
一、前言
在AI大模型百花齐放的时代,很多人都对新兴技术充满了热情,都想尝试一下。但是,实际上要入门AI技术的门槛非常高。除了需要高端设备,还需要面临复杂的部署和安装过程,这让很多人望而却步。不过,随着开源技术的不断进步,使得入门AI变得越来越容易。通过使用Ollama,您可以快速体验大语言模型的乐趣,不再需要担心繁琐的设置和安装过程。
二、术语
2.1、Ollama
是一个强大的框架,用于在 Docker 容器中部署 LLM(大型语言模型)。它的主要功能是在 Docker 容器内部署和管理 LLM 的促进者,使该过程变得简单。它可以帮助用户快速在本地运行大模型,通过简单的安装指令,用户可以执行一条命令就在本地运行开源大型语言模型。
Ollama 支持 GPU/CPU 混合模式运行,允许用户根据自己的硬件条件(如 GPU、显存、CPU 和内存)选择不同量化版本的大模型。它提供了一种方式,使得即使在没有高性能 GPU 的设备上,也能够运行大型模型。
2.2、Qwen1.5
Qwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a large amount of data. In comparison with the previous released Qwen, the improvements include:
- 6 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, and 72B;
- Significant performance improvement in human preference for chat models;
- Multilingual support of both base and chat models;
- Stable support of 32K context length for models of all sizes
- No need of trust_remote_code.
三、前置条件
3.1、Ollama安装
下载地址:Download Ollama on macOS

支持macOS、Linux以及windows,此处以windows操作系统为例:

点击OllmaSetup.exe进行安装,当前安装版本为0.1.27
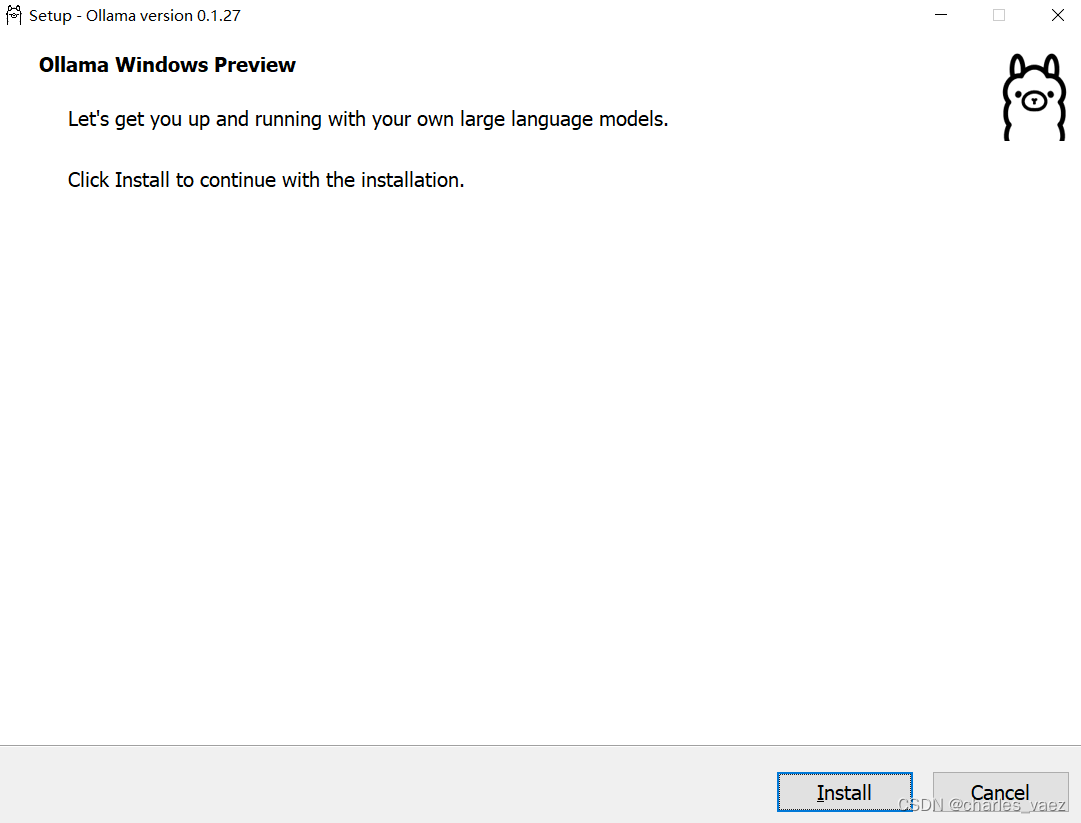
安装完成后,在C:\Users\用户名\AppData\Local\Ollama目录下,有Ollama的配置及日志文件

也可以在右下角快速点开
查看版本

四、使用方式
4.1、运行Qwen1.5-1.8B-Chat模型
ollama run qwen:1.8b


五、测试
5.1、命令行方式测试

5.2、代码方式测试
默认Ollama api会监听11434端口,可以使用命令进行查看
netstat -ano | findstr 11434

** 安装requests库**
pip install requests -i https://pypi.douban.com/simple
# -*- coding = utf-8 -*-
import json
import sys
import traceback
import logging
#######################日志配置#######################
import requests
from requests.adapters import HTTPAdapter
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s [%(levelname)s]: %(message)s', # 指定日志输出格式
datefmt='%Y-%m-%d %H:%M:%S' # 指定日期时间格式
)
# 创建一个日志记录器
formatter = logging.Formatter('%(asctime)s [%(levelname)s]: %(message)s') # 指定日志输出格式
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
if sys.platform == "linux":
# 创建一个文件处理器,将日志写入到文件中
file_handler = logging.FileHandler('/data/logs/app.log')
else:
# 创建一个文件处理器,将日志写入到文件中
file_handler = logging.FileHandler('E:\\logs\\app.log')
file_handler.setFormatter(formatter)
# 创建一个控制台处理器,将日志输出到控制台
# console_handler = logging.StreamHandler()
# console_handler.setFormatter(formatter)
# 将处理器添加到日志记录器中
logger.addHandler(file_handler)
# logger.addHandler(console_handler)
DEFAULT_MODEL = "qwen:1.8b-chat"
DEFAULT_IP='127.0.0.1'
DEFAULT_PORT=11434
DEFAULT_MAX_TOKENS = 32768
DEFAULT_CONNECT_TIMEOUT=3
DEFAULT_REQUEST_TIMEOUT=60
DEFAULT_MAX_RETRIES=0
DEFAULT_POOLSIZE=100
class Model:
def __init__(self):
self.headers = {"User-Agent": "Test Client"}
self.s = requests.Session()
self.s.mount('http://', HTTPAdapter(pool_connections=DEFAULT_POOLSIZE, pool_maxsize=DEFAULT_POOLSIZE, max_retries=DEFAULT_MAX_RETRIES))
self.s.mount('https://', HTTPAdapter(pool_connections=DEFAULT_POOLSIZE, pool_maxsize=DEFAULT_POOLSIZE, max_retries=DEFAULT_MAX_RETRIES))
def chat(self, message, history=None, system=None, config=None, stream=True):
if config is None:
config = {'temperature': 0.45, 'top_p': 0.9, 'repetition_penalty': 1.2, 'max_tokens': DEFAULT_MAX_TOKENS,'n':1}
logger.info(f'config: {config}')
messages = []
if system is not None:
messages.append({"role": "system", "content": system})
if history is not None:
if len(history) > 0 and len(history) % 2 == 0:
for his in history:
user,assistant = his
user_obj = {"role": "user", "content": user}
assistant_obj = {"role": "assistant", "content": assistant}
messages.append(user_obj)
messages.append(assistant_obj)
if message is None:
raise RuntimeError("prompt不能为空!")
else:
messages.append({"role": "user", "content": message})
logger.info(messages)
try:
merge_pload = {"model": DEFAULT_MODEL, "messages": messages, **config}
logger.info(merge_pload)
response = self.s.post(f"http://{DEFAULT_IP}:{DEFAULT_PORT}/api/chat", headers=self.headers,
json=merge_pload, stream=stream, timeout=(DEFAULT_CONNECT_TIMEOUT, DEFAULT_REQUEST_TIMEOUT))
str = ''
for msg in response:
# logger.info(msg)
if msg and len(msg) > 0:
decode_msg = msg.decode('UTF-8')
if '\n' in decode_msg :
if len(str) == 0:
obj = json.loads(decode_msg)
if 'message' in obj:
content = obj['message']['content']
if content is not None:
yield content
else:
str = str + decode_msg
obj = json.loads(str)
if 'message' in obj:
content = obj['message']['content']
if content is not None:
str=''
yield content
else:
str = str + decode_msg
except Exception as e:
traceback.print_exc()
if __name__ == '__main__':
model = Model()
message = '我家有什么特产?'
system = 'You are a helpful assistant.'
history = [('hi,你好','你好!有什么我可以帮助你的吗?'),('我家在广州,很好玩哦','广州是一个美丽的城市,有很多有趣的地方可以去。'),]
config = {'temperature': 0.45, 'top_p': 0.9, 'repetition_penalty': 1.2, 'max_tokens': 8192}
gen = model.chat(message=message, history=history, system=system, config=config, stream=True)
results = []
for value in gen:
results.append(value)
str = ''.join(results)
logger.info(str)
模型参数:

Ollama Api返回的数据格式以\n结尾,但由于流式返回,可能存在多行输出再返回\n的情况:

测试结果:

六、附带说明
6.1、各操作系统下的安装步骤
https://github.com/ollama/ollama
6.2、Ollama支持的模型库
https://ollama.com/library
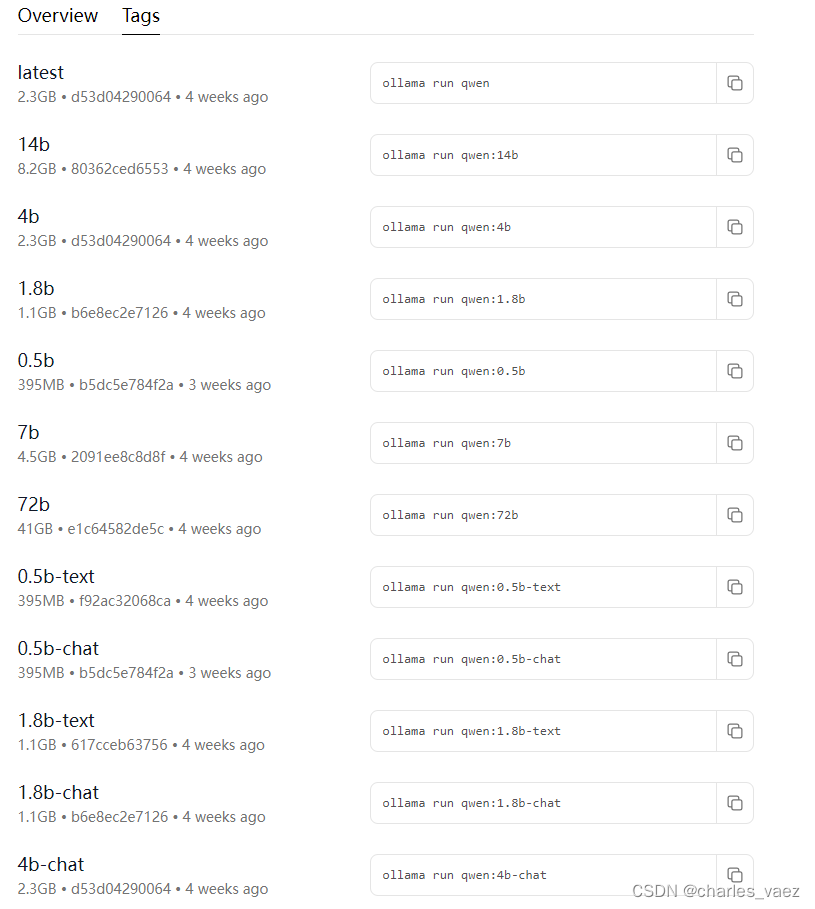
6.3、运行各规格qwen模型的命令
https://registry.ollama.ai/library/qwen/tags
6.4、问题

重试几次或者换另外规格的模型
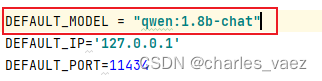
6.5、代码中传递给Ollama Api的模型参数,要和运行的模型一致,即

6.6、Ollama常用命令
# list

# show
# delete
等等,可以查阅:https://github.com/ollama/ollama/blob/main/cmd/cmd.go
标签:
深度学习
本文转载自: https://blog.csdn.net/qq839019311/article/details/136474207
版权归原作者 开源技术探险家 所有, 如有侵权,请联系我们删除。
版权归原作者 开源技术探险家 所有, 如有侵权,请联系我们删除。