
Grad-CAM 概述:给定图像和感兴趣的类别作为输入,我们通过模型的 CNN 部分前向传播图像,然后通过特定于任务的计算获得该类别的原始分数。除了期望的类别(虎),所有类别的梯度都设置为零,该类别设置为 1。然后将该信号反向传播到卷积特征图,我们将其结合起来计算粗略的 Grad-CAM 定位( 蓝色热图)它表示模型在做出特定决策时必须查看的位置。最后,我们将热图与反向传播逐点相乘,以获得高分辨率和特定于概念的引导式 Grad-CAM 可视化。
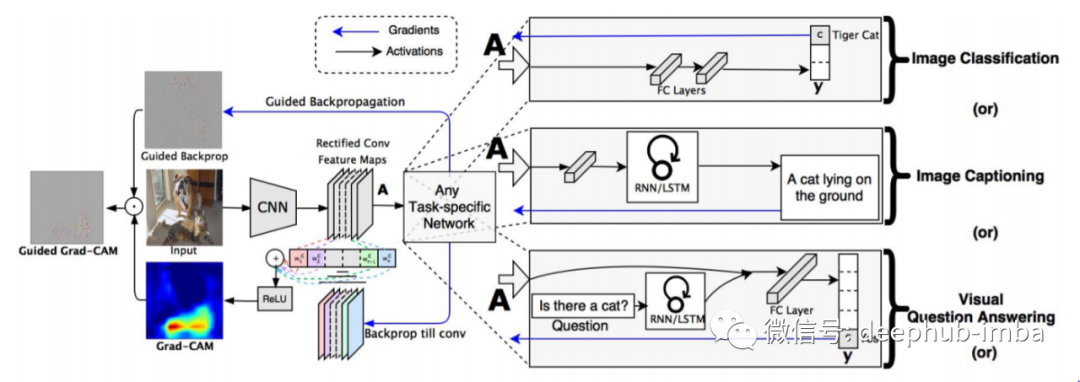
在本文中,我们将学习如何在 PyTorch 中绘制 GradCam [1]。
为了获得 GradCam 输出,我们需要激活图和这些激活图的梯度。
让我们直接跳到代码中!!
引入相应的包
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torchvision import models
from skimage.io import imread
from skimage.transform import resize
我们将使用钩子函数从所需的层和张量获得激活映射和梯度。在本教程中,我们将从ResNet50的layer4中获取激活映射,并对相同的输出张量进行梯度。
class GradCamModel(nn.Module):
def __init__(self):
super().__init__()
self.gradients = None
self.tensorhook = []
self.layerhook = []
self.selected_out = None
#PRETRAINED MODEL
self.pretrained = models.resnet50(pretrained=True)
self.layerhook.append(self.pretrained.layer4.register_forward_hook(self.forward_hook()))
for p in self.pretrained.parameters():
p.requires_grad = True
def activations_hook(self,grad):
self.gradients = grad
def get_act_grads(self):
return self.gradients
def forward_hook(self):
def hook(module, inp, out):
self.selected_out = out
self.tensorhook.append(out.register_hook(self.activations_hook))
return hook
def forward(self,x):
out = self.pretrained(x)
return out, self.selected_out
我们向ResNet50模型的层添加一个前向钩子。前向钩子接受该层的输入和该层的输出作为参数。对于输出张量,我们使用register_hook方法注册一个钩子。这个方法注册一个向后挂钩到一个张量,并且每次计算梯度时调用这个张量。它的输入参数是相对于输出张量的梯度。
以下是声明模型实例
gcmodel = GradCamModel().to(‘cuda:0’)
读取图片


img = imread(‘/content/tiger.jfif’) #'bulbul.jpg'
img = resize(img, (224,224), preserve_range = True)
img = np.expand_dims(img.transpose((2,0,1)),0)
img /= 255.0
mean = np.array([0.485, 0.456, 0.406]).reshape((1,3,1,1))
std = np.array([0.229, 0.224, 0.225]).reshape((1,3,1,1))
img = (img — mean)/std
inpimg = torch.from_numpy(img).to(‘cuda:0’, torch.float32)
计算类梯度激活映射
out, acts = gcmodel(inpimg)
acts = acts.detach().cpu()
loss = nn.CrossEntropyLoss()(out,torch.from_numpy(np.array([600])).to(‘cuda:0’))
loss.backward()
grads = gcmodel.get_act_grads().detach().cpu()
pooled_grads = torch.mean(grads, dim=[0,2,3]).detach().cpu()
for i in range(acts.shape[1]):
acts[:,i,:,:] += pooled_grads[i]
heatmap_j = torch.mean(acts, dim = 1).squeeze()
heatmap_j_max = heatmap_j.max(axis = 0)[0]
heatmap_j /= heatmap_j_max
现在,需要调整热图的大小和颜色。
调整大小
heatmap_j = resize(heatmap_j,(224,224),preserve_range=True)
颜色映射
cmap = mpl.cm.get_cmap(‘jet’,256)
heatmap_j2 = cmap(heatmap_j,alpha = 0.2)
可视化
fig, axs = plt.subplots(1,1,figsize = (5,5))
axs.imshow((img*std+mean)[0].transpose(1,2,0))
axs.imshow(heatmap_j2)
plt.show()
结果如下


我们换一种更清晰的方式查看热图
heatmap_j3 = (heatmap_j > 0.75)
可视化
fig, axs = plt.subplots(1,1,figsize = (5,5))
axs.imshow(((img*std+mean)[0].transpose(1,2,0))*heatmap_j3)
plt.show()
结果


最后我们移除刚才设置的钩子
for h in gcmodel.layerhook:
h.remove()
for h in gcmodel.tensorhook:
h.remove()
引用
[1] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh and D. Batra, “Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization,” 2017 IEEE International Conference on Computer Vision (ICCV), 2017, pp. 618–626, doi: 10.1109/ICCV.2017.74.
本文作者: the owl