
读数据流程
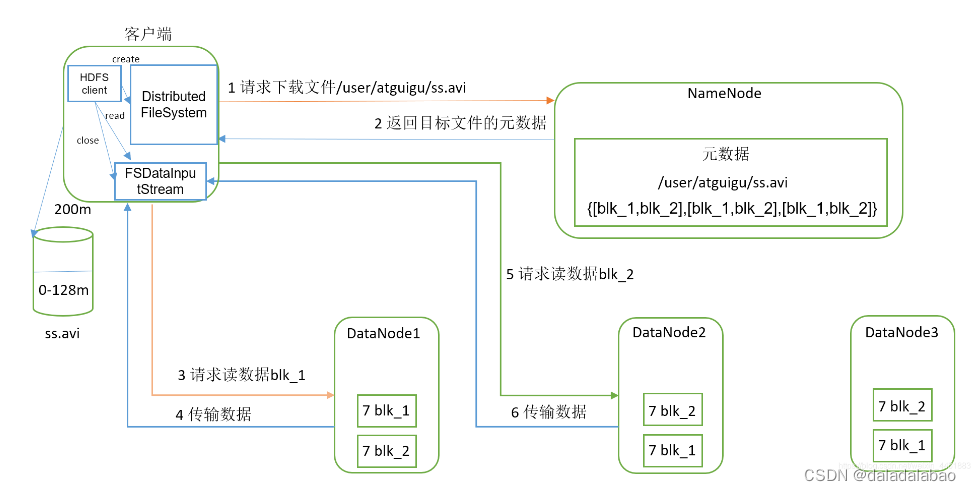
- 客户端向NameNode请求文件的位置:客户端想要访问一个文件时,会向NameNode发送一个请求,要求获取该文件在HDFS上的位置信息。
- NameNode将位置信息返回给客户端:NameNode接收到客户端的请求后,会返回该文件所在的DataNode节点的IP地址和块ID等信息。
- 客户端连接DataNode获取数据:客户端根据NameNode返回的信息,连接包含所需数据块的DataNode并请求读取数据。
- DataNode返回数据给客户端:DataNode收到客户端的读取请求,从本地磁盘读取相应的数据块,并将其返回给客户端。
- 客户端合并数据:如果所请求的数据块不止一个,客户端可以根据需要将多个数据块的数据合并成一个完整的文件。
- 客户端关闭文件:当客户端完成对文件的访问后,它会通知HDFS以便释放相关资源。
hdfs在读取文件时,其中一个block坏掉了怎么办?
当 HDFS 读取数据时遇到了一个损坏的 block,处理这种情况的方法如下:
- HDFS 自动处理
如果 HDFS 发现某个 block 损坏了,它会自动尝试从其他的副本中读取相同的数据。HDFS 的默认行为是在损坏副本的基础上创建新的副本,以保证数据块数量达到预期。
- 人工处理
如果 HDFS 自动处理不能满足需求,可以手动处理。 首先需要确定到底哪个 block 已经损坏。可以使用以下方式:
- 可以通过 Hadoop 自带的 checksum 功能计算每个 block 的校验和,并与存储在 NameNode 上的校验和进行比较。 如果两个校验和不匹配,那么就意味着文件的该 block 已经损坏了。
- 还可以通过 DFS Health Reporter 和 DataNode Logs 来获取更多有关坏掉 block 的信息。
一旦知道了哪个 block 损坏了,我们需要采取适当的措施来纠正这个问题,例如:
- 如果只有一个副本损坏了,在修复或替换该副本之前,应将其删除以确保读取数据时不会遇到任何错误。
- 如果多个副本坏掉了,需要从备份中恢复该 block。
- 如果不能从备份中恢复块,则需要采取其他措施,例如手动创建一些数据来替换该 block,或使用分散存储系统(如 RAID)来保护数据的完整性。
总之,在处理 HDFS 中损坏的 block 时,应先让系统尝试自动修正问题。 如果自动修复无法成功,则必须手动修复问题以确保 HDFS 文件系统的正常
写数据流程
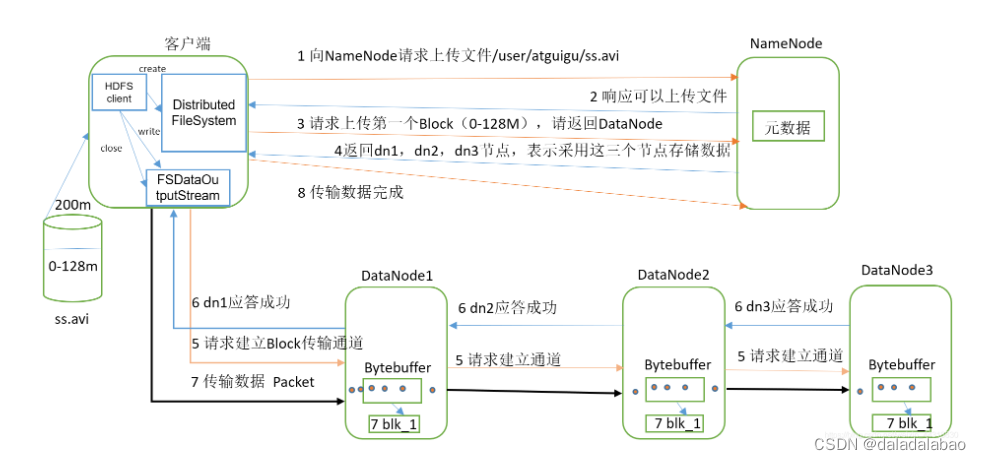
- 客户端向NameNode请求将数据写入HDFS。
- NameNode检查目标文件是否存在,如果不存在,则创建一个新文件。
- 分配一组数据节点给该文件,并确定每个数据节点将负责存储哪些块。
- 地址返回给客户端。
- 客户端选择其中一个数据节点作为首选写入节点,并向其发送写入请求。
- 数据节点接收到写入请求后,将数据缓存在本地磁盘中,并确认客户端已经有相应的权限进行写入操作。
- 当数据量达到一定大小后,数据节点按照预设的块大小划分成多个块,每个块存储在一个DataNode上。
- 数据节点向客户端发送确认消息,表示可以开始向DataNode写入数据。
- 客户端从文件中读取数据并发送至首选写入节点。
- 写入节点将数据写入本地磁盘缓存,并向副本节点通知需要进行数据复制的指令。
- 副本节点复制数据到本地磁盘缓存,并将确认写入节点:数据块已成功复制。
- 所有数据块都已被写入数据节点,写入过程全部完成。
- 客户端接受写入确认消息并结束本次写入操作。
HDFS在写数据的时候,如果其中一个DataNode突然挂掉了怎么办?
在HDFS写数据时,如果其中一个DataNode突然挂掉了,HDFS会自动检测到该节点不可用并尝试将数据复制到其他可用的DataNode上。这是由于HDFS中每个块都会被副本到多个节点上,通常默认情况下是三个副本。因此,在数据写入期间,如果其中一个DataNode发生故障,HDFS可以从其他 DataNode 取得副本数据进行恢复。
具体来说,HDFS有一个名为“replication factor”的概念,它显示了要在网络中存储特定块数据的副本数。当我们在HDFS写入数据时,数据会被分成固定大小的块并在不同的DataNode上进行复制。默认情况下,副本数是3,但是您也可以根据需要进行更改。
当DataNode节点出现问题时,HDFS会根据复制因子查找另外两个节点上的数据副本,以保证数据的完整性。在后续操作中,HDFS将停止向故障节点传输块数据,直到其恢复正常运行。
因此,即便在写入数据时有某些异常状况,最终HDFS也会确保数据安全地持久化到集群中去。
本文转载自: https://blog.csdn.net/qq_45450889/article/details/131310524
版权归原作者 daladalabao 所有, 如有侵权,请联系我们删除。
版权归原作者 daladalabao 所有, 如有侵权,请联系我们删除。