

🎈🎈作者主页: 喔的嘛呀🎈🎈
🎈🎈所属专栏:python爬虫学习🎈🎈
✨✨谢谢大家捧场,祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天开心哦!✨✨
兄弟姐妹们,大家好!我是喔的嘛呀今天让我们一起学习如何下载浏览器驱动和Selenium的两个案列
一、下载浏览器驱动
使用 Selenium 需要下载相应的浏览器驱动,以便 Selenium 能够控制浏览器。不同的浏览器需要使用对应的驱动程序,例如 Chrome 需要 chromedriver,Firefox 需要 geckodriver。
以下是下载浏览器驱动的一般步骤:
我用的谷歌浏览器,我就以谷歌浏览器为例。
1、确定浏览器版本:首先确定你需要使用的浏览器版本,例如 Chrome 的版本是多少。
(1)点上面那三个点,再点设置

(2)点关于chrome就可以看见版本信息

2、下载对应版本的驱动程序:访问对应浏览器驱动的官方网站下载页面,下载对应浏览器版本的驱动程序。以下是谷歌浏览器的驱动下载页面:
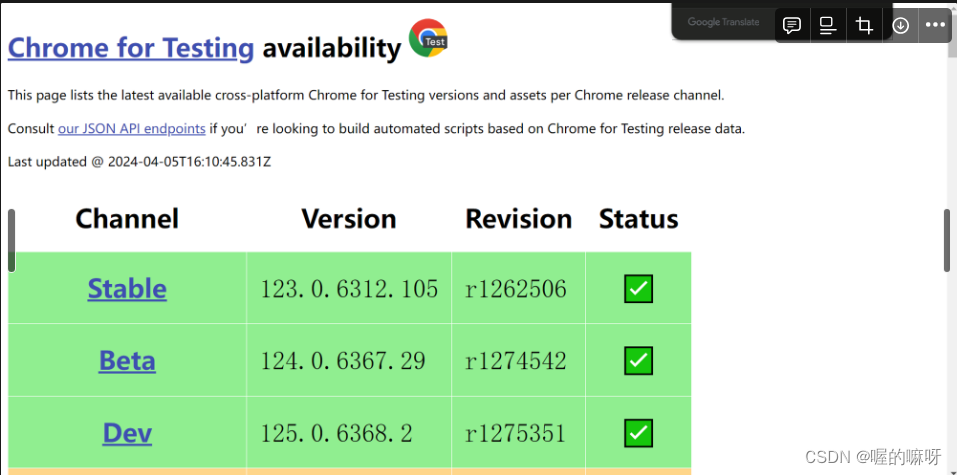
Chrome for Testing availability
我下的是这个

(3)将驱动程序添加到系统 PATH:下载完成后,将驱动程序所在目录添加到系统的 PATH 环境变量中,这样 Selenium 就能找到驱动程序。
所在目录不要有中文

然后把他加到环境变量中去,就OK了。
二、模拟登录
下面会展示如何使用 Selenium 打开 Gitte 网站,模拟用户登录
1、定位要输入账号和密码的网页结构

**
By.ID
** 是 Selenium 中用于根据 HTML 元素的 **
id
** 属性来定位元素的方法。在这个例子中,**
'user_login'
** 是要定位的元素的 id 属性的值,表示用户名输入框。**
'user_password'
就是密码输入框**通过这种方式,Selenium 可以精确地找到页面上具有特定 id 属性值的元素,从而实现对该元素的操作,比如输入文本、点击等。
2、我们需要找到value=‘登录’的input表单,需要用xpath表达式
- **
//input**:选择所有的<input>元素,不论它们在文档中的位置。 - **
[@value="登 录"]**:筛选出其中value属性值为"登 录"的元素。
综合起来,
'//input[@value="登 录"]'
这个 XPath 表达式选择了文档中 **
value
** 属性值为 **
"登 录"
** 的所有 **
<input>
** 元素。在这个特定的场景下,假设这个 XPath 表达式能够准确地定位到登录按钮元素,从而实现后续的点击操作。
3、根据上面的思路开始写代码
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException
# 配置 ChromeDriver 路径
driver_path = 'G:\\chromedriver-win64\\chromedriver.exe'(我自己的路径)
# 创建 Chrome WebDriver 实例
service = Service(driver_path)
options = Options()
driver = webdriver.Chrome(service=service, options=options)
# 打开 Gitte 网站
driver.get('<https://gitee.com/login?redirect_to_url=%2F>')
# 输入用户名和密码
username_input = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, 'user_login'))
)
password_input = driver.find_element(By.ID, 'user_password')
username_input.send_keys('YourUsername')
password_input.send_keys('YourPassword')
# 提交登录表单
login_button = driver.find_element(By.XPATH, '//input[@value="登 录"]')
login_button.click()
# 等待登录成功并跳转到个人信息页面
try:
WebDriverWait(driver, 30).until(EC.url_contains('<https://gitee.com/your_username>'))
except:
print("登录超时或失败")
# 关闭浏览器
driver.quit()
这段代码是可以成功模拟登陆的,就是点运行之后会自己跳出来窗口自动输入你的账号密码,并自动登录
因为涉及个人信息,我这里就不演示结果了大家可以自己试试。
三、爬取数据
利用Selenium自动化翻页爬取豆瓣电影Top250的数据(("排名", "电影名称", "导演", "上映时间", "评分", "评价人数", "链接"))并保存到Excel文件中:
# 导入需要的模块
from selenium import webdriver # 用于启动浏览器并访问网页
from selenium.webdriver.common.by import By # 用于定位元素
from selenium.webdriver.support.ui import WebDriverWait # 用于等待元素加载
from selenium.webdriver.support import expected_conditions as EC # 用于设置等待条件
import xlwt # 用于生成Excel文件
import time as tm # 用于等待页面加载
# 保存数据到Excel文件
def save_to_excel(save_path, data_lists):
"""
保存数据到Excel文件
:param save_path: 保存文件的路径
:param data_lists: 数据列表,包含要保存的数据
"""
# 创建一个新的Excel文件
workbook = xlwt.Workbook(encoding="utf-8")
# 创建一个工作表
worksheet = workbook.add_sheet("豆瓣电影Top250", cell_overwrite_ok=True)
# 定义表头
name_sheet = ("排名", "电影名称", "导演", "上映时间", "评分", "评价人数", "链接")
# 写入表头数据
for i in range(len(name_sheet)):
worksheet.write(0, i, name_sheet[i])
# 写入电影数据
for i in range(len(data_lists)):
item = data_lists[i]
for j in range(len(item)):
worksheet.write(i + 1, j, item[j])
# 保存Excel文件
workbook.save(save_path)
# 爬取豆瓣电影Top250数据
def crawl_douban_top250(url):
"""
爬取豆瓣电影Top250数据
:param url: 豆瓣电影Top250的网址
:return: 包含爬取数据的列表
"""
# 启动Chrome浏览器并打开网页
driver = webdriver.Chrome()
driver.get(url)
# 保存爬取的数据
datalists = []
try:
while True:
# 等待电影条目加载完成
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, 'item')))
# 获取电影条目列表
items = driver.find_elements(By.CLASS_NAME, 'item')
for item in items:
try:
# 提取电影信息
rank = item.find_element(By.XPATH, './/em[@class=""]').text
title = item.find_element(By.XPATH, './/div[@class="hd"]/a/span[1]').text
info = item.find_element(By.XPATH, './/div[@class="bd"]/p[1]').text.split('\\n')
director = info[0].split('导演: ')[-1]
time_info = info[1].split(' / ')[0] if len(info) > 1 else ''
rating = item.find_element(By.XPATH, './/span[@class="rating_num"]').text
comment_num = item.find_element(By.XPATH, './/div[@class="star"]/span[last()]').text[:-3]
link = item.find_element(By.XPATH, './/div[@class="hd"]/a').get_attribute('href')
# 将提取的信息添加到datalists列表中
datalists.append([rank, title, director, time_info, rating, comment_num, link])
except Exception as e:
# 输出提取失败的异常信息
print("Failed to extract element:", e)
# 查找下一页按钮
next_button = driver.find_element(By.CLASS_NAME, 'next')
# 如果下一页按钮不可点击,则表示数据已经全部爬取完毕,退出循环
if not next_button.is_enabled():
break
# 滚动到下一页按钮处并点击
driver.execute_script("arguments[0].scrollIntoView();", next_button)
next_button.click()
# 等待2秒,确保页面加载完成
tm.sleep(2)
except Exception as e:
# 输出异常信息
print("An error occurred:", e)
finally:
# 关闭浏览器
driver.quit()
return datalists
if __name__ == '__main__':
# 设置豆瓣电影Top250的URL
url = '<https://movie.douban.com/top250>'
# 调用爬取函数获取数据
data_lists = crawl_douban_top250(url)
# 保存数据到Excel文件
save_to_excel(r'douban9_top250.xls', data_lists) //路径可以随意
提取电影信息上面有一些被挡住了,我单独抽出来:
提取电影信息
rank = item.find_element(By.XPATH, './/em[@class=""]').text
title = item.find_element(By.XPATH, './/div[@class="hd"]/a/span[1]').text
info = item.find_element(By.XPATH, './/div[@class="bd"]/p[1]').text.split('\\n')
director = info[0].split('导演: ')[-1]
time_info = info[1].split(' / ')[0] if len(info) > 1 else ''
rating = item.find_element(By.XPATH, './/span[@class="rating_num"]').text
comment_num = item.find_element(By.XPATH, './/div[@class="star"]/span[last()]').text[:-3]
link = item.find_element(By.XPATH, './/div[@class="hd"]/a').get_attribute('href')
# 将提取的信息添加到datalists列表中
datalists.append([rank, title, director, time_info, rating, comment_num, link])
except Exception as e:
# 输出提取失败的异常信息
print("Failed to extract element:", e)
代码运行之后也会自己跳出来窗口,自己模仿人工进行翻页(应对反爬)总共有十页,到第十页的时候,等待一会手动关闭窗口。等带十秒钟左右,就会出现Excel文件。
结果展示:
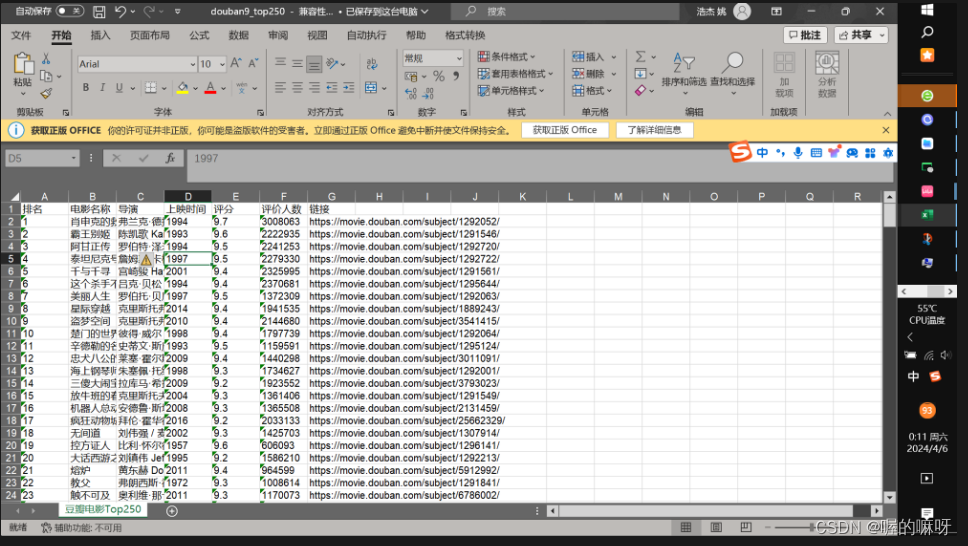
总共248丢了两条,嘿嘿。
这个 Selenium我觉得还是比较难的,费了我很长时间,才爬出来了。比较菜,还得练。还有爬了一个boss直聘没爬出来。过几天再试试。
好了,今天的学习就到这里了,拜拜喽!
版权归原作者 喔的嘛呀 所有, 如有侵权,请联系我们删除。