
最近在做FLinkCDC数据实时同步的数据抽取处理
目标:
将源端系统Oracle数据库的实时数据通过FLINKCDC的形式抽取到Doris中
问题:
在抽取的过程中,如果表的数据量太大,抽取超过30张表以后,所有的任务大概运行25~30分钟以后,所有的任务的状态会从running 变为 Failed.
解决方案:
1.第一解决方案(没有解决掉)
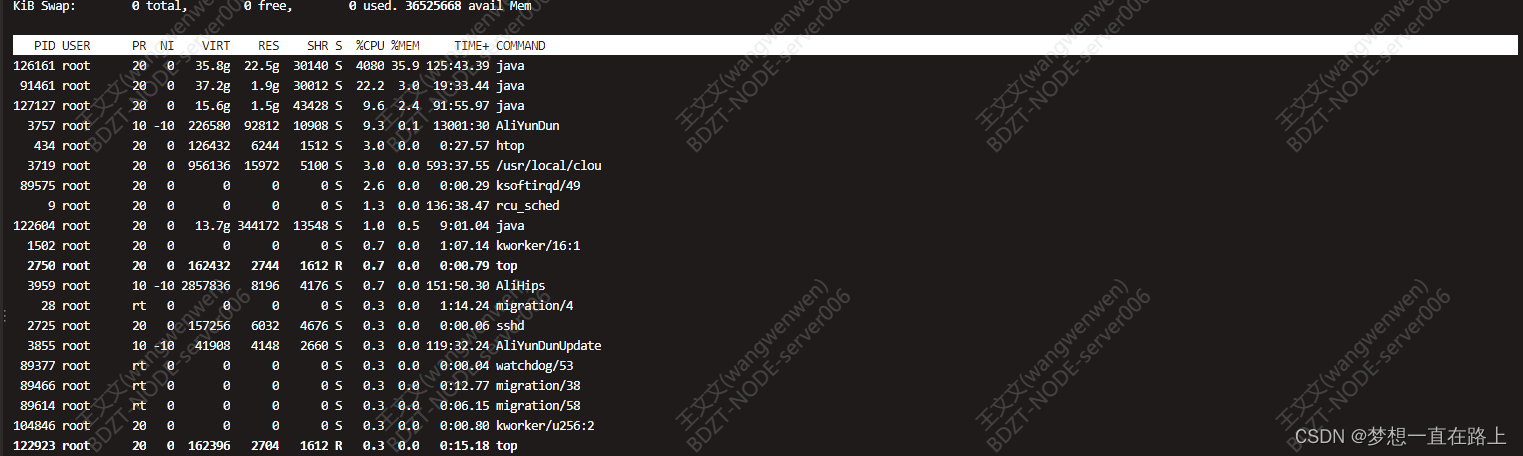
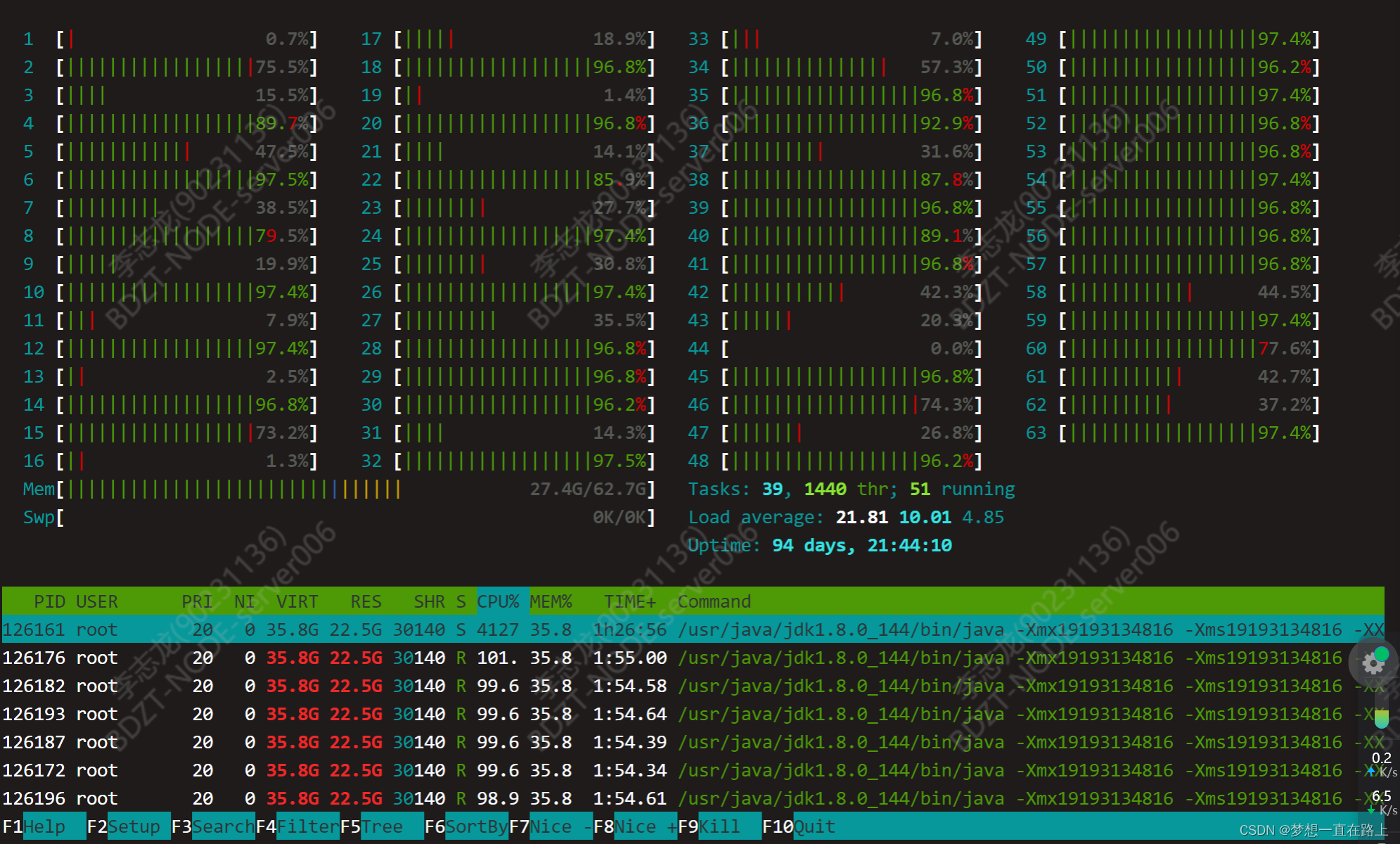
当时通过排查任务发现,我们的Flink部署搭建是通过采用Flink StandAlone HA的模式,有三台服务器,当提交任务到主节点以后,发现主节点上的任务运行大概30分钟的时候,服务器的cpu利用率大概是4250%,导致任务宕机.
所以我们采取的措施是: 将服务器升级,从原本的32核任务扩展到64核,但是升级以后,发现任务运行一段时间以后,还是变成Faild状态

第二种解决方案:(暂时解决掉,生效)
步骤:
1.第一次将全量数据在Dinky中通过JDBC的方式全量抽取过来
2.在启动全量抽取数据的同时,启动FlinkCDC的增量模式,进行增量数据的抽取
具体方案如下:
全量抽取:
create table xxx(
`ID` STRING , //建表语句 primary key (ID) not enforced)
with
(
'connector' = 'jdbc', 'url' = 'jdbc:oracle:thin:@ip:1521/orcl', 'driver' = 'oracle.jdbc.driver.OracleDriver', 'username' = 'xxx', 'password' = ''xxx, 'table-name' = '表名');
//Doris建表
create table xxx(
`id` string , //建表语句 primary key (id) not enforced)
WITH
(
'connector' = 'doris', 'fenodes' = '10.100.XXX:8030', 'table.identifier' = '表名', 'username' = 'root', 'password' = 'xxx, 'sink.properties.format' = 'json', 'sink.properties.read_json_by_line' = 'true', 'sink.label-prefix' = '5410923');
insert into xxx
select * from xxxx;
2.增量抽取
create table xxxx (
IDSTRING ,
xxxx
primary key (ID) not enforced
)
with
(
'connector' = 'oracle-cdc',
'hostname' = 'xxx',
'port' = '1521',
'username' = 'xxx',
'password' = 'Log#xxx',
'database-name' = 'ORCL',
'schema-name' = 'xxxx',
'table-name' = 'xxxx',
#增量模式
**'scan.startup.mode' = 'latest-offset', **
'debezium.log.mining.strategy' = 'online_catalog',
'scan.incremental.snapshot.chunk.key-column' = 'ID',
'debezium.errors.max.retries' = '3',
'debezium.log.mining.continuous.mine' = 'true',
'debezium.database.tablename.case.insensitive' = 'false'
);create table xxxx (
idstring ,primary key (`id`) not enforced)
WITH
(
#同全量语句
);
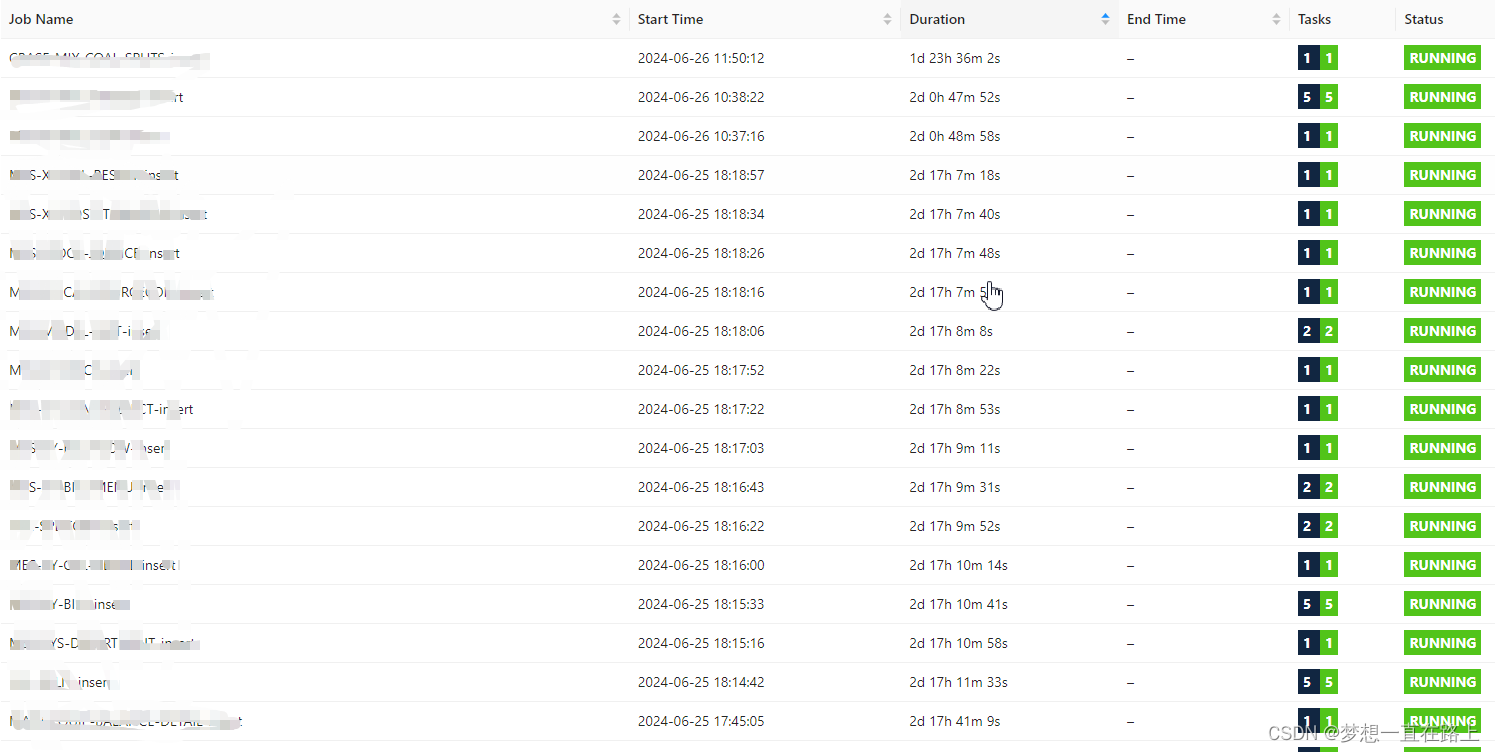
结果:
版权归原作者 梦想一直在路上 所有, 如有侵权,请联系我们删除。