

🎉作者简介:👓
博主在读机器人研究生,目前研一。对计算机后端感兴趣,喜欢 c + + , g o , p y t h o n , 目前熟悉 c + + , g o 语言,数据库,网络编程,了解分布式等相关内容 \textcolor{orange}{博主在读机器人研究生,目前研一。对计算机后端感兴趣,喜欢c++,go,python,目前熟悉c++,go语言,数据库,网络编程,了解分布式等相关内容} 博主在读机器人研究生,目前研一。对计算机后端感兴趣,喜欢c++,go,python,目前熟悉c++,go语言,数据库,网络编程,了解分布式等相关内容📃
个人主页: \textcolor{gray}{个人主页:} 个人主页: 小呆鸟_coding🔎
支持 : \textcolor{gray}{支持:} 支持: 如果觉得博主的文章还不错或者您用得到的话,可以免费的关注一下博主,如果三连收藏支持就更好啦 \textcolor{green}{如果觉得博主的文章还不错或者您用得到的话,可以免费的关注一下博主,如果三连收藏支持就更好啦} 如果觉得博主的文章还不错或者您用得到的话,可以免费的关注一下博主,如果三连收藏支持就更好啦👍 就是给予我最大的支持! \textcolor{green}{就是给予我最大的支持!} 就是给予我最大的支持!🎁💛本文摘要💛
本专栏主要是讲解操作系统的相关知识 本文主要讲解 文件系统管理文章目录
**
清华操作系统系列文章:可面试可复习**
操作系统—概述
操作系统—中断、异常、系统调用
操作系统—物理内存管理
操作系统—非连续内存分配
虚拟内存管理
操作系统—虚拟内存管理技术页面置换算法
进程管理
调度算法
同步与互斥
信号量和管程
死锁和进程通信
文件系统管理
🌑文件系统管理
🌔1. 基本概念
🌒1.1 文件系统和文件
🌗1.1.1 文件系统和文件
- 文件系统: 一种用于持久性存储的系统抽象- 在存储上: 组织,控制,导航,访问和检索数据- 在大多数计算机系统包含文件系统- 个人电脑,服务器,笔记本电脑- ipod,tivo,机顶盒,手机,电脑- google可能也是由一个文件系统构成的
- 文件: 文件系统中的一个单元的相关数据在操作系统中的抽象(文件系统包含一堆文件)
🌗1.1.2 文件系统功能
- 分配文件磁盘空间- 管理文件块(哪一块属于哪一个文件)- 管理空闲空间(哪一块是空闲的)- 分配算法(策略)
- 管理文件集合- 定位文件及其内容- 命名: 通过名字找到文件的接口- 最常见: 分层文件系统- 文件系统类型(组织文件的不同方式)
- 提供的便利及特征- 保护: 分层来保护数据安全- 可靠性,持久性: 保持文件的持久即使发生崩溃,媒体错误,攻击等
🌗1.1.3 文件和块:
- 文件属性: - 名称,类型,位置,大小,保护,创建者,创建时间,最久修改时间…
- 文件头: - 在存储元数据中保存了每个文件的信息,保存文件的属性,跟踪哪一块存储块属于逻辑上文件结构的哪个偏移
🌒1.2 文件描述符
打开一个文件会返回一个文件描述符
- 文件使用模式:- 使用程序必须在使用前先"打开"文件- 文件描述符是一个整数,但是不是一般整数,在OS中每一个进程打开文件,有一个打开表,文件描述符就是iindex是索引,根据索引找到项,打开项的内容
f = open(name, flag);
...
... = read(f, ...);
...
close(f);
- 内核跟踪每个进程打开的文件:- 操作系统为每个进程维护一个打开文件表- 一个打开文件描述符是这个表中的索引
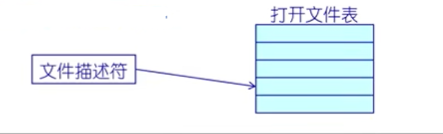
需要元数据来管理打开文件:
文件指针:指向最近的一次读写位置,每个打开了这个文件的进程都这个指针文件打开计数: 记录文件打开的次数 - 当最后一个进程关闭了文件时,允许将其从打开文件表中移除文件磁盘位置: 缓存数据访问信息访问权限: 每个程序访问模式信息
用户视图:
- 持久的数据结构
系统访问接口:
- 字节的集合(UNIX)
- 系统不会关心你想存储在磁盘上的任何的数据结构
操作系统内部视角:
- 块的集合(块是逻辑转换单元,而扇区是物理转换单元)
- 块大小<> 扇区大小: 在UNIX中, 块的大小是 4KB
怎样将磁盘块和操作系统文件对应起来(映射关系),对于磁是以扇区进行读写,对于真正读写是以字节读写





- 读写一个字节,对应着实际是读或写一个磁盘块,OS不会只给你读或者写一个字节(OS看到的是磁盘块,而用户看到抽象的一维空间)
🌒1.3 目录
- 以分层的方式存放文件,便于查找
- 文件以目录的方式组织起来
- 目录是一类特殊的文件:- 每个目录都包含了一张表<name, pointer to file header>
- 目录和文件的树形结构:- 早期的文件系统是扁平的(只有一层目录)
- 层次名称空间:
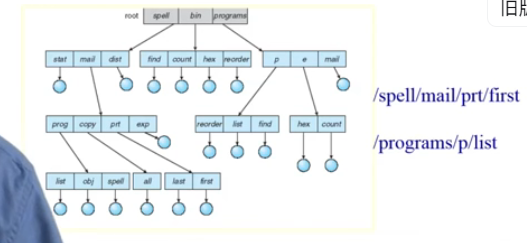
- 典型操作:- 搜索文件- 创建文件- 删除文件- 枚举目录- 重命名文件- 在文件系统中遍历一个路径
- 操作系统应该只允许内核模式修改目录:- 确保映射的完整性- 应用程序能够读目录(ls)
- 文件名的线性列表,包含了指向数据块的指针:- 编程简单,执行耗时
- Hash表 - hash数据结构的线性表:- 减少目录搜索时间- 碰撞(俩个文件名的hash值相同)- 固定大小
- 名字解析: 逻辑名字转换成物理资源(如文件)的过程:- 在文件系统中: 到实际文件的文件名(路径)- 遍历文件目录直到找到目标文件
- 举例: 解析"/bin/ls":- 读取root的文件头(在磁盘固定位置)- 读取root的数据块: 搜索bin项- 读取bin的文件头- 读取bin的数据块: 搜索ls项- 读取ls的文件头
- 当前工作目录:- 每个进程都会指向一个文件目录用于解析文件名- 允许用户指定相对路径来代替绝对路径
挂载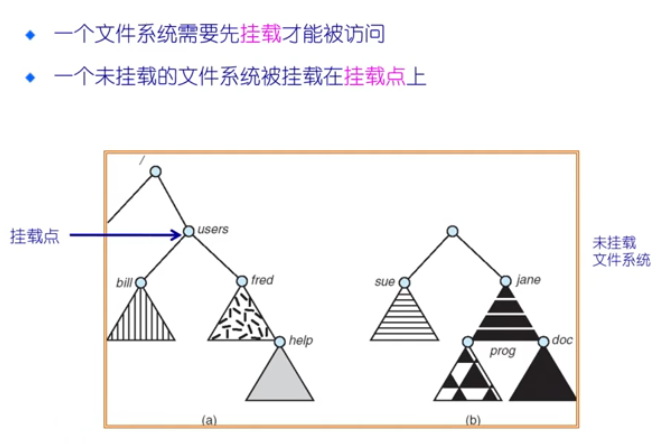
🌒1.4 文件别名
- 一个文件有多个名字(一个文件在不同的用户里,有不同的命名,这样便于分类和查找文件)
- 实现方式- 硬链接:在目录中存储的是文件项,文件项是不一样的,但是都指向同一个文件的内容(内容是放在磁盘上的)- 软链接:这个文件的内容存储的是另一个文件的路径名
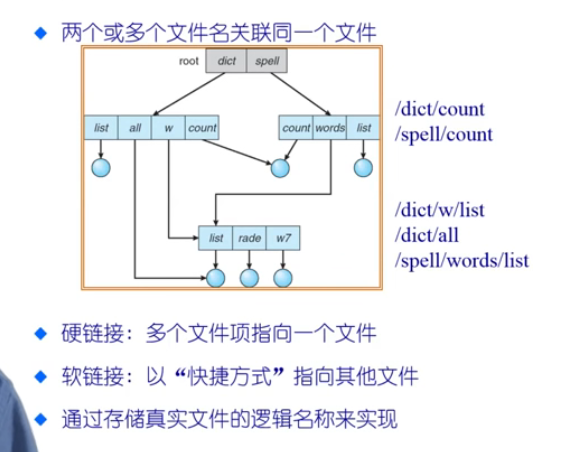
- 如果删除一个有别名的文件会如何呢? :- 这个别名将成为一个悬空指针
- Backpointers 方案:- 每个文件有一个包含多个backpointers的列表,所以删除所有的Backpointers- backpointers使用菊花链管理
- 添加一个间接层: 目录项数据结构- 链接: 已存在文件的另外一个名字(指针)- 链接处理: 跟随指针来定位文件
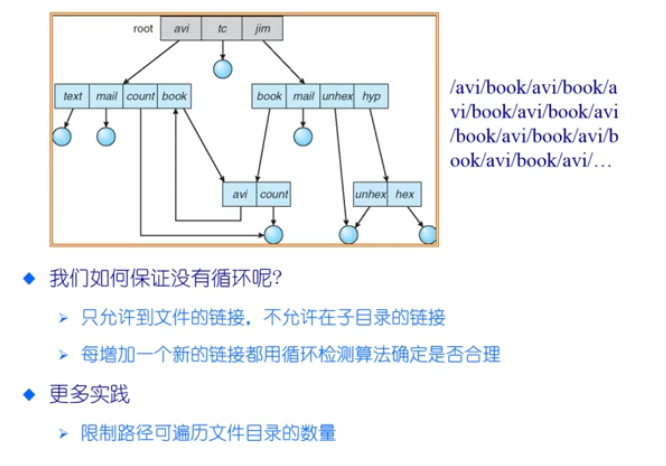
🌒1.5 文件系统种类
- 磁盘文件系统:- 文件存储在数据存储设备上,如磁盘;- 例如: FAT,NTFS,ext2,3,ISO9660等
- 数据库文件系统:- 文件根据其特征是可被寻址的;- 例如: WinFS
- 日志文件系统:- 记录文件系统的修改,事件;- 例如: journaling file system
- 网络,分布式文件系统:- 例如: NFS,SMB,AFS,GFS
- 特殊,虚拟文件系统
🌔2. 虚拟文件系统
- 有各种各样类型的文件系统,如果只单纯让应用程序来进行直接写文件系统,很麻烦,而OS将复杂的东西抽象成一个简单的接口(例如open,read等)给用户,用户直接访问接口,就可以处理不同的文件系统(并且通过虚拟文件系统层屏蔽了底层的差异性)。
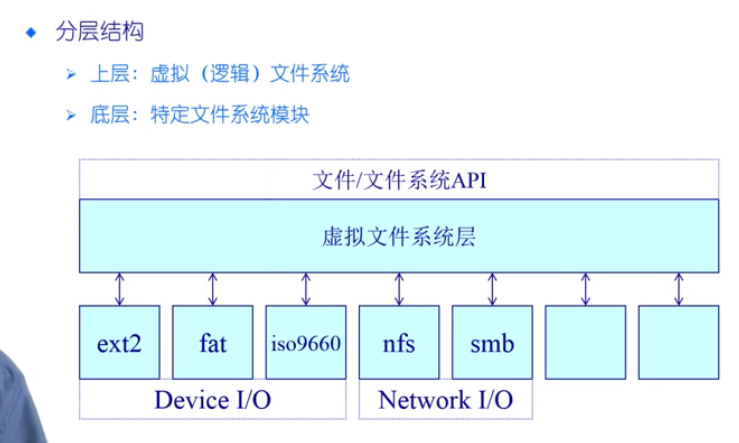
- 目的:- 对所有不同文件系统的抽象
- 功能:- 提供相同的文件和文件系统接口- 管理所有文件和文件系统关联的数据结构- 高效查询例程,遍历文件系统- 与特定文件系统模块的交互
数据结构
- 卷控制块(UNIX: “superblock”)- 每个文件系统一个- 文件系统详细信息- 块,块大小,空余块,计数,指针等
- 文件控制块(UNIX: “vnode” or “inode”)- 每个文件一个- 文件详细信息- 许可,拥有者,大小,数据库位置等
- 目录节点(Linux: “dentry”)- 每个目录项一个(目录和文件)- 将目录项数据结构及树形布局编码成树形数据结构- 指向文件控制块,父节点,项目列表等
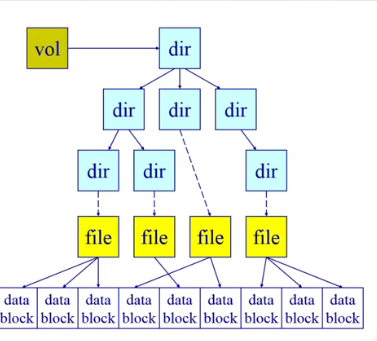
抽象文件系统图
- 它有一个总控制节点(卷控制块),在卷控制块下,有一堆目录,目录可以管理子目录也可以管理文件
- 子节点可以指向文件内容(数据块放到磁盘里)
- 卷控制块、文件控制块、目录节点都会映射到磁盘的一个或者多个扇区(数据也要放在磁盘中,有专门的数据块管理数据)

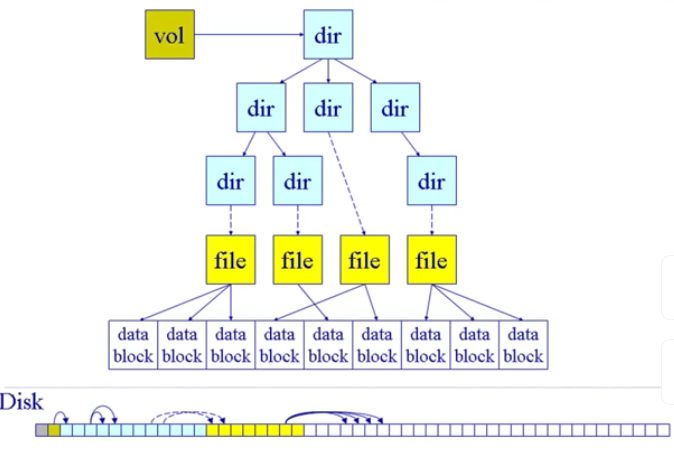
🌔3. 数据块缓存
数据缓冲技术
访问硬盘的速度和访问内存的速度不一样,因为在内存中放一块缓存,把经常用到的或者是当前访问的数据,从硬盘读到内存中,接下来访问都是访问内存,提高效率··
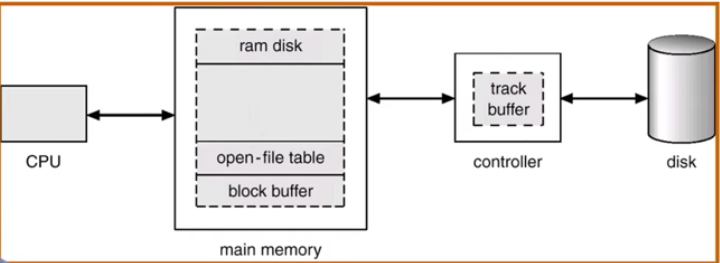
数据缓冲的方式
- 数据块按需读入内存:- 提供 read() 操作- 预读: 预先读取后面的数据块
- 数据块使用后被缓存:- 假设数据将会再次被使用- 写操作可能被缓存和延迟写入
- 两种数据块缓存方式:- 普通缓冲区缓存- 页缓存: 同一缓存数据块和内存页
将缓存和页管理结合,实现基于分页的缓存机制,使得数据更好的给上层使用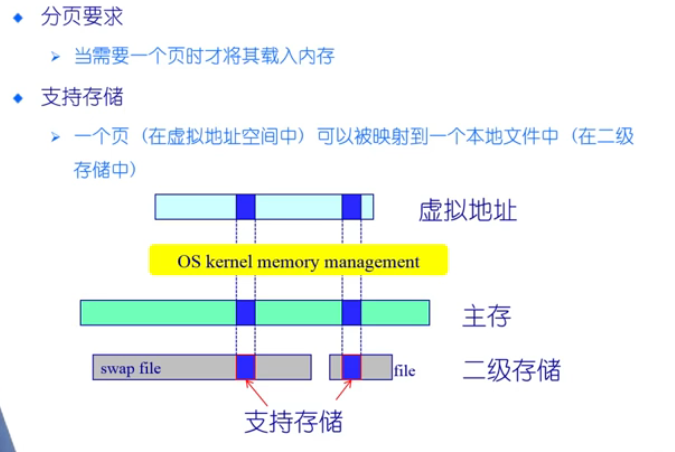

🌔4. 打开文件的数据结构
打开文件实际上是把存在硬盘上的文件的文件控制块的内容读进内存中,把关键和相关信息放在文件表中,文件表有专门的项,把项的索引index,返回给应用程序(fd = open(),fd就是索引,基于项找到系统的文件表)
- 打开文件描述:- 每个被打开的文件一个- 文件状态信息- 目录项,当前文件指针,文件操作设置等
- 打开文件表:- 一个进程一个- 一个系统级的- 每个卷控制块也会保存一个列表- 所以如果有文件被打开将不能被卸载
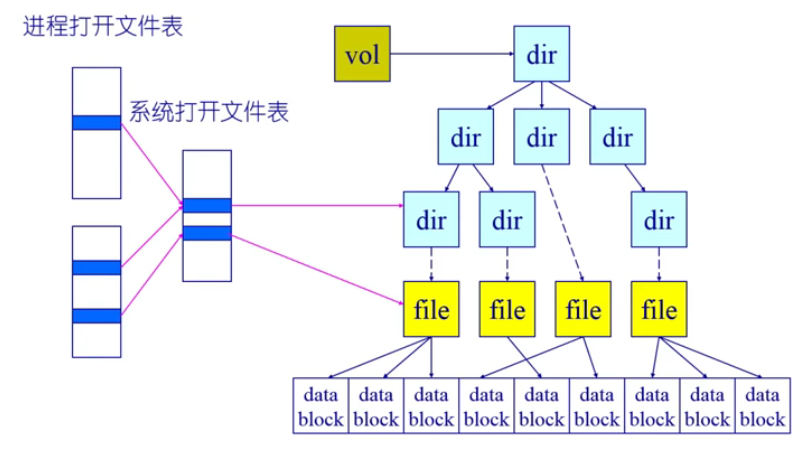
- 一些操作系统和文件系统提供该功能
- 调节对文件的访问
- 强制和劝告:- 强制 - 根据锁保持情况和需求拒绝访问- 劝告 - 进程可以查找锁的状态来决定怎么做
🌒4.1
总结:打开文件的具体步骤
- 进程做了打开文件操作后,他会返回文件描述符
fd(也就是索引) index会指出在进程的打开文件表的具体位置,取出项- 基于项找到系统层面的打开文件表(可能是不同进程打开同一个文件,在系统文件表中记录一项就可以)
- 基于系统文件表中的项,会进一步找到(如果是目录或者文件有不同的处理),假如是文件
- 会知道文件的节点信息,节点信息会包含文件具体位置,在进行
read和write时,会有一个偏移量,找到具体位置 offset会经过文件控制块的准换,转换成磁盘的扇区编号- 文件系统将扇区内容读到内存中,在将这些数据从内存缓冲区取出来,交给应用程序
🌔5. 文件分配
- 大多数文件都很小:- 需要对小文件提供强力的支持- 块空间不能太小
- 一些文件非常大:- 必须支持大文件(64-bit 文件偏移)- 大文件访问需要相当高效
- 如何为一个文件分配数据块
- 分配方式:- 连续分配- 链式分配- 索引分配
- 指标:- 高效: 如存储利用(外部碎片)- 表现: 如访问速度
🌒5.1 连续分配

🌒5.2 链式分配
- 访问是串联访问,不支持随机访问
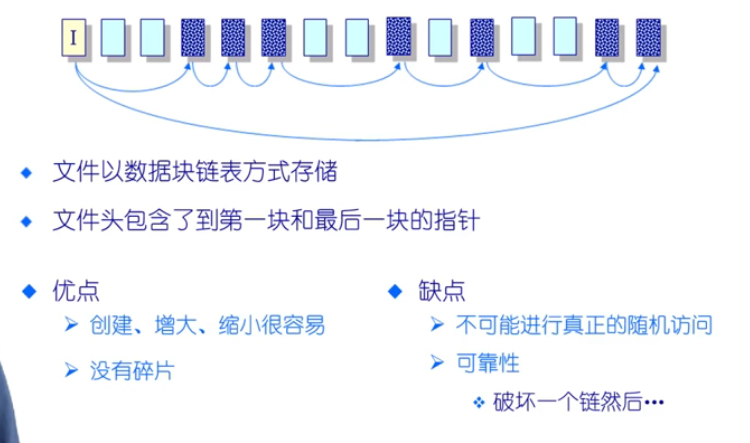
🌒5.3 索引分配
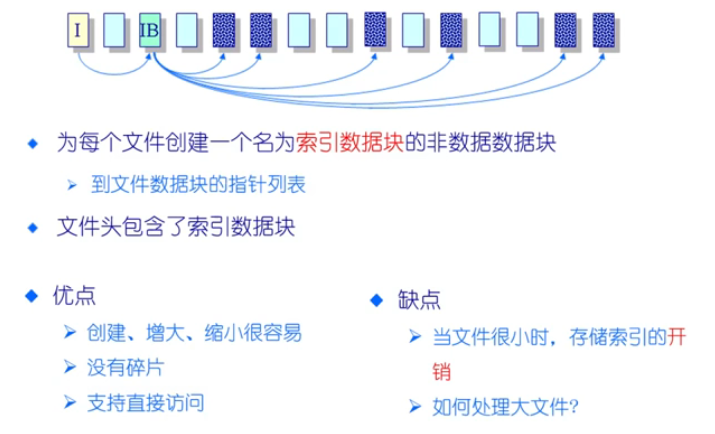
对大文件的管理
- 将索引块分级,有一级、二级、三级,实现对大文件的支持,但是开销大
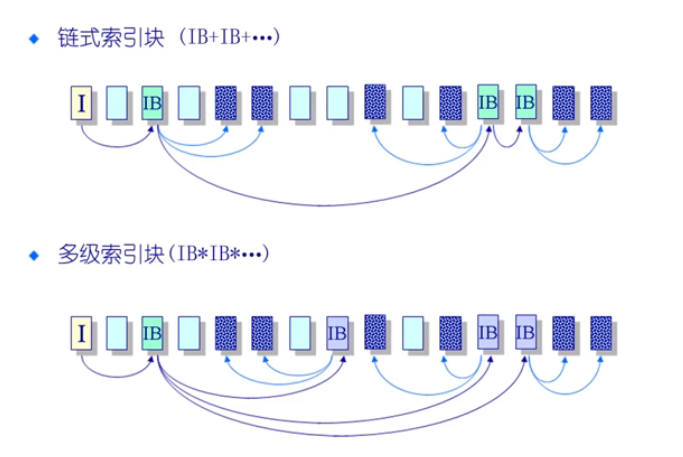
早起Unix管理方式使用的是多级索引块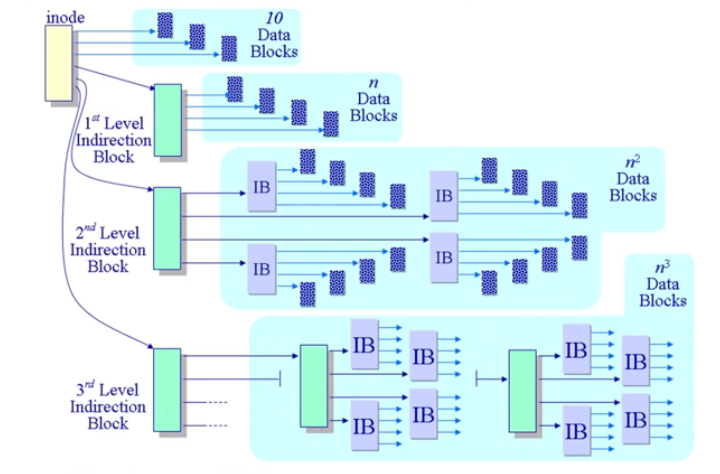
🌔6. 空闲空间列表(磁盘角度)
1.跟踪在存储中的所有未分配的数据块
2.空闲空间列表存储在哪里?
3.空闲空间列表的最佳数据结构怎么样?
- 用位图代表空闲数据块列表: -
11111101101110111- 如果i = 0表明数据块i是空闲的,反之是分配的
将整个位图从磁盘导入到内存中去,定期需要将信息更新到硬盘上去,来保证数据的一致性(假如断电了,要及时更新到硬盘中去)
- 使用简单但是可能会是一个big vector:-
160GB disk → 40M blocks → 5MB worth of bits- 然而,如果空闲空间在磁盘中均匀分布,那么再找到"0"之前需要扫描磁盘上数据块总数 / 空闲块的数目
问题:要确保内存和磁盘的一致性(因为位图最开始存在硬盘上的,为了提高效率将它读进内存中,在硬盘置位1后,结果1没有及时写到内存中去)解决办法:先在磁盘上置1,然后再分配bolck,在将内存的bit置为1
利用链表和分组的方式查找空闲空间列表
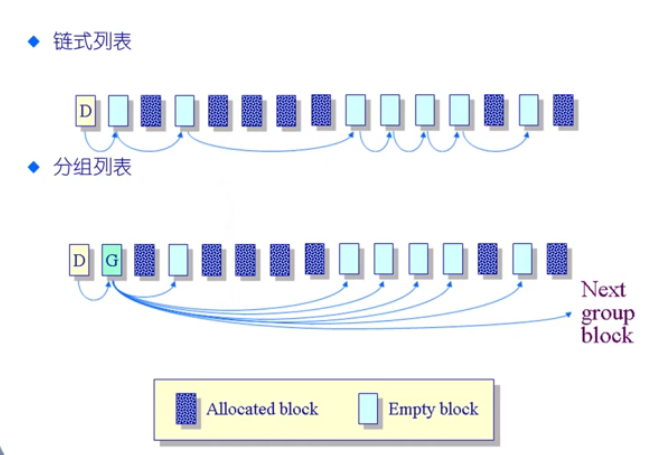
🌔7. 多磁盘管理—RAID
总结:
1. 虚拟文件系统:屏蔽底层具体的差异性,给上层应用一个更简洁的访问接口2. 数据块缓存:提高访问效率,减少对IO的访问次数,提高系统的整体效率3. 打开文件的数据结构:打开文件后通过文件描述符(fd),就能对文件进行读写4. 文件分配:文件中具体的内容,怎么分配,不同的分配方法应对不同的情况(随机读、顺序读、扩展、删除、只读等)5. 空闲空间:基于位图,基于链式管理空闲空间、数据块、磁盘块
- 磁盘是一个机械设备,通过分区来减少寻道
- 结构:- 由一个一个盘片组成,有一个磁头在来回移动来寻道- 当寻道后,在一个圈里有不同的扇区,然后探针来读取相应的数据,将数据读到内存中去
注意:最慢的一部分就是磁头的前后移动(后续有一些方法来减少访问开销)
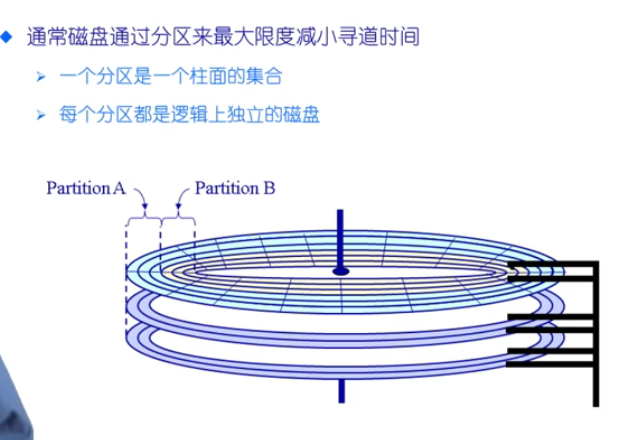
一个典型的文件系统是由分区组成的,磁盘可以分不同的分区,不同的分区由不同的文件系统组成
卷:把多个disk放到一个卷里管理,可以将一个文件系统扩展到多个磁盘上去分区: 硬件磁盘的一种适合操作系统指定格式的划分卷: 一个拥有一个文件系统实例的可访问的存储空间 - 通常常驻在磁盘的单个分区上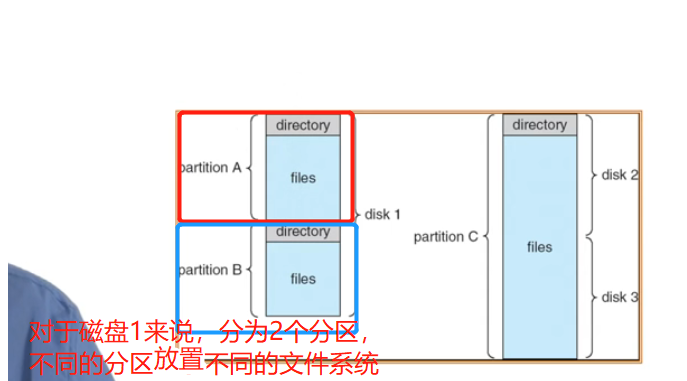
- 文件系统位于不同的磁盘上,那可以俩个磁盘并行工作,来提升文件系统访问效率
- 如果俩个磁盘存放相同的内容,来提高磁盘的可靠性
- 使用多个并行磁盘来增加: - 吞吐量(通过并行),- 可靠性和可用性(通过冗余)
- RAID - 冗余磁盘阵列:- 各种磁盘管理技术;- RAID levels: 不同RAID分类,如RAID-0,RAID-1,RAID-5
- 实现:- 在操作系统内核: 存储,卷管理; RAID硬件控制器(IO)
为什么通过RAID来提升访问效率
- 将数据放到相互独立的硬盘中,而每个硬盘可以并行的工作,实现速度的并行访问
RAID-0(提高吞吐率)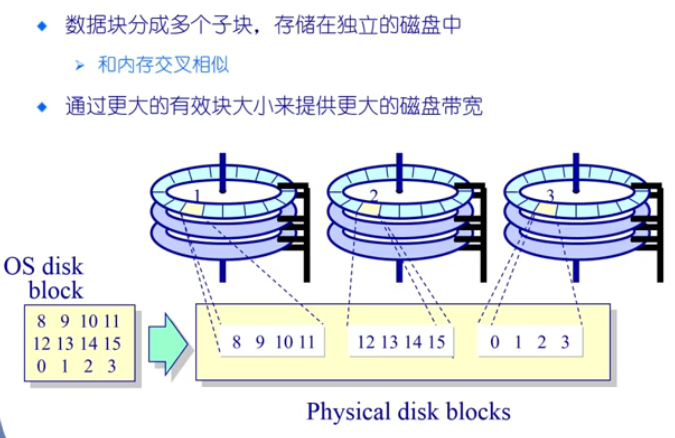
RAID-1(提高可靠性)
- 从OS中做一次操作,最后映射为像俩个硬盘中写入同样的数据

RAID-4(可靠+吞吐)
- 出现一个故障可以恢复,要是都坏就无法恢复
- 往1—4磁盘中任意一个写入数据,那么也要往
Parity Disk中写数据 - 瓶颈:
Parity Disk读写频繁(可以将Parity Disk的开销均匀的分布在disk中,而不是集中在一个disk中)
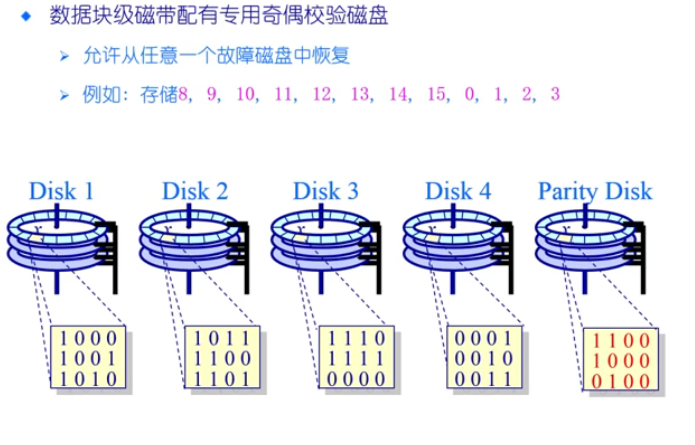
RAID-5
- 将奇偶校验的块均匀分布在不同的disk中,使得每个块的开销是一样的(校验是均匀,访问是并行的),即保证高可靠性,又提高效率
- 缺点:只能一个disk出现错误,多个disk出现错误就无法进行
每个条带快有一个奇偶校验块,允许有一个磁盘错误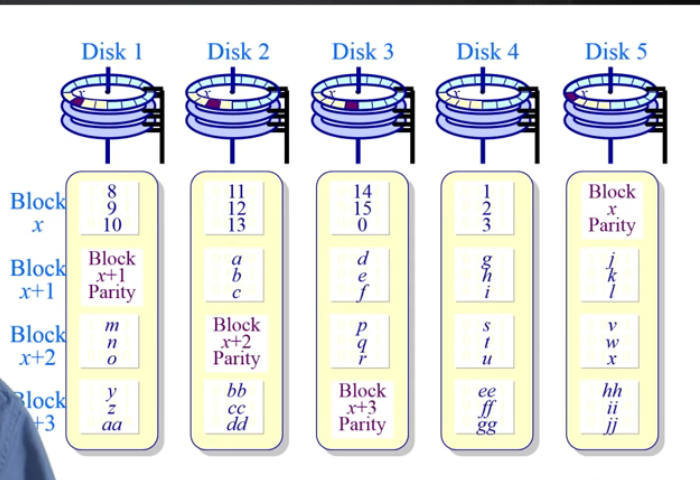
RAID-6
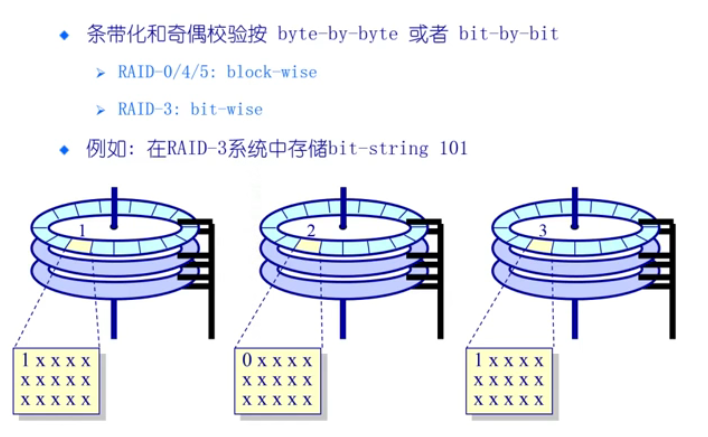
两个冗余块,有一种特殊的编码方式,允许两个磁盘错误- 奇偶校验的单位是一个bit或者一个块,或者byte来做。(这里使用块)
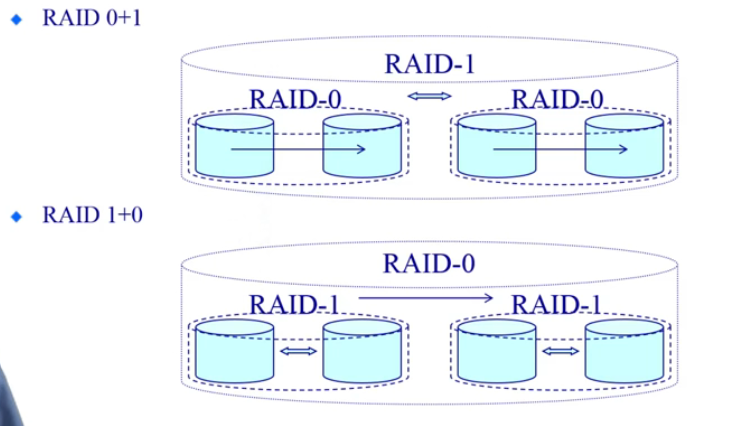
将RAID1 和 RAID 0进行分层
🌔8. 磁盘调度
- RAID提高磁盘访问效率
- 磁盘调度:在OS层面重新组织IO请求的顺序,来有效的减少磁盘的访问开销(减少IO操作)
- 读取或写入时,磁头必须被定位在期望的磁道,并从所期望的扇区开始
- 寻道时间:- 定位到期望的磁道所花费的时间
- 旋转延迟:- 从扇区的开始处到到达目的处花费的时间
平均旋转延迟时间 = 磁盘旋转一周时间的一半
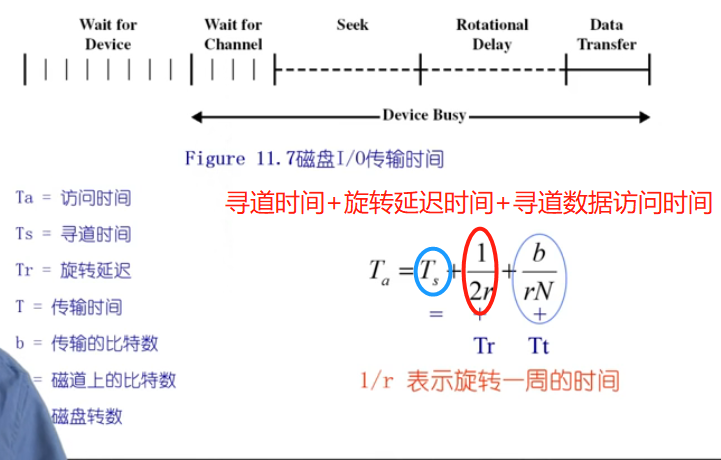
- 寻道时间是性能上区别的原因
- 对单个磁盘,会有一个IO请求数目
- 如果请求是随机的,那么会表现很差(只要寻道一圈就可以把全部数据读取出来,而不用来回跳,导致开销大)
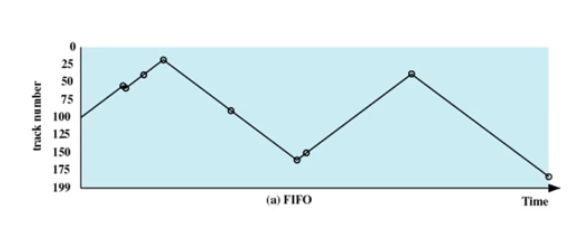
🌒8.1 FIFO
- 按顺序处理请求
- 公平对待所有进程
- 在有很多进程的情况下,接近随机调度的性能

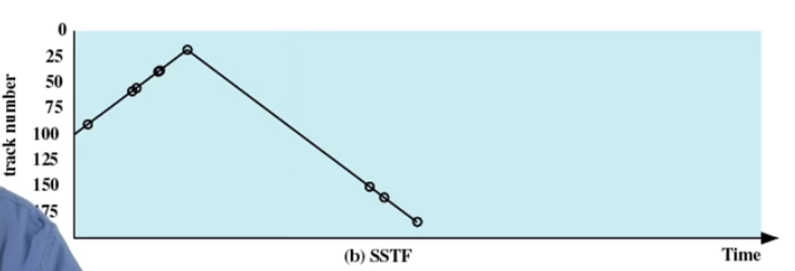
🌒8.2 最短服务优先:
- 选择
从磁臂当前位置需要移动最少的IO请求 - 总是选择最短寻道时间
缺点:(访问的不公平+不均匀)
- 如果请求频繁出现在当前访问的位置,另外一些请求离当前访问位置很远(导致次头在当前位置来回移动),而离他很远的访问请求,会持续得不到服务,导致饥饿
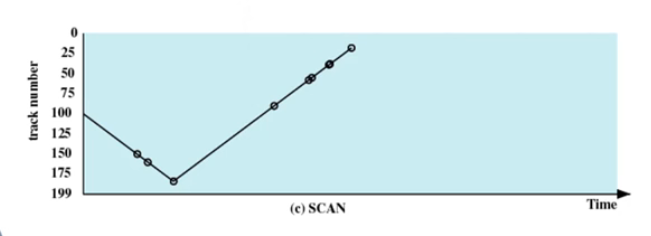
🌒8.3 skan(电梯算法)
磁头顺着一个方向移动,移到头,在移动回来,类似电梯,可以公平的让所有访问请求得到访问,但是他要到达disk的最高端和最低端
磁臂在一个方向上移动,满足所有为完成的请求,直到磁臂到达该方向上最后的磁道- 调换方向
- 也叫
elevator algorithm
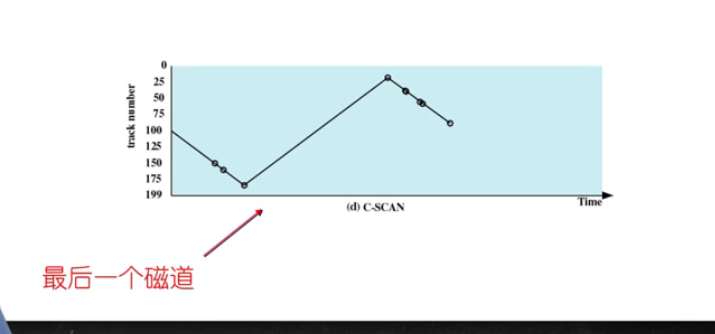
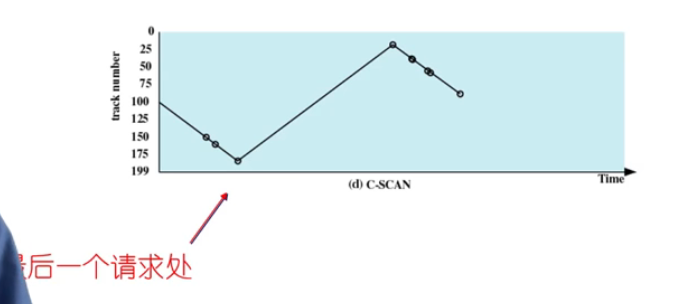
🌒8.4 c-skan
- 限制了
仅在一个方向上扫描 - 当最后一个磁道也被访问过了后,磁臂快速返回到磁盘的
最开始的位置再次进行扫描 - skan有些请求靠近0的位置它等的时间长。而c-skan对请求的位置建立有序的过程
🌒8.5 c-loop(c-skan改进)
- 磁臂先到达该方向上
最后一个请求处,然后立即反转 它不是到的磁盘的终点,而是到底磁盘的最后一个请求位置,然后反转
一共将了三种情况下的调度算法
CPU调度(进程调度)磁盘调度页面换入换出
本文转载自: https://blog.csdn.net/weixin_45043334/article/details/126652312
版权归原作者 小呆鸟_coding 所有, 如有侵权,请联系我们删除。
版权归原作者 小呆鸟_coding 所有, 如有侵权,请联系我们删除。