
我的许多文章都专注于 BERT——这个模型出现并主导了自然语言处理 (NLP) 的世界,标志着语言模型的新时代。

对于那些之前可能没有使用过 Transformer 模型(例如 BERT 是什么)的人,这个过程看起来有点像这样:
- pip 安装Transformer
- 初始化一个预训练的 Transformer 模型 — from_pretrained。
- 在一些数据上测试它。
- 也许微调模型(再训练一些)。
现在,这是一个很好的方法,但如果我们只这样做,我们就会缺乏对创建我们自己的 Transformer 模型的理解。
而且,如果我们不能创建自己的 Transformer 模型——我们必须依赖于一个适合我们问题的预训练模型,但情况并非总是如此:

因此,在本文中,我们将探讨构建我们自己的 Transformer 模型必须采取的步骤——特别是 BERT 的进一步开发版本,称为 RoBERTa。
概述
这个过程有几个步骤,所以在我们深入研究之前,让我们先总结一下我们需要做什么。总的来说,有四个关键部分:
- 获取数据
- 构建分词器
- 创建输入管道
- 训练模型
一旦我们完成了这些部分中的每一个,我们将使用我们构建的标记器和模型 - 并将它们保存起来,以便我们可以像通常使用 from_pretrained 一样的方式使用它们。
获取数据
与任何机器学习项目一样,我们需要数据。在用于训练 Transformer 模型的数据方面,我们几乎可以使用任何文本数据。
而且,如果我们在互联网上有很多东西——那就是非结构化文本数据。
从互联网上抓取的文本领域中最大的数据集之一是 OSCAR 数据集。
OSCAR 数据集拥有大量不同的语言——从头开始训练最清晰的用例之一是我们可以将 BERT 应用于一些不太常用的语言,例如泰卢固语或纳瓦霍语。
我的语言是英语——但我的女朋友是意大利人,所以她——劳拉,将评估我们讲意大利语的 BERT 模型——FiliBERTo 的结果。
因此,要下载 OSCAR 数据集的意大利语部分,我们将使用 HuggingFace 的数据集库——我们可以使用 pip install datasets 安装它。然后我们下载 OSCAR_IT :
from datasets import load_dataset
dataset = load_dataset('oscar', 'unshuffled_deduplicated_it')
我们来看看数据集对象。
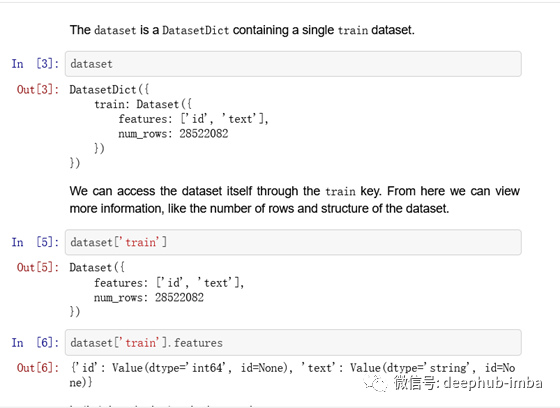
现在让我们以一种可以在构建分词器时使用的格式存储我们的数据。我们需要创建一组仅包含数据集中文本特征的纯文本文件,我们将使用换行符 \n 拆分每个样本。
from tqdm.auto import tqdm
text_data = []
file_count = 0
for sample in tqdm(dataset['train']):
sample = sample['text'].replace('\n', '')
text_data.append(sample)
if len(text_data) == 10_000:
# once we git the 10K mark, save to file
with open(f'../../data/text/oscar_it/text_{file_count}.txt', 'w', encoding='utf-8') as fp:
fp.write('\n'.join(text_data))
text_data = []
file_count += 1
# after saving in 10K chunks, we will have ~2082 leftover samples, we save those now too
with open(f'../../data/text/oscar_it/text_{file_count}.txt', 'w', encoding='utf-8') as fp:
fp.write('\n'.join(text_data))
在我们的 data/text/oscar_it 目录中,我们会发现:

构建分词器
接下来是标记器!在使用转换器时,我们通常会加载一个分词器,连同其各自的转换器模型——分词器是该过程中的关键组件。
在构建我们的分词器时,我们将为它提供我们所有的 OSCAR 数据,指定我们的词汇量大小(分词器中的标记数)和任何特殊标记。
现在,RoBERTa 特殊令牌如下所示:
okenUse
<s>
Beginning of sequence (BOS) or classifier (CLS) token
</s>
End of sequence (EOS) or seperator (SEP) token
<unk>
Unknown token
<pad>
Padding token
<mask>
Masking token
因此,我们确保将它们包含在标记器的 train 方法调用的 special_tokens 参数中。
from pathlib import Path
paths = [str(x) for x in Path('../../data/text/oscar_it').glob('**/*.txt')]
from tokenizers import ByteLevelBPETokenizer
tokenizer = ByteLevelBPETokenizer()
tokenizer.train(files=paths[:5], vocab_size=30_522, min_frequency=2,
special_tokens=['<s>', '<pad>', '</s>', '<unk>', '<mask>'])
我们的分词器现在已经准备好了,我们可以保存它的文件以备后用:
import os
os.mkdir('./filiberto')
tokenizer.save_model('filiberto')
现在我们有两个文件定义了我们的新 FiliBERTo 分词器:
merges.txt — 执行文本到标记的初始映射
vocab.json — 将令牌映射到令牌 ID
有了这些,我们可以继续初始化我们的分词器,以便我们可以像使用任何其他 from_pretrained 分词器一样使用它。
初始化分词器
我们首先使用我们之前构建的两个文件来初始化分词器——使用一个简单的 from_pretrained:
from transformers import RobertaTokenizer
# initialize the tokenizer using the tokenizer we initialized and saved to file
tokenizer = RobertaTokenizer.from_pretrained('filiberto', max_len=512)
现在我们的标记器已经准备好了,我们可以尝试用它编码一些文本。编码时,我们使用与通常使用的两种方法相同的方法,encode 和 encode_batch。
# test our tokenizer on a simple sentence
tokens = tokenizer('ciao, come va?')
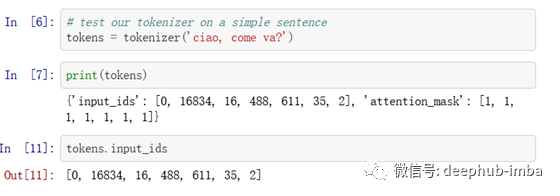
从编码对象标记中,我们将提取 input_ids 和 attention_mask 张量以与 FiliBERTo 一起使用。
创建输入管道
我们训练过程的输入管道是整个过程中比较复杂的部分。它包括我们获取原始 OSCAR 训练数据,对其进行转换,然后将其加载到准备进行训练的 DataLoader 中。
准备数据
我们将从一个示例开始,然后完成准备逻辑。
首先,我们需要打开我们的文件——我们之前保存为 .txt 文件的相同文件。我们根据换行符 \n 拆分每个,因为这表示单个样本。
with open('../../data/text/oscar_it/text_0.txt', 'r', encoding='utf-8') as fp:
lines = fp.read().split('\n')
然后我们使用 encode_batch 方法对我们的数据进行编码。
batch = tokenizer.encode_batch(lines)
len(batch)

现在我们可以继续创建我们的张量——我们将通过掩码语言建模 (MLM) 来训练我们的模型。所以,我们需要三个张量:
input_ids — 我们的 token_ids,其中约 15% 的令牌使用掩码令牌 <mask> 进行掩码。
attention_mask——一个 1 和 0 的张量,标记“真实”标记/填充标记的位置——用于注意力计算。
labels——我们的 token_ids 没有屏蔽。
如果你不熟悉MLM,我以前的文章已经解释了。
我们的 attention_mask 和标签张量只是从我们的批次中提取的。但是input_ids 张量需要更多操作,对于这个张量,我们屏蔽了大约 15% 的标记——为它们分配标记 ID 3。
import torch
labels = torch.tensor([x.ids for x in batch])
mask = torch.tensor([x.attention_mask for x in batch])
# make copy of labels tensor, this will be input_ids
input_ids = labels.detach().clone()
# create random array of floats with equal dims to input_ids
rand = torch.rand(input_ids.shape)
# mask random 15% where token is not 0 [PAD], 1 [CLS], or 2 [SEP]
mask_arr = (rand < .15) * (input_ids != 0) * (input_ids != 1) * (input_ids != 2)
# loop through each row in input_ids tensor (cannot do in parallel)
for i in range(input_ids.shape[0]):
# get indices of mask positions from mask array
selection = torch.flatten(mask_arr[i].nonzero()).tolist()
# mask input_ids
input_ids[i, selection] = 3 # our custom [MASK] token == 3
在最终输出中,我们可以看到编码的 input_ids 张量的一部分。第一个令牌 ID 是 1 — [CLS] 令牌。在张量周围,我们有几个 3 个令牌 ID——这些是我们新添加的 [MASK] 令牌。
构建dataloader
接下来,我们定义我们的 Dataset 类——我们用它来将我们的三个编码张量初始化为 PyTorch torch.utils.data.Dataset 对象。
encodings = {'input_ids': input_ids, 'attention_mask': mask, 'labels': labels}
class Dataset(torch.utils.data.Dataset):
def __init__(self, encodings):
# store encodings internally
self.encodings = encodings
def __len__(self):
# return the number of samples
return self.encodings['input_ids'].shape[0]
def __getitem__(self, i):
# return dictionary of input_ids, attention_mask, and labels for index i
return {key: tensor[i] for key, tensor in self.encodings.items()}
dataset = Dataset(encodings)
loader = torch.utils.data.DataLoader(dataset, batch_size=16, shuffle=True)
最后,我们的数据集被加载到 PyTorch DataLoader 对象中——我们使用它在训练期间将数据加载到我们的模型中。
训练模型
我们需要两件东西来训练,我们的 DataLoader 和一个模型。我们拥有的 DataLoader — 但没有模型。
初始化模型
对于训练,我们需要一个原始的(未预训练的)BERTLMHeadModel。要创建它,我们首先需要创建一个 RoBERTa 配置对象来描述我们想要用来初始化 FiliBERTo 的参数。
from transformers import RobertaConfig
config = RobertaConfig(
vocab_size=30_522, # we align this to the tokenizer vocab_size
max_position_embeddings=514,
hidden_size=768,
num_attention_heads=12,
num_hidden_layers=6,
type_vocab_size=1
)
然后,我们使用语言建模 (LM) 头导入并初始化我们的 RoBERTa 模型。
from transformers import RobertaForMaskedLM
model = RobertaForMaskedLM(config)
训练准备
在进入我们的训练循环之前,我们需要设置一些东西。首先,我们设置 GPU/CPU 使用率。然后我们激活我们模型的训练模式——最后,初始化我们的优化器。
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
# and move our model over to the selected device
model.to(device)
from transformers import AdamW
# activate training mode
model.train()
# initialize optimizer
optim = AdamW(model.parameters(), lr=1e-4)
训练
最后——训练时间!我们按照通常通过 PyTorch 进行培训时的方式进行训练。
epochs = 2
for epoch in range(epochs):
# setup loop with TQDM and dataloader
loop = tqdm(loader, leave=True)
for batch in loop:
# initialize calculated gradients (from prev step)
optim.zero_grad()
# pull all tensor batches required for training
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
# process
outputs = model(input_ids, attention_mask=attention_mask,
labels=labels)
# extract loss
loss = outputs.loss
# calculate loss for every parameter that needs grad update
loss.backward()
# update parameters
optim.step()
# print relevant info to progress bar
loop.set_description(f'Epoch {epoch}')
loop.set_postfix(loss=loss.item())

model.save_pretrained('./filiberto') # and don't forget to save filiBERTo!
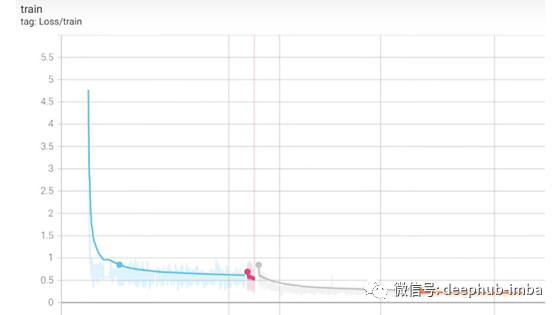
如果我们继续使用 Tensorboard,随着时间的推移,我们会发现我们的损失——它看起来很有希望。
最终测试
现在是进行真正测试的时候了。我们建立了一个MLM管道——并请劳拉评估结果。
我们首先使用“fill-mask”参数初始化一个管道对象。然后像这样开始测试我们的模型:
from transformers import pipeline
fill = pipeline('fill-mask', model='filiberto', tokenizer='filiberto')
fill(f'ciao {fill.tokenizer.mask_token} va?')

看样子还不错,接下来是复杂的短语

最后,再来一句更难的话,“cosa sarebbe successo se avessimo scelto un altro giorno?” ——或者“如果我们选择另一天会发生什么?”:

总的来说,看起来我们的模型通过了劳拉的测试——我们现在有一个名为 FiliBERTo 的意大利语模型!
这就是从头开始训练 BERT 模型的演练!
我们已经涵盖了很多方面,从获取和格式化我们的数据——一直到使用语言建模来训练我们的原始 BERT 模型。
作者:James Briggs
原文地址:https://towardsdatascience.com/how-to-train-a-bert-model-from-scratch-72cfce554fc6