
‘Descending through a Crowded Valley — Benchmarking Deep Learning Optimizers’
Schmidt*, Schneider,* Henning (2021)
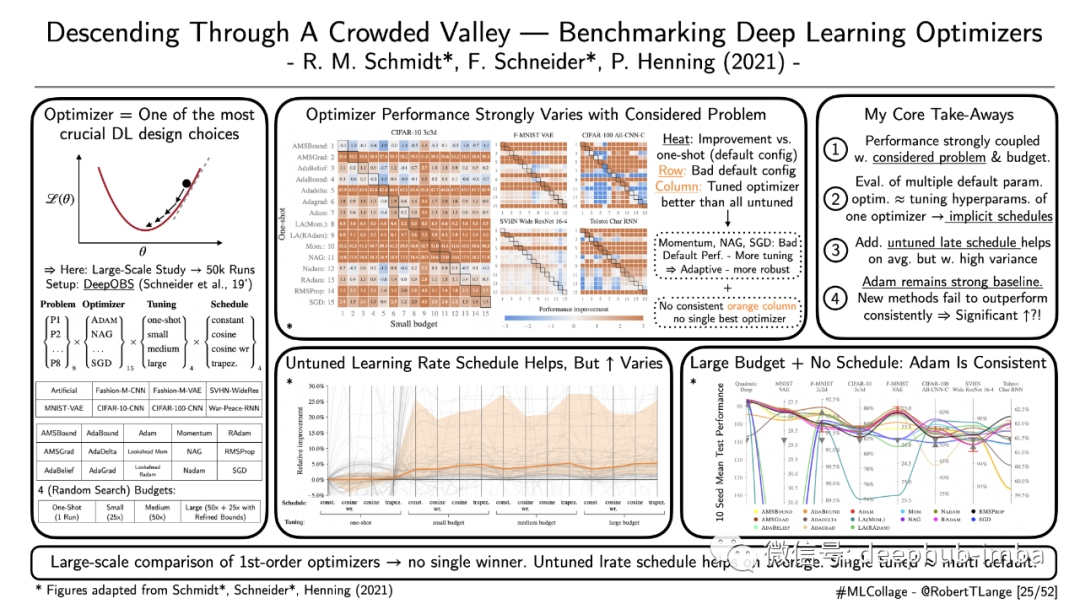
调整优化器是每个基于深度学习的项目的基本要素。存在许多启发式方法,例如臭名昭著的学习率起点 3e-04(又名 Karpathy 常数)。但是,我们能否提供对跨任务空间优化器性能的一般建议?在最近的ICML论文中,Schmidt等人(2021年)通过运行一个超过50,000次的大规模基准测试来研究这个问题。他们比较了15种不同的一阶优化器,用于不同的调优预估、训练问题和学习速率计划。虽然他们的结果没有确定一个明确的赢家,但他们仍然提供了一些见解:
- 不同优化器的性能很大程度上取决于所考虑的问题和调整方式。
- 评估多个优化器的默认超参数与调整单个优化器的超参数大致相同。这可能是由于自适应方法(例如 Adam)的隐式学习率计划。
- 添加未调整的学习率计划可以提高性能,但相关的差异很大。
- Adam仍然是一个强大的基线。较新的方法未能在所有的测试中胜过它。
该基准测试不包括任何深度强化学习或 GAN 风格的训练任务。
‘Understanding the Role of Individual Units in a Deep Neural Network’
Bau et al.(2020)
了解单个激活在卷积神经网络 (CNN) 中的功能作用具有挑战性。Bau等人 (2020) 阐明了与语义概念相关的单元(即过滤器激活)的出现。他们引入了“network dissection”——一种系统识别此类语义的框架。通过将卷积滤波器产生的上采样激活与语义分割模型的预测进行比较,他们定义了一个概念一致性的分数。该技术应用于 VGG-16 场景分类器和在厨房图像数据集上训练的 Progressive GAN。对于基于 CNN 的分类器,他们观察到与对象和部件相关的单元出现在较晚的层中,而较早的层主要与颜色相关联。作者表明,此类神经元对于网络的分类准确性非常重要,并且它们的消融会损害性能。另一方面,对于生成器网络,在较早的层中可以更频繁地找到对象/部分神经元,而较晚的层则专注于颜色。这突出了通过训练来区分和必须生成场景的网络的信息流的差异。最后,GAN 生成的输出可以通过人为修剪概念单元来进行因果操作。这开辟了许多围绕针对特定神经元的有趣应用,例如对抗性示例和图像的结构化印记。

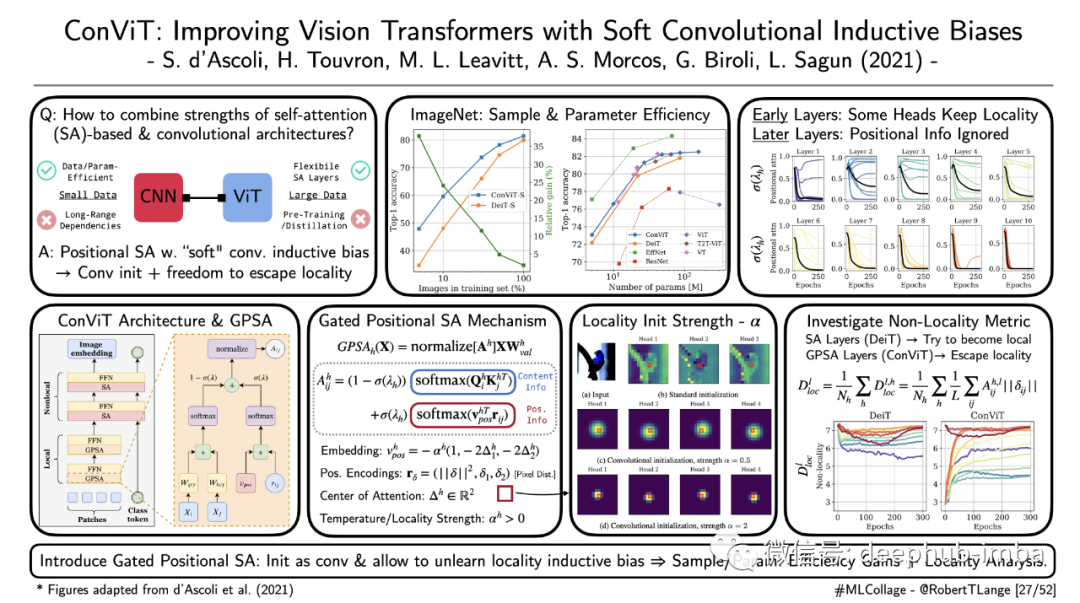
‘ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases’
d’ascoli et al.(2021)
卷积提供了强大的归纳偏置。隐含的权重共享和位置概念提供了等值转换,使人联想到初级视觉皮层中观察到的激活模式。尽管cnn在小数据领域表现出色,但在捕捉空间远程依赖性方面却遇到了困难。Vision transformer及其自我关注机制灵活且擅长于大量数据的处理。但它们需要许多参数、数据和某种形式的预训练或蒸馏。d’ascoli等人(2021)试图通过引入门控位置自我注意(GPSA)来兼顾这两个领域。GPSA 为位置 SA 配备了软卷积归纳偏置,并具有额外的自由度来逃避局部性。它充当普通软注意力层的替代品,可以初始化以模拟卷积。训练过程有一个可以调整的门控参数,该参数调节对位置和内容信息的关注。作者表明,与标准 Vision Transformer 架构相比,这种做大可以让 ImageNet 在样本和参数效率方面的强大改进。此外,他们分析了不同 GPSA 层及其头部学习到的局部性程度。有趣的是,他们发现早期的层保持了更多的局部偏置初始化,而后面的层则更多地关注内容信息。
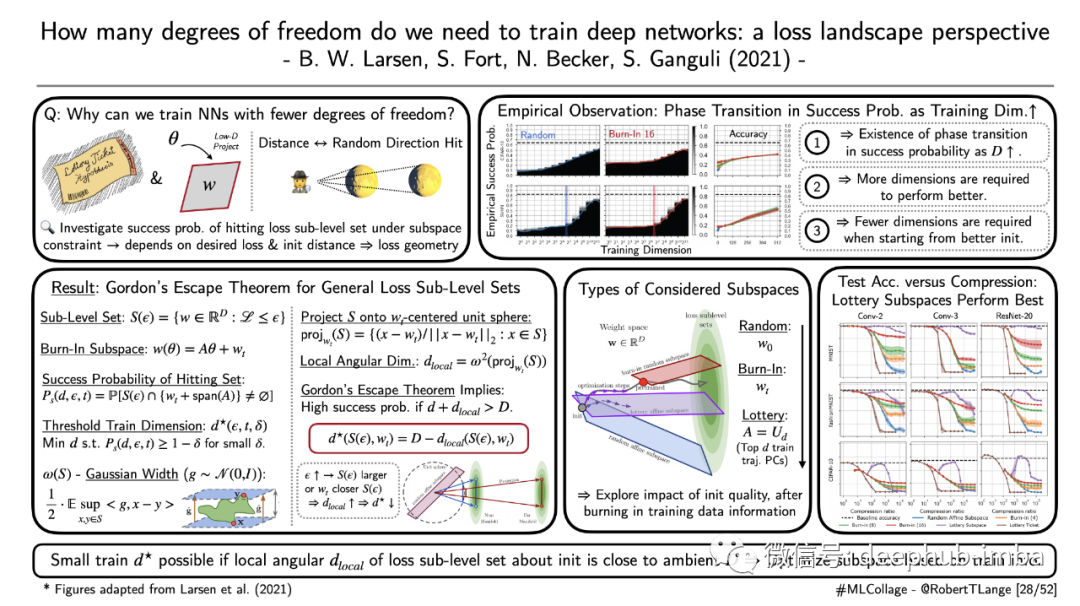
‘How many degrees of freedom do we need to train deep networks: a loss landscape perspective’
Larsen et al. (2021)
彩票假设(lottery ticket hypothesis)假定存在稀疏可训练神经网络。它质疑过度参数化在优化网络中的作用。但为什么会这样呢?理论基础是什么,什么决定了稀疏程度?Larsen等人 (2021) 基于达到期望损失子水平集的成功概率推导了一个理论。直观地说,这个概率随着网络获得的自由度的增加而增加。但还有更关键的因素,它们决定了所需的维数:参数子空间与子级别集的距离及其几何形状。作者证明了一个强大的定理,它将戈登逃逸定理(Gordon’s Escape Theorem )推广到一般集合。在主要结果中强调了相变在成功概率的存在。如果从更好的初始化开始时,需要更少的维度。直观地说,观察随机方向(子空间)和看到月球(损失子级别集)的概率取决于您与月球的距离。作者针对各种架构/问题设置验证了这些理论见解,并提出了所谓的“lottery subspaces”:通过利用以前的训练运行的信息,他们基于轨迹的顶点主成分构建了参数的低维投影。他们表明,这些受子空间约束的神经网络甚至可以在可比的压缩比上胜过彩票的概率。
作者:Robert Lange