 64,
epochs = 200)
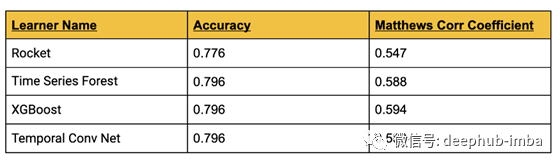
模型评估 - 4 小时窗口
以下是 4 小时窗口的结果。TCN 花费的时间最长,即使提前停止,并且有超过 90k 的参数。相比之下,ROCKET真的是一眨眼就完成了。
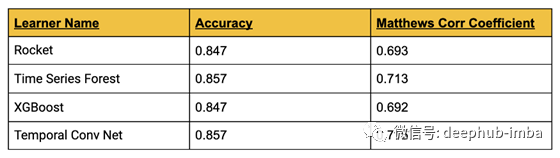
模型评估 - 5 小时窗口
您会期望这会获得更好的结果,因为不确定性只是一天中最后 1.25 小时发生的事情。以下是使用相同学习器、相同参数等的结果。
最后本文的只是对比几个模型的准确程度,也许可以用在实际的数据中,但是请在使用前进行详细的验证。
本文的代码在这里:https://colab.research.google.com/drive/11kjEsGcwQwm7lhvx25hU61UaEJ8XdxNw?usp=sharing
作者:Peijin Chen