
对于采集jd的商品数据,依赖requests库的惯用方法是不可取的。原因很简单:京东的商品数据是动态加载的,处理冗长的URL很麻烦,所以我们将使用selenium库对商品数据的源码进行数据采集。
声明:本程序仅作为学习交流使用!已经对一部分代码进行了模糊处理。
一、首先进行网页分析
1、打开网页;
京东(JD.COM)-正品低价、品质保障、配送及时、轻松购物!
2、滑动验证问题:进入网页后做一些操作会触发登录,所以这是我们要解决的第一个问题,处理滑动验证(手动解决也可);
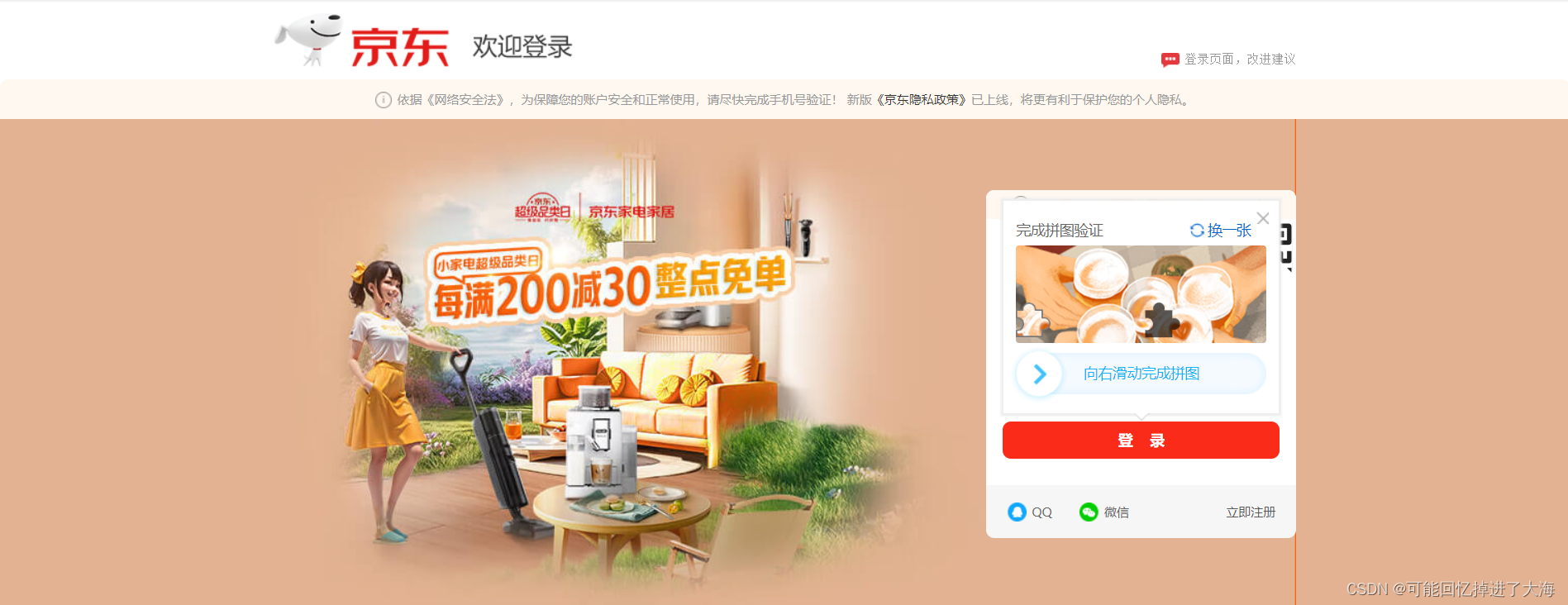
3、抓包分析:假设我们需要完成对“手机”品类的数据收集;
①、网页元素里就包含我们需要的信息,但是因为是动态加载,信息量很少:
②、很容易发现在网络模块中也包含这些内容:
③、可以查看请求动态刷新数据的url,非常复杂。
④、我们再来看一看数据的大概样式:
由此可见,一条li标签对应一个商品信息,class标签"gl-i-wrap"的内部则是商品的详细数据。如(p-img)图片信息、(p-name)商品名信息、(p-price)价格信息、(p-shop)店铺信息、活动内容等。

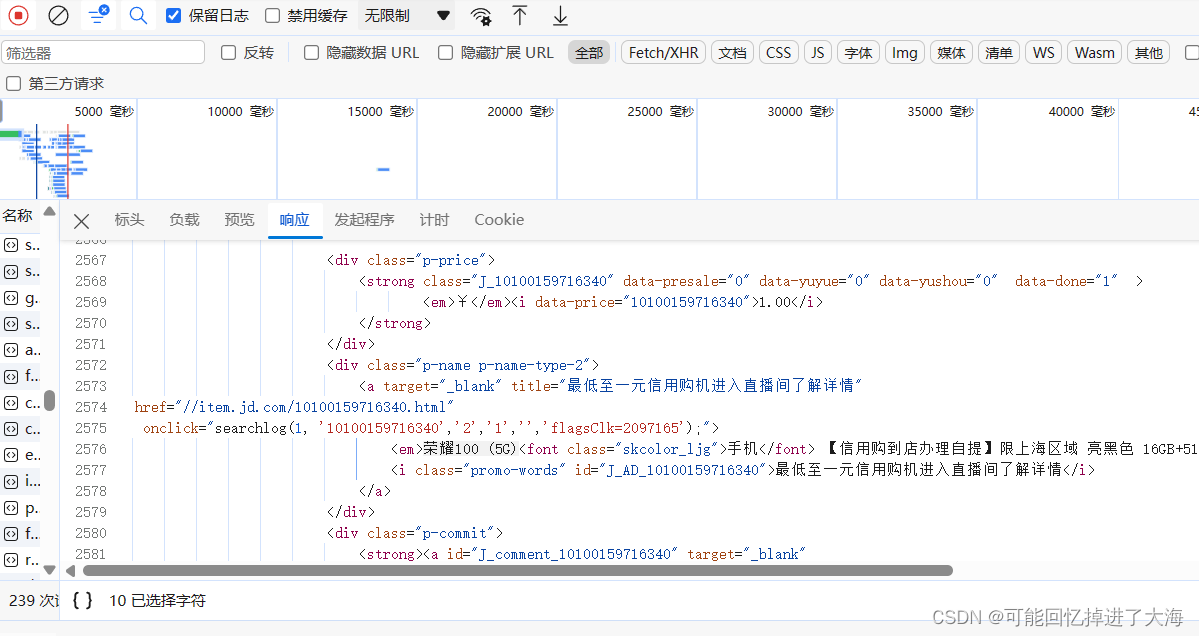
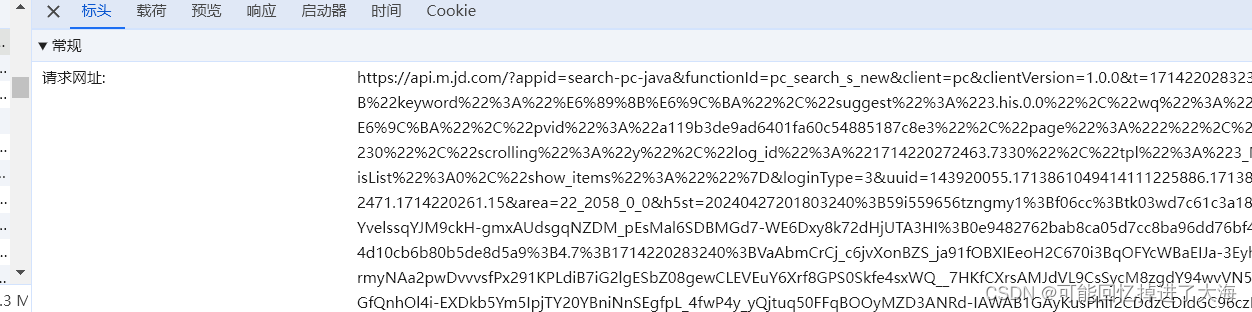

综合以上,我们不难发现,要想实现对网页数据的采集,目前就只能使用selenium(大佬除外)。
4、已经确定使用selenium采集数据,开始解决反爬虫问题:
①:在滑动页面的过程中会出现“加载失败”,需要定位到这个按钮,并不断点击直到刷新页面数据为止:
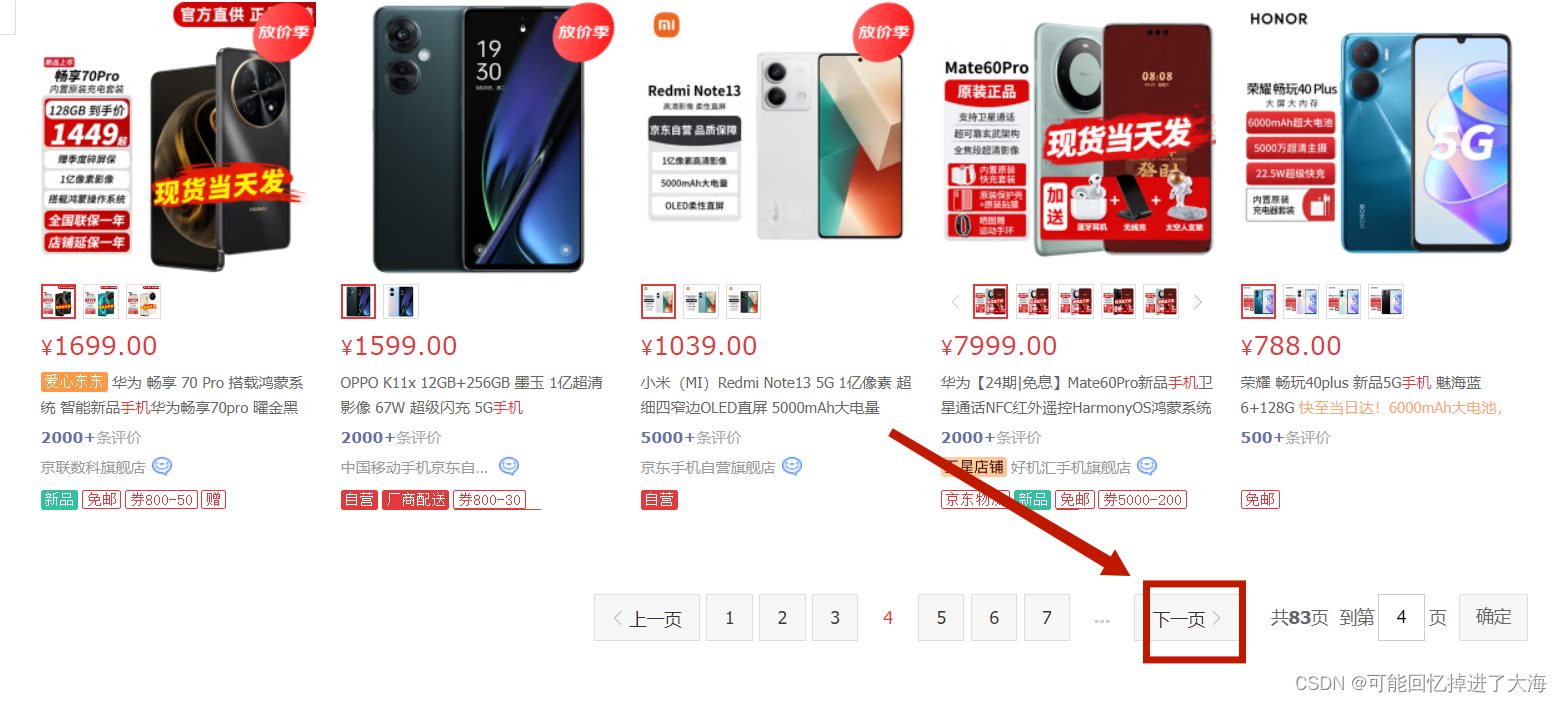
②、进行翻页操作(右下角会有一个无法关闭的弹窗,会遮挡翻页时对页面元素的操作):
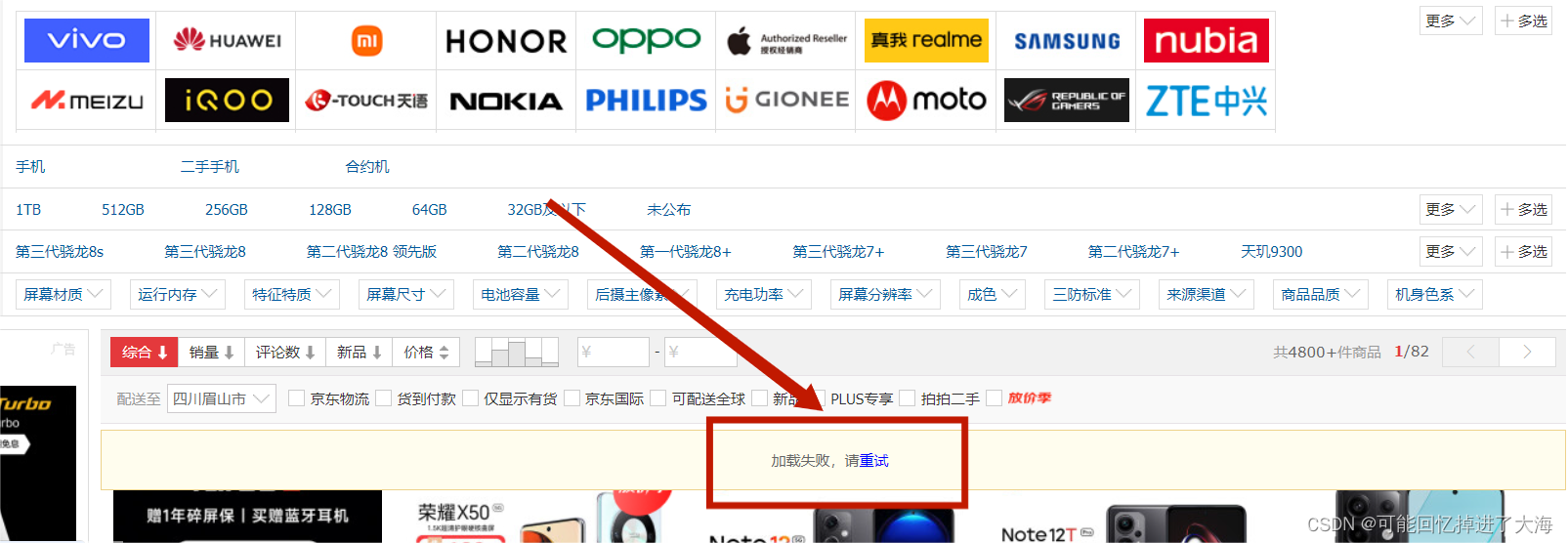
二、具体实现步骤:
1、导入外部库:
# 导入时间模块: import time # 导入selenium模块: from selenium import webdriver # 用于设置浏览器驱动: from selenium.webdriver.chrome.service import Service # 用于指定元素定位方式: from selenium.webdriver.common.by import By # 等待页面加载的模块: from selenium.webdriver.support.ui import WebDriverWait # 设置等待条件的模块: from selenium.webdriver.support import expected_conditions as EC # 抛出时间异常: from selenium.common.exceptions import TimeoutException, NoSuchElementException # 模拟鼠标键盘操作: from selenium.webdriver import ActionChains2、登陆操作:
使用id定位或xpath定位,实现输入和点击操作:
def login(): # 声明全局变量driver的浏览器操作 global driver #设置登录信息 account_number = input("请输入您的账号:") password = input("请输入您的密码:") #确定驱动文件位置,并打开浏览器 service = Service("C:/chromedriver-win64/chromedriver.exe") driver = webdriver.Chrome(service=service) driver.get("https://www.jd.com/") driver.implicitly_wait(5) # 处理找不到元素的情况 try: search = driver.find_element(By.ID, 'key') except NoSuchElementException: search = None print("找不到输入框!") if search: search.click() time.sleep(1) #输入搜索内容 search.send_keys("手机") driver.implicitly_wait(5) #点击搜索 driver.find_element(By.XPATH, '//*[@id="search"]/div/div[2]/button').click() try: login_name = driver.find_element(By.ID, 'loginname') login_password = driver.find_element(By.ID, 'nloginpwd') login_submit = driver.find_element(By.ID, 'loginsubmit') except NoSuchElementException: print("无法登录") # 如果找不到登录元素,直接返回 return time.sleep(1) #在目标网页输入登录信息 login_name.send_keys(account_number) login_password.send_keys(password) driver.implicitly_wait(5) #点击按钮 login_submit.click() driver.implicitly_wait(5) page(driver)3、解决滑动验证(这里只展示手动,滑动验证在最后)
4、执行滚动页面的操作,如果遇到加载失败就不断点击重试:
def page(driver): # 返回顶部 driver.execute_script("window.scrollBy(0, -6000);") time.sleep(3) wait = WebDriverWait(driver, 5) # 等待最长 10 秒 # 设置循环次数上限,防止无限循环 # 最大重试次数 max_retries = 10 retries = 0 while retries < max_retries: try: #等待重试按钮可点击 error_button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, ".notice-filter-loading .nf-l-wrap span a"))) error_button.click() print("正在点击重试按钮") except TimeoutException: print("找不到重试按钮") # 如果找不到按钮(证明已经刷新了页面),跳出循环 break retries += 1 time.sleep(1) #获取当前页数和总页数并输出 page_num_max=driver.find_element(By.CSS_SELECTOR,'.filter .f-pager .fp-text i ') page_num_max_text=page_num_max.text page_num_now = driver.find_element(By.CSS_SELECTOR, '.filter .f-pager .fp-text b ') page_num_now_text = page_num_now.text print("总共页数为:",page_num_max_text) print("当前页数为:",page_num_now_text) while True: # 滚动页面 driver.execute_script("window.scrollBy(0, 3000);") wait_2 = WebDriverWait(driver, 2) # 设置循环次数上限,防止无限循环 # 最大重试次数 max_retries_2 = 10 retries_2 = 0 while retries_2 < max_retries_2: try: error_button_2 = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, ".notice-loading-error span a"))) error_button_2.click() print("正在点击重试按钮") except TimeoutException: print("找不到重试按钮") # 如果找不到按钮(证明已经刷新了页面),跳出循环 break retries_2 += 1 get_information(driver)5、获取每一页的数据:
def get_information(driver): driver.execute_script("window.scrollBy(0, 3000);") time.sleep(1) # 获取包含产品的列表 try: lis = driver.find_elements(By.CLASS_NAME, 'gl-item') except NoSuchElementException: print("Product list not found.") # 如果找不到列表,直接返回 return #设置计数初始值 num = 0 # 遍历列表并提取数据 for li in lis: num += 1 #初始化,解决没有值返回空值的情况 shop_title = "N/A" user_comment_text = "N/A" title_name_text = "N/A" goods_price_text = "N/A" img_src = "N/A" #获取店铺信息 try: shop_link = li.find_element(By.CSS_SELECTOR, '.p-shop a') shop_title = shop_link.text except NoSuchElementException: pass #获取用户评论数量 try: user_comment = li.find_element(By.CSS_SELECTOR, '.p-commit strong a') user_comment_text = user_comment.text except NoSuchElementException: pass #获取商品title(名称) try: title_name = li.find_element(By.CSS_SELECTOR, '.p-name em') title_name_text = title_name.text except NoSuchElementException: pass #获取商品价格 try: goods_price = li.find_element(By.CSS_SELECTOR, '.p-price strong i') goods_price_text = goods_price.text except NoSuchElementException: pass #获取商品图片 try: img_element = li.find_element(By.CSS_SELECTOR, '.p-img a img') img_src = img_element.get_attribute("src") except NoSuchElementException: pass print(f"{num}: {title_name_text}, {goods_price_text}, {shop_title}, {user_comment_text},{img_src}") # 将数据添加到列表中,可以用于保存数据到其他地方,我的代码不作演示 data_list=({ "序号": num, "标题": title_name_text, "价格": goods_price_text, "店铺": shop_title, "用户评价数量": user_comment_text, "商品图片": img_src, }) change_pages(driver)6、使用鼠标事件模拟鼠标操作移除遮挡弹窗:
def change_pages(driver): global action # 翻页操作,注意容错处理 try: # 找到遮挡物的 XPath overlay_xpath = '//*[@id="J-global-toolbar"]/div/div[1]/div[4]/div[1]/div/p' # 使用 try-except 来判断遮挡物是否存在 try: wait = WebDriverWait(driver, 1) # 等待遮挡物可见 overlay_element = wait.until(EC.visibility_of_element_located((By.XPATH, overlay_xpath))) print("遮挡物存在且可见") # 使用 ActionChains 模拟鼠标移动到遮挡物 action = ActionChains(driver) overlay_element = driver.find_element(By.XPATH, overlay_xpath) # 将鼠标移动到遮挡物上,触发其消失 action.move_to_element(overlay_element).perform() # 确保遮挡物已经消失 time.sleep(1) # 移动到其他指定元素 element_to_move_to = driver.find_element(By.XPATH, '//*[@id="J_bottomPage"]/span[1]/a[9]/em') # 将鼠标移动到该元素 action.move_to_element(element_to_move_to).perform() # 模拟点击操作 action.click().perform() page(driver) except TimeoutException: print("遮挡物不存在或不可见") # 移动到其他指定元素 element_to_move_to = driver.find_element(By.XPATH, '//*[@id="J_bottomPage"]/span[1]/a[9]/em') # 将鼠标移动到该元素 action.move_to_element(element_to_move_to).perform() # 模拟点击操作 action.click().perform() page(driver) except NoSuchElementException: print("右键无法翻页!") # 执行运行的函数 if __name__ == "__main__": login() input()7、代码执行后会输出以下内容:
也可以运用其他操作保存至excel文档进行可视化分析和操作:


三、针对京东的滑动验证码的解决思路(附部分代码):
1、基本思路:
①、获取滑动块和带有缺口的背景图,保存到本地。
②、对滑动块进行灰度、二值化处理,使其轮廓清晰。
③、对其灰色边框进行描绘,得到一个完整的轮廓模型。
④、得到滑动块插入到背景图最左侧的style参数(top、width值)。
⑤、用得到的参数推算缺口的上下边框对应的y值,并对其余干扰部分裁剪。
⑥、通过观察发现,缺口的底色相似,可以使用颜色来获取相似的部分。
⑦、对背景图进行灰度、二值化处理,使其轮廓清晰并与滑动块进行轮廓对比匹配最合适的。
其他办法:大数据模型、js逆向
2、部分代码实现:
①、对滑动块进行处理获取轮廓:
def sliding_shoe(driver):
global small_img_path
# 滑块图
small_img = driver.find_element(By.CSS_SELECTOR, '.JDJRV-img-panel .JDJRV-smallimg img ')
small_img_src = small_img.get_attribute("src")
base64_str_small = re.sub(r'^data:image/.+;base64,', '', small_img_src)
image_data_small = base64.b64decode(base64_str_small) # 使用小图的解码数据
image_small = Image.open(BytesIO(image_data_small)) # 创建小图对象
# 创建存储目录,如果不存在
output_dir = "images"
os.makedirs(output_dir, exist_ok=True) # 如果目录不存在则创建
# 保存滑块图
small_img_path = os.path.join(output_dir, "huaKuai_image.png")
image_small.save(small_img_path)
print(f"滑块图保存至: {small_img_path}")
# 加载滑块图
img_path = "images\huaKuai_image.png" # 你的滑块图路径
img = cv2.imread(img_path)
# 转换为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 假设我们选择 100 到 200 之间的灰度值
lower_gray = 100
upper_gray = 200
# 创建二值化掩码,只保留指定范围内的灰度
mask = cv2.inRange(gray, lower_gray, upper_gray)
# 找到轮廓
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 创建一个副本用于绘制
img_with_contours = img.copy()
# 绘制轮廓
for contour in contours:
cv2.drawContours(img_with_contours, [contour], -1, (0, 255, 0), 1) # 用绿色线条绘制
# 找到最大的轮廓,并计算其外接矩形
if contours:
max_contour = max(contours, key=cv2.contourArea)
x, y, w, h = cv2.boundingRect(max_contour) # 获得外接矩形
cv2.rectangle(img_with_contours, (x, y), (x + w, y + h), (0, 255, 0), 2) # 用绿色矩形标记
# 显示图像
plt.imshow(cv2.cvtColor(img_with_contours, cv2.COLOR_BGR2RGB))
plt.title("HUAKUAI_RESULT")
plt.axis("off")
plt.show()
运行后的识别效果:

②、对背景图进行处理:
def background(driver): global distance_to_left # 获取背景图 big_img = driver.find_element(By.CSS_SELECTOR, '.JDJRV-img-panel .JDJRV-bigimg img ') big_img_src = big_img.get_attribute("src") # 处理 Base64 数据 base64_str_big = re.sub(r'^data:image/.+;base64,', '', big_img_src) image_data_big = base64.b64decode(base64_str_big) image_big = Image.open(BytesIO(image_data_big)) # 创建存储目录 output_dir = "images" os.makedirs(output_dir, exist_ok=True) # 将背景图转换为 OpenCV 格式 background_img = cv2.cvtColor(np.array(image_big), cv2.COLOR_RGB2BGR) # 调整背景图尺寸为 242x94 new_width = 242 new_height = 94 resized_background_img = cv2.resize(background_img, (new_width, new_height)) # 调整尺寸 # 保存调整后的背景图 big_img_path = os.path.join(output_dir, "background_image.png") cv2.imwrite(big_img_path, resized_background_img) # 保存调整后的图像 # 设定要裁剪的边界尺寸 crop_top = 10 # 裁剪上边框的偏移 crop_bottom = 45 # 裁剪下边框的偏移 crop_margin = 30 # 裁剪左右两侧的像素数 # 上下裁剪的坐标 y1 = int(slider_top + crop_top) # 裁剪后的顶部位置 y2 = int(slider_bottom + crop_bottom) # 裁剪后的底部位置 # 裁剪背景图,保留中央区域 cropped_background = background_img[y1:y2, crop_margin:-crop_margin] # 去掉左右两侧的50像素,保留中间部分 # 定义RGB范围 lower_rgb = np.array([17, 7, 0]) # 最小范围 upper_rgb = np.array([89, 89, 89]) # 最大范围 # 创建掩码以找到符合RGB范围的区域 mask = cv2.inRange(cropped_background, lower_rgb, upper_rgb) # 提取轮廓 contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 获取滑动块图像并提取其轮廓 slider_img_path = os.path.join(output_dir, "huaKuai_image.png") slider_img = cv2.imread(slider_img_path) # 转换为灰度并二值化 gray_slider = cv2.cvtColor(slider_img, cv2.COLOR_BGR2GRAY) _, binary_slider = cv2.threshold(gray_slider, 100, 200, cv2.THRESH_BINARY) slider_contours, _ = cv2.findContours(binary_slider, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 找到滑动块的主要轮廓 slider_contour = max(slider_contours, key=cv2.contourArea) # 找到与滑动块最相似的背景图中的轮廓 best_match = None lowest_diff = float("inf") for contour in contours: similarity = cv2.matchShapes(slider_contour, contour, cv2.CONTOURS_MATCH_I1, 0) if similarity < lowest_diff: best_match = contour lowest_diff = similarity # 绘制找到的最佳匹配轮廓 cropped_with_contours = cropped_background.copy() if best_match is not None: x, y, w, h = cv2.boundingRect(best_match) cv2.rectangle(cropped_with_contours, (x, y), (x + w, y + h), (0, 255, 0), 2) print("距离为x:",x-27) distance_to_left=x-27 # 显示背景图与绿色矩形框 plt.imshow(cv2.cvtColor(cropped_with_contours, cv2.COLOR_BGR2RGB)) plt.title("Background Result with Adjusted Area") plt.axis("off") plt.show() do_actionchains(driver, distance_to_left)运行后的识别效果:
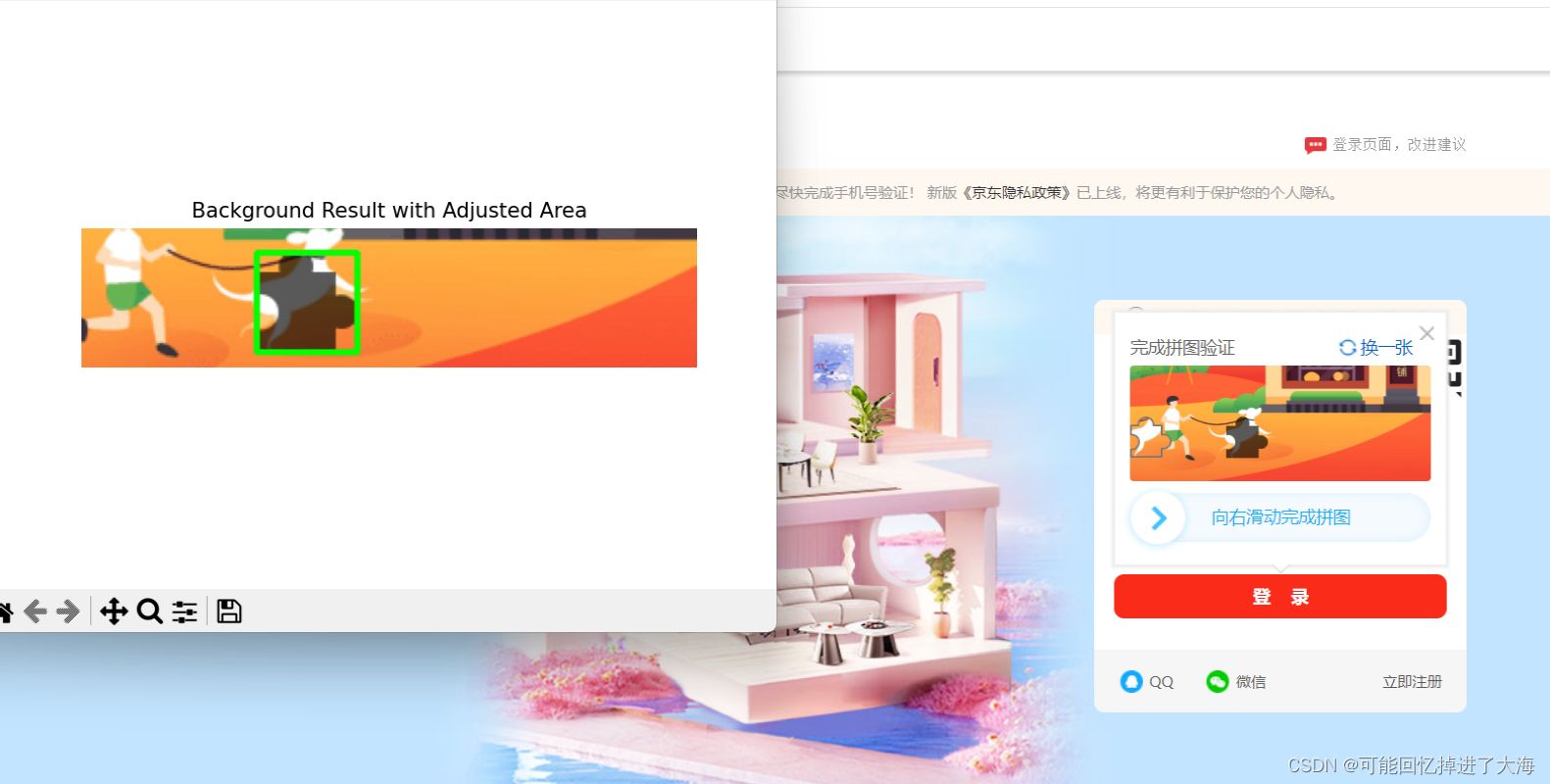
关于滑动验证码,没有获取滑块插入背景图的参数的部分,以及使用的到的值拖动滑块的部分,关于这些操作,如有需要可以发私信获取。
本文转载自: https://blog.csdn.net/2301_78753314/article/details/138170632
版权归原作者 可能回忆掉进了大海 所有, 如有侵权,请联系我们删除。
版权归原作者 可能回忆掉进了大海 所有, 如有侵权,请联系我们删除。