
创建Auto-Sommelier
2019年8月,我投入了我的第一个自然语言处理(NLP)项目,并在我的网站上托管了自动侍酒师(Auto-Sommelier)。使用TensorFlow 1和Universal Sentence Encoder,我允许用户描述他们理想的葡萄酒,并返回与查询相似的描述的葡萄酒。该工具将葡萄酒评论和用户输入转换为向量,并计算用户输入和葡萄酒评论之间的余弦相似度,以找到最相似的结果。
余弦相似度是比较文档相似度的一种常用方法,因为它适用于词频等对分析非常重要的数据。它反映了单个矢量维度的相对比较,而不是绝对比较。在这篇文章中,我不会深入研究余弦相似度背后的数学,但是要理解它是一个内积空间中两个非零向量之间的相似性度量。
是时候改进了
尽管该模型仍然有效,但自2019年以来,自然语言处理已经取得了巨大的进步。使用像HuggingFace这样的工具,将句子或段落转换成向量,可以用于语义相似等自然语言处理任务,这是前所未有的简单。使用最新的技术和语言模型重构我的代码将使其性能更好。
在本教程中,我将解释如何使用HuggingFace Transformers库、Non-Metric Space库和Dash库来构建一个新的和改进的自动侍酒师。完整的代码和GitHub链接可以在文章的底部找到。
数据
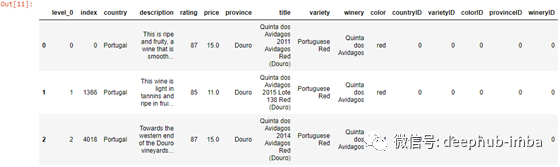
这些葡萄酒数据来自kaggle.com上的葡萄酒评论数据集。原始文件包含约13万行数据,包括国家、描述、标题、品种、酒厂、价格和评级等列。。
在我把数据放入一个dataframe后,我删除了包含重复描述的行和有空价格的行。我还将数据限制在获得超过200条评论的葡萄酒品种上。
通过剔除评论数少于200的品种,我得到了54个葡萄酒品种。清理完null和重复的数据后,剩下100228行。通过谷歌搜索剩下的葡萄酒品种,我添加了一个“颜色”列,这样用户就可以根据想要的葡萄酒颜色来限制搜索。
导入依赖项和数据
由于数据已经是一个sqlite文件,所以很容易将数据连接并加载。按照三个步骤加载库、数据和DataFrame。
- 导入pandas和sqlite3库。
- 连接到sqlite文件。
- 将数据加载到一个pandas DataFrame中。
#Import dependencies
import numpy as np
import pandas as pd
import sqlite3
from sqlite3 import Error
import texthero as hero
from texthero import preprocessing
from sentence_transformers import SentenceTransformer, util
import nmslib
import time
import datetime
#Establish connection to sqlite database
conn = sqlite3.connect("wine_data.sqlite")#load the data into a pandas DataFrame
df = pd.read_sql("select * from wine_data", conn)
我还导入了本教程中将要使用的其他库。我会更详细地介绍它们。使用pandas read_sql函数使用原始SQL生成一个df。数据集中有16列和100228行。
注意:将所有文本转换为矢量可能需要一些时间,所以如果你只是想尝试一下,我建议只使用20,000条记录来快速训练。
HuggingFace🤗Transformers
如果你在过去的一年中参与了自然语言处理(NLP)领域,你可能已经听说过HuggingFace🤗。HuggingFace是一个专注于自然语言处理的人工智能和深度学习平台,目标是普及人工智能技术。他们简化了应用和微调预先训练的语言模型。
transformer是一个带有模型的开源库,允许用户基于BERT、XLM、DistilBert等通用架构实现最先进的深度学习模型。它是建立在PyTorch、TensorFlow和Jax之上的,众所周知,这些框架之间具有良好的互操作性。
pip install transformers
在本例中,我将使用distilBERT-base-uncase模型,因为它与我们的用例、语义相似性表现良好。它将文本转换为768维的向量。如果你不想使用distilBERT,可以使用所有的HuggingFace模型来寻找句子相似度。这个模型是未知的,这意味着它不区分大小写。关于模型的详细信息,请查阅官方文件。
要实现该模型,请遵循以下步骤:
使用distilBERT-base-uncase模型实例化SentenceTransformer。
调用encode并将葡萄酒描述传递给它。设置convert_to_tensor = True参数。
#load the distilbert model
distilbert = SentenceTransformer('distilbert-base-uncased')#generate the embeddings for the wine reviews
embeddings = distilbert.encode(df['description'], convert_to_tensor=True)
注意:如果您以前从未下载过该模型,您将看到它下载并可能弹出一些消息。这是正常的。
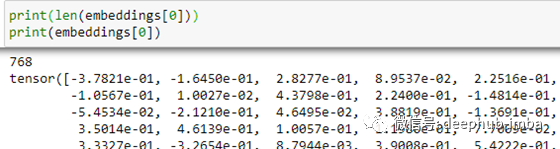
一旦该过程完成,文本描述将被转换为长度为768的向量。我们可以检查长度和嵌入,以确保它看起来像预期的:
为了使向量更容易分析,使用numpy将数据从张量对象转换为列表对象,然后将列表添加到pandas DataFrame。
#add embeddings to dataframe
df['distilbert'] = np.array(embeddings).tolist()
#show the top row
df.head(1)

创建搜索索引
当使用谷歌或Bing这样的搜索引擎时,用户希望很快得到结果。为了以闪电速度搜索结果集,我们可以使用轻量级和高效的非度量空间库(NMSLIB)。
使用pip安装:
pip install nmslib
如前所述,我们希望使用余弦相似度作为度量,用于比较用户输入和葡萄酒描述。我们需要找到最接近搜索向量的向量。使用暴力循环技术搜索和排序数据可能代价昂贵且速度缓慢。相反,为数据点创建一个索引则会快很多。
创建搜索余弦相似度指数是非常流程化的:
初始化一个新的索引,方法为hnsw,空间为余弦。
使用addDataPointBatch方法向索引添加嵌入项。
使用createIndex方法使用数据点创建索引。
# initialize a new index, using a HNSW index on Cosine Similarity
distilbert_index = nmslib.init(method='hnsw', space='cosinesimil')
distilbert_index.addDataPointBatch(embeddings)
distilbert_index.createIndex({'post': 2}, print_progress=True)
如果你想保存索引并稍后加载它(比如在生产服务器上),请使用下面的样板代码:
#Save a meta index and the data
index.saveIndex('index.bin', save_data=True)
#Re-intitialize the library, specify the space
newIndex = nmslib.init(method='hnsw', space='cosinesimil_sparse')
#Re-load the index and the data
newIndex.loadIndex('sparse_index.bin', load_data=True)
创建搜索功能
现在已经对数据进行了向量化,并且填充了搜索索引,现在应该创建接受用户查询并返回类似葡萄酒的函数。
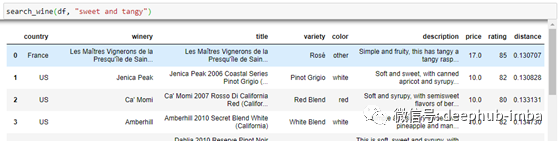
search_wine函数将接受两个输入:DataFrame和UserQuery。用户查询将使用encode转换为一个向量,就像我们对葡萄酒描述所做的那样。然后,可以使用NMSLIB返回用户查询向量的k个最近邻。我把k设为20,但你可以随意实验。
def search_wine(dataframe, userQuery):
if dataframe is not None and userQuery is not None:
df = dataframe.copy()
query = distilbert.encode([userQuery], convert_to_tensor=True)
ids, distances = distilbert_index.knnQuery(query, k=20)
matches = []
for i, j in zip(ids, distances):
matches.append({'country':df.country.values[i]
, 'winery' : df.winery.values[i]
, 'title' : df.title.values[i]
, 'variety': df.variety.values[i]
, 'color' : df.color.values[i]
, 'description': df.description.values[i]
, 'price': df.price.values[i]
, 'rating': df.rating.values[i]
, 'distance': j
})
return pd.DataFrame(matches)
注意,返回的结果作为字典添加到列表中。这使得将结果转换回df变得很容易。对于距离值,越小越好。例如,距离为0意味着两个向量是相同的。
测试:
可视化
除了文本搜索之外,我们还可以使用降维技术在二维空间中绘制葡萄酒。使用Texthero库,很容易应用t-SNE算法来降低向量的维数并将它们可视化。实际上,Texthero使用Plotly来制作交互式图表。
t-SNE (t-分布式随机邻域嵌入)是一种用于高维数据可视化的机器学习算法。t-SNE技术采用非线性降维。
对数据中的蒸馏器向量列应用t-SNE。
df['tsnedistilbert'] = hero.tsne(df['distilbert'])
使用texthero创建散点图。
#create scatter plot of wines using the
hero.scatterplot(df, col='tsnedistilbert'
, color='variety'
, title="Wine Explorer"
, hover_data = ['title','variety','price','description'])
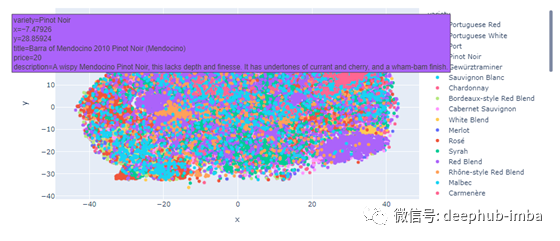
数据中有很多不同的类型散点图看起来就像宇宙背景辐射,但这没关系。将鼠标悬停在圆点上将显示更多信息。用户可以点击各种图标将其从图表中删除。
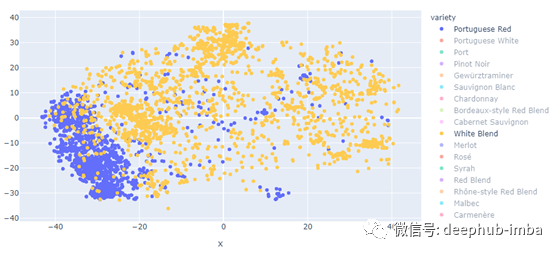
有趣的是,我们可以看到一些品种是如何聚集在一起的,而另一些则是如何分散在各处的。
创建界面
为了让用户能够与搜索功能进行互动,我们可以使用Plotly的Dash构建一个简单的用户界面。Dash是一个基于Flask, plot .js和React.js的Python框架。
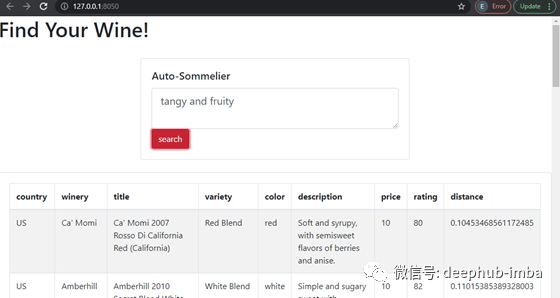
安装Dash、Dash Bootstrap组件和jupyter- Dash,如果你想在jupyter笔记本中构建一个Dash应用程序。
pip install dash
pip install dash-bootstrap-components
pip install jupyter-dash #if you want to build in a jupyter notebook
Dash应用程序由布局和回调组成:
布局:布局由描述应用程序外观和用户如何体验内容的组件树组成。
回调:回调功能使Dash应用具有交互性。回调函数是每当输入属性发生变化时自动调用的Python函数。
对于这部分内容我们就不详细介绍了,有兴趣的读者可以阅读原文
最后的想法和完整的代码
与我在2019年创建的最初的Auto-Sommelier相比,这个版本要快得多,也简单得多。通过像HuggingFace这样的框架来利用最先进的语言模型的强大力量,为像我这样的机器学习爱好者打开了一扇门,他们可以只用几行代码就构建出一些很棒的应用程序。现在是时候做一些分析了,看看与原始工具相比,结果是如何改进的!
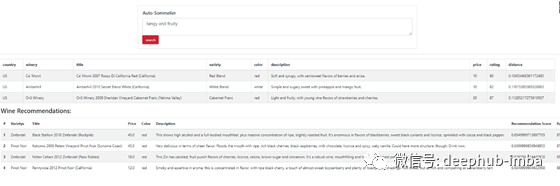
本文代码:https://github.com/bendgame/MediumWineRecommend2
作者:Eric Kleppen