
从0开始带你成为Kafka消息中间件高手—第四讲
假设leader收到第一条数据,此时leader LEO = 1,HW = 0,因为他发现其他follower的LEO也是0,所以HW必须是0
接着follower来发送fetch请求给leader同步数据,带过去follower的LEO = 0,所以leader上维护的follower LEO = 0,更新了一下,此时发现follower的LEO还是0,所以leader的HW继续是0
接着leader发送一条数据给follower,这里带上了leader的HW = 0,因为发现leader的HW = 0,此时follower LEO更新为1,但是follower HW = 0,取leader HW
接着下次follower再次发送fetch请求给leader的时候,就会带上自己的LEO = 1,leader更新自己维护的follower LEO = 1,此时发现follower跟自己的LEO同步了,那么leader的HW更新为1
接着leader发送给follower的数据里包含了HW = 1,此时follower发现leader HW = 1,自己的LEO = 1,此时follower的HW有更新为1
5个数据:全部都要往前推进更新,需要2次请求,第一次请求是仅仅是更新两边的LEO,第二次请求是更新leader管理的follower LEO,以及两个HW。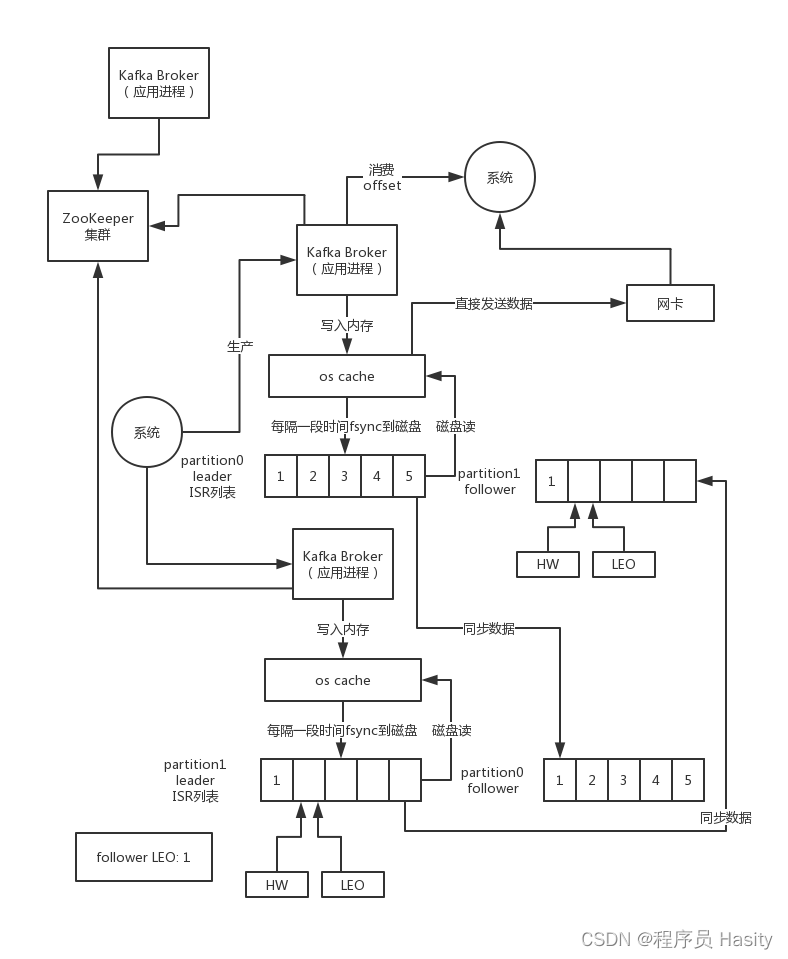
数据丢失
基于之前说的高水位机制,可能会导致一些问题,比如数据丢失
假设 生产者的min.insync.replicas(ISR副本为1)设置为1,这个就会导致说生产者发送消息给leader,leader写入log成功后,生产者就会认为写成功了,此时假设生产者发送了一条数据给leader,leader写成功了
此时leader的LEO = 1,HW = 0,因为follower还没同步,HW肯定是0
接着follower发送fetch请求,此时leader发现follower LEO = 0,所以HW还是0,给follower带回去的HW也是0,然后follower开始同步数据也写入了两条数据,自己的LEO = 1,但是HW = 0,因为leader HW为0
接着follower再次发送fetch请求过来,自己的LEO = 1,leader发现自己LEO = 1,follower LEO = 1,所以HW更新为1,同时会把HW = 1带回给follower,但是此时follower还没更新HW的时候,HW还是0
这个时候假如说follower机器宕机了,重启机器之后,follower的LEO会自动被调整为0,因为会依据HW来调整LEO,而且自己的那一条数据会被从日志文件里删除,数据就没了
这个时候如果leader宕机,就会选举follower为leader,此时HW = 0,接着leader那台机器被重启后作为follower,这个follower会从leader同步HW是0,此时会截断自己的日志,删除一条数据
这种场景就会导致数据的丢失
非常极端的一个场景,数据可能会莫名其妙的丢失
数据出错
假设min.insync.replicas = 1,那么只要leader写入成功,生产者而就会认为写入成功
如果leader写入了一条数据,但是follower才同步了一条数据,第二条数据还没同步,假设这个时候leader HW = 1,follower HW = 0,因为follower LEO小于leader HW,所以follower HW取自己的LEO
这个时候如果leader挂掉,切换follower变成leader,此时HW = 0,就一条数据,然后生产者又发了一条数据给新leader,此时HW变为1,但是第二条数据是新的数据。接着老leader重启变为follower,这个时候发现两者的HW都是1
所以他们俩就会继续运行了
这个时候他们俩数据是不一致的,本来合理的应该是新的follower要删掉自己原来的第二条数据,跟新leader同步的,让他们俩的数据一致,但是因为依赖HW发现一样,所以就不会截断数据了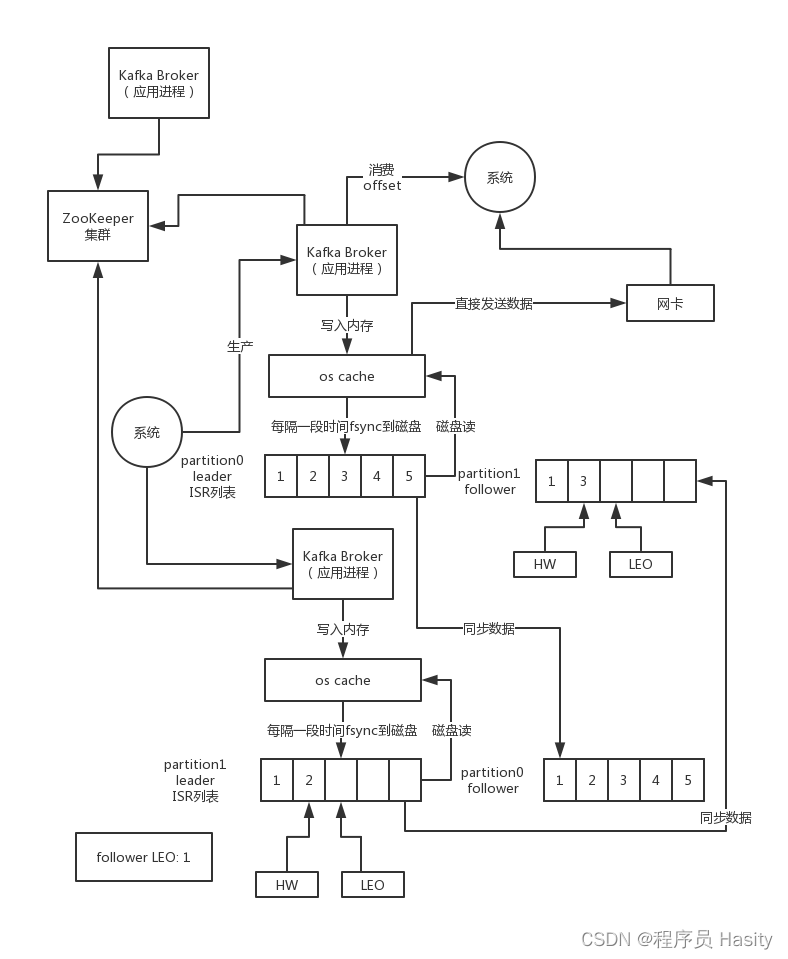
leader epoch 解决问题
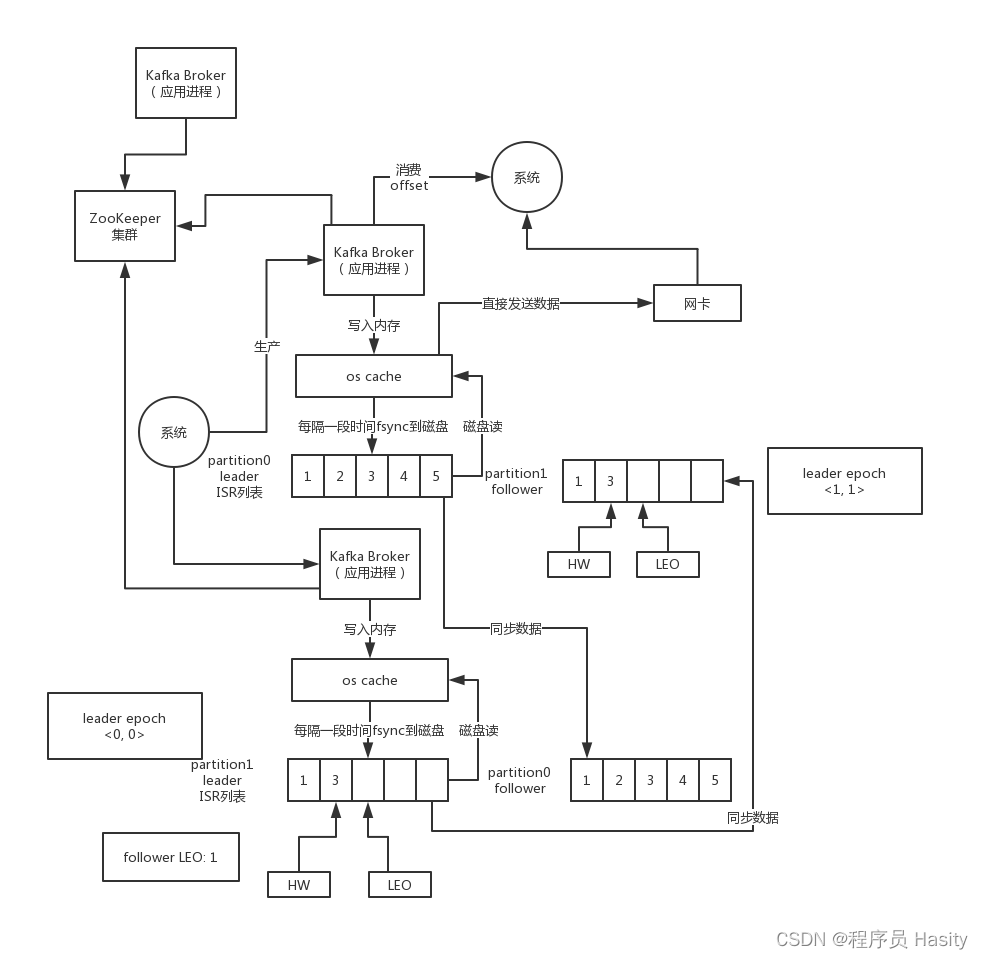
所谓的leader epoch大致理解为每个leader的版本号,以及自己是从哪个offset开始写数据的,类似[epoch = 0, offset = 0],这个就是epoch是版本号的意思,接着的话,按照之前的那个故障场景
假如说follower先宕机再重启,他会找leader继续同步最新的数据,更新自己的LEO和HW,不会截断数据,因为他会看看自己这里有没有[epoch, offset]对,如果有的话,除非是自己的offset大于了leader的offset,才会截断自己的数据
而且人家leader的最新offset = 1,自己的offset = 0,明显自己落后于人家,有什么资格去截断数据呢?对不对,就是这个道理。而且还会去从leader同步最新的数据过来,此时自己跟Leader数据一致。
如果此时leader宕机,切换到follower上,此时就会更新自己的[epoch = 1, offset = 2],意思是自己的leader版本号是epoch = 1,自己从offset = 2开始写数据的
然后接着老leader恢复变为follower,从新leader看一下epoch跟自己对比,人家offset = 2,自己的offset = 0,也不需要做任何数据截断,直接同步人家数据就可以了
然后针对数据不一致的场景,如果说老leader恢复之后作为follower,从新leader看到[epoch = 1, offset = 1],此时会发现自己的offset也是1,但是人家新leader是从offset = 1开始写的,自己的offset = 1怎么已经有数据了呢?
此时就会截断掉自己一条数据,然后跟人家同步保持数据一致
ISR机制
很多公司比较常用的一个kafka的版本,是0.8.2.x系列,这个系列的版本是非常经典的,在过去几年相当大比例的公司都是用这个版本的kafka。当然,现在很多公司开始用更新版本的kafka了,就是0.9.x或者是1.x系列的
我们先说说在0.9.x之前的版本里,这个kafka到底是如何维护ISR列表的,什么样的follower才有资格放到ISR列表里呢?
在之前的版本里,有一个核心的参数:replica.lag.max.messages。这个参数就规定了follower如果落后leader的消息数量超过了这个参数指定的数量之后,就会认为follower是out-of-sync,就会从ISR列表里移除了
咱们来举个例子好了,假设一个partition有3个副本,其中一个leader,两个follower,然后replica.lag.max.messages = 3,刚开始的时候leader和follower都有3条数据,此时HW和LEO都是offset = 2的位置,大家都同步上来了
现在来了一条数据,leader和其中一个follower都写入了,但是另外一个follower因为自身所在机器性能突然降低,导致没及时去同步数据,follower所在机器的网络负载、内存负载、磁盘负载过高,导致整体性能下降了,此时leader partition的HW还是offset = 2的位置,没动,但是LEO变成了offset = 3的位置
依托LEO来更新ISR的话,在每个follower不断的发送Fetch请求过来的时候,就会判断leader和follower的LEO相差了多少,如果差的数量超过了replica.lag.max.messages参数设置的一个阈值之后,就会把follower给踢出ISR列表
但是这个时候第二个follower的LEO就落后了leader才1个offset,还没到replica.lag.max.messages = 3,所以第二个follower实际上还在ISR列表里,只不过刚才那条消息没有算“提交的”,在HW外面,所以消费者是读不到的
而且这个时候,生产者写数据的时候,如果默认值是要求必须同步所有follower才算写成功的,可能这个时候会导致生产者一直卡在那儿,认为自己还没写成功,这个是有可能的
一共有3个副本,1个leaderr,2个是follower,此时其中一个follower落后,被ISR踢掉了,ISR里还有2个副本,此时一个leader和另外一个follower都同步成功了,此时就可以让那些卡住的生产者就可以返回,认为写数据就成功了
min.sync.replicas = 2,ack = -1,生产者要求你必须要有2个副本在isr里,才可以写,此外,必须isr里的副本全部都接受到数据,才可以算写入成功了,一旦说你的isr副本里面少于2了,其实还是可能会导致你生产数据被卡住的
假设这个时候,第二个follower fullgc持续了几百毫秒然后结束了,接着从leader同步了那条数据,此时大家LEO都一样,而且leader发现所有follower都同步了这条数据,leader就会把HW推进一位,HW变成offset = 3
这个时候,消费者就可以读到这条在HW范围内的数据了,而且生产者认为写成功了
但是要是此时follower fullgc一直持续了好几秒钟,此时其他的生产者一直在发送数据过来,leader和第一个follower的LEO又推进了2位,LEO offset = 5,但是HW还是停留在offset = 2,这个时候HW后面的数据都是消费不了的,而且HW后面的那几条数据的生产者可能都会认为写未成功
现在导致第二个follower的LEO跟leader的LEO差距超过3了,此时触发阈值,follower认为是out-of-sync,就会从ISR列表里移除了
上面就是ISR的工作原理和机制,一般导致follower跟不上的情况主要就是以下三种:
(1)follower所在机器的性能变差,比如说网络负载过高,IO负载过高,CPU负载过高,机器负载过高,都可能导致机器性能变差,同步 过慢,这个时候就可能导致某个follower的LEO一直跟不上leader,就从ISR列表里移除了
我们生产环境遇到的一些问题,kafka,机器层面,某台机器磁盘坏了,物理机的磁盘有故障,写入性能特别差,此时就会导致follower,CPU负载太高了,线程间的切换太频繁了,CPU忙不过来了,网卡被其他的程序给打满了,就导致网络传输的速度特别慢
(2)follower所在的broker进程卡顿,常见的就是fullgc问题
kafka自己本身对jvm的使用是很有限的,生产集群部署的时候,他主要是接收到数据直接写本地磁盘,写入os cache,他一般不怎么在自己的内存里维护过多的数据,主要是依托os cache(缓存)来提高读和写的性能的
(3)kafka是支持动态调节副本数量的,如果动态增加了partition的副本,就会增加新的follower,此时新的follower会拼命从leader上同步数据,但是这个是需要过程的,所以此时需要等待一段时间才能跟leader同步
replica.lag.max.messages(默认4000)主要是解决第一种情况的,还有一个replica.lag.time.max.ms是解决第二种情况的,比如设置为500ms,那么如果在500ms内,follower没法送请求找leader来同步数据,说明他可能在fullgc,此时就会从ISR里移除
kafka 0.9.x之后去掉了原来的replica.lag.max.messages参数,引入了一个新的replica.lag.time.max.ms参数,默认值是10秒,这个就不按照落后的条数来判断了,而是说如果某个follower的LEO一直落后leader超过了10秒,那么才判定这个follower是out-of-sync的
这样假如说线上出现了流量洪峰,一下子导致几个follower都落后了不少数据,但是只要尽快追上来,在10秒内别一直落后,就不会认为是out-of-sync,这个机制在线上实践会发现效果要好多了
之前说的那套ISR机制是kafka 0.8.x系列的机制,其实是有缺陷的,那个参数默认的值是4000,也就是follower落后4000条数据就认为是out-of-sync,但是这里有一个问题,就是这个数字是固定死的
如果说现在生产端突然之间涌入几万条数据呢?是不是有可能leader瞬间刚接收到几万条消息,然后所有follower还没来得及同步过去,此时所有follower都会被踢出ISR列表?然后同步了之后,再回到ISR列表
所以这种依靠固定参数判断的机制,会导致可能在系统高峰时期,follower会频繁的踢出ISR列表再回到ISR列表,这种完全无意义的事情
一般来说在kafka 0.8.2.x系列版本上生产的时候,一遍都会把这个ISR落后 判定阈值设置的大一些,避免上述的情况出现,你可以设置个几万,10万,4000,如果你公司里没那么大的高峰并发量,每秒就是几千的并发,那就没问题了
版权归原作者 程序员 Hasity 所有, 如有侵权,请联系我们删除。