
本文还有配套的精品资源,点击获取 
简介:RabbitMQ是一个广泛使用的开源消息队列系统,它通过AMQP协议提供了高度可用、可扩展和可靠的通信机制。本文将引导读者通过实例学习RabbitMQ的基本操作,包括安装配置、连接服务器、创建队列、发送和接收消息。通过实际编码演示了如何在Java项目中使用
rabbitmq-client
库与RabbitMQ交互,并介绍了如何进行异常处理、消息确认和持久化配置,以及如何利用RabbitMQ的集群特性提升系统的可用性和容错性。 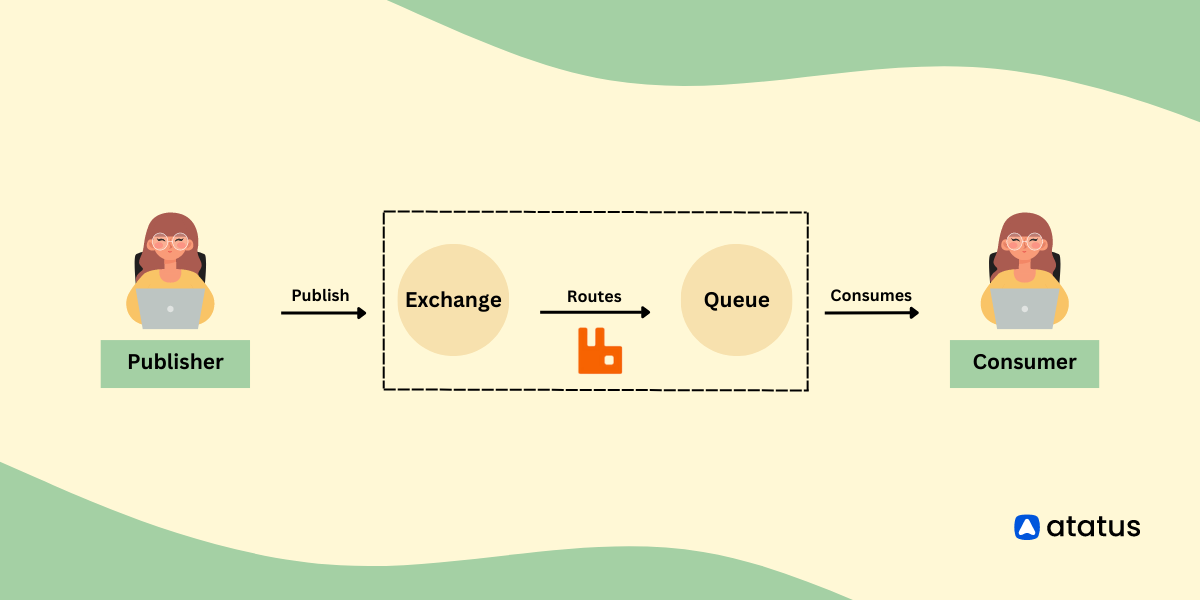
1. RabbitMQ简介与安装配置
1.1 RabbitMQ的起源与功能
RabbitMQ 是一个开源的 AMQP(Advanced Message Queuing Protocol)实现,它最初由 LShift 提供,后来由 Pivotal 收购。RabbitMQ 服务器用 Erlang 编程语言编写,并提供了多种功能,包括但不限于消息队列、负载均衡、消息确认、消息持久化等。这些特性使得 RabbitMQ 成为构建微服务架构、分布式系统和消息中间件应用的理想选择。
1.2 RabbitMQ的架构概述
RabbitMQ 的核心是一个消息代理(Broker),它负责接收、存储和转发消息。它支持多种消息模式,如点对点(P2P)和发布/订阅(Pub/Sub)。通过虚拟主机(Virtual Hosts),RabbitMQ 可以在一个实例中隔离不同用户或应用的数据。客户端通过 AMQP 协议与 RabbitMQ 交互,可以是消息的生产者(Publisher)或消费者(Consumer)。
1.3 安装与配置RabbitMQ
安装 RabbitMQ 首先需要安装 Erlang 环境,因为 RabbitMQ 是用 Erlang 编写的。安装 Erlang 后,可以通过包管理器或源代码编译的方式安装 RabbitMQ。以下是使用 Docker 快速安装 RabbitMQ 的命令:
docker run -d --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:3-management
这条命令会启动一个带有管理界面的 RabbitMQ 容器实例。其中,5672 端口是 AMQP 协议默认端口,15672 端口是管理界面端口。安装完成后,可以通过管理界面访问
***
并使用默认的用户名和密码(guest/guest)登录。
在生产环境中,你可能需要对 RabbitMQ 进行更多的配置,包括用户权限设置、队列和交换器的配置等,以满足业务需求和保证系统的安全性和稳定性。
2. Maven项目中使用RabbitMQ依赖
在企业级应用开发中,Maven已成为项目管理的业界标准。它不仅方便了依赖的管理和构建过程的自动化,而且还为项目构建提供了稳定性和可重复性。本章节将深入探讨如何在基于Maven的Java项目中集成RabbitMQ客户端依赖,并构建RabbitMQ服务调用层。
2.1 基于Maven管理项目依赖
Maven通过
pom.xml
文件管理项目依赖。在使用RabbitMQ之前,必须确保项目中已经正确配置了RabbitMQ的客户端依赖。
2.1.1 添加RabbitMQ客户端依赖
在
pom.xml
文件中添加RabbitMQ客户端依赖是第一步。这可以通过添加一个
dependency
元素到
dependencies
列表中完成。
<dependencies>
<!-- 其他依赖项 -->
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.8.0</version>
</dependency>
</dependencies>
上面的代码将RabbitMQ的客户端库添加到项目中。确保使用最新版本的客户端库可以带来最新的特性和安全补丁。
2.1.2 配置Maven项目以连接RabbitMQ
添加了依赖之后,Maven项目还需要进行一些配置才能成功连接到RabbitMQ服务器。这通常包括配置服务器地址、端口和认证信息。
<properties>
<rabbitmq.host>localhost</rabbitmq.host>
<rabbitmq.port>5672</rabbitmq.port>
<rabbitmq.username>guest</rabbitmq.username>
<rabbitmq.password>guest</rabbitmq.password>
</properties>
通过配置这些属性,项目中的代码就可以引用这些属性值进行连接了。
2.2 构建RabbitMQ服务调用层
调用层通常包含一组接口和实现类,用于定义与RabbitMQ服务器交互的抽象层。这有助于解耦业务逻辑和消息处理逻辑。
2.2.1 创建RabbitMQ服务接口
首先定义一组接口,这样不同的实现类可以提供不同的消息处理策略。
public interface RabbitMQService {
void sendMessage(String message);
String receiveMessage();
}
2.2.2 实现RabbitMQ服务接口
然后创建具体的实现类来完成接口定义的方法。通过注入
ConnectionFactory
和
Channel
等对象,可以实现消息的发送和接收。
public class SimpleRabbitMQService implements RabbitMQService {
private ConnectionFactory factory;
@Override
public void sendMessage(String message) {
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
// 发送消息逻辑...
} catch (IOException |TimeoutException e) {
e.printStackTrace();
}
}
@Override
public String receiveMessage() {
// 接收消息逻辑...
return "";
}
}
通过上述步骤,我们构建了一个基本的Maven项目,该项目包含了RabbitMQ的依赖和基本的调用层。这为后续构建复杂的业务逻辑提供了良好的基础。接下来,我们将连接到RabbitMQ服务器,并进行消息的发送和接收操作。
3. 连接RabbitMQ服务器与创建通道
在使用RabbitMQ进行消息交换之前,我们首先需要建立与服务器的连接,并在此基础上创建通道。本章节将介绍如何配置连接参数,处理连接异常,并详细解析通道的创建和生命周期管理。
3.1 连接到RabbitMQ服务器
连接到RabbitMQ服务器是与消息队列交互的第一步。一个典型的连接过程包括配置连接参数和处理可能出现的异常。
3.1.1 配置连接参数
在使用RabbitMQ客户端库连接服务器时,我们需要提供相应的连接参数,如主机地址、端口、用户名和密码等。
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class RabbitMQConnection {
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
// 配置连接参数
factory.setHost("localhost"); // RabbitMQ服务器地址
factory.setPort(5672); // 端口,默认为5672
factory.setUsername("guest"); // 用户名,默认为guest
factory.setPassword("guest"); // 密码,默认为guest
// 创建连接
try (Connection connection = factory.newConnection()) {
System.out.println("Connected to RabbitMQ");
// 此处可以进行后续操作,例如创建通道等
}
}
}
在代码中,
ConnectionFactory
是创建连接的关键类。通过它,我们可以设置不同的连接参数。创建连接时,需要确保服务器正在运行,并且提供的参数是正确的。
3.1.2 处理连接异常
在实际的生产环境中,连接可能会因为各种原因失败,例如网络问题、服务器宕机等。因此,正确的异常处理机制是必不可少的。
try (Connection connection = factory.newConnection()) {
System.out.println("Connected to RabbitMQ");
// 连接成功后的操作
} catch (IOException e) {
System.err.println("Cannot connect to the server: " + e.getMessage());
// 可以在这里记录日志,或者重试连接等
} catch (TimeoutException e) {
System.err.println("Connection timeout: " + e.getMessage());
// 处理超时异常
} catch (Exception e) {
System.err.println("Unexpected exception during connection: " + e.getMessage());
// 其他异常处理
}
在上述代码中,我们使用了try-with-resources语句来自动关闭连接。同时通过catch块捕获不同类型的异常,并进行相应的处理。
3.2 创建与管理通道
通道(Channel)是RabbitMQ连接中的一个轻量级连接。所有的消息传递操作都是通过通道进行的。创建和管理通道是连接服务器后的下一步。
3.2.1 通道的创建流程
通道的创建通常在成功建立连接后进行。通过使用
Connection
对象,我们可以创建一个新的
Channel
实例。
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
System.out.println("Channel created");
// 通道创建成功后,可以进行消息的发送和接收等操作
} catch (IOException | TimeoutException e) {
System.err.println("Failed to create a channel: " + e.getMessage());
// 通道创建失败的处理逻辑
}
通道的创建过程简单明了,但重要的是了解通道与连接之间的关系。一个连接可以创建多个通道,而通道之间的隔离保证了消息交换的安全性和可靠性。
3.2.2 通道的生命周期管理
通道在使用完毕后需要被正确关闭。通常,通道的生命周期管理应当遵循异常安全的实践。
Channel channel = null;
try {
channel = connection.createChannel();
// 使用通道进行各种操作
} catch (Exception e) {
System.err.println("Error when creating channel: " + e.getMessage());
} finally {
if (channel != null && channel.isOpen()) {
try {
channel.close(); // 关闭通道
} catch (IOException | TimeoutException e) {
System.err.println("Failed to close channel: " + e.getMessage());
}
}
}
在上述代码中,我们确保了通道在发生异常时仍然能够被正确关闭,避免资源泄露。关闭通道的操作通常放在
finally
块中执行,确保无论是否发生异常,通道都能被安全关闭。
通过本章节的介绍,我们了解了连接RabbitMQ服务器和创建通道的重要性及其实现方式。正确配置连接参数和合理管理通道生命周期是保证RabbitMQ高效率和稳定性运行的基础。在下一章节中,我们将探讨如何进行消息的发送和接收操作,进一步深入RabbitMQ的使用。
4. 消息的发送和接收操作
4.1 发送消息到队列
在使用消息队列进行系统间通信时,消息的发送是一个关键步骤。这一过程涉及到消息的基本属性设置、消息体的构造以及确保消息成功发送到队列的机制。RabbitMQ 作为消息代理,能够有效地管理这些操作,确保消息传递的可靠性。
4.1.1 消息的基本属性设置
消息由两部分组成:消息头(header)和消息体(payload)。在RabbitMQ中,消息头包含了一系列的属性,比如消息类型(type)、优先级(priority)、消息过期时间(expiration)等。RabbitMQ允许用户自定义消息属性,但有一些属性是RabbitMQ自己使用的,比如
message_id
、
correlation_id
等。
在设置消息属性时,可以使用RabbitMQ的客户端库提供的API进行设置。例如,在Java中,可以使用
AMQP.BasicProperties
类来设置消息属性:
import com.rabbitmq.client.*;
public class Producer {
private final static String QUEUE_NAME = "hello";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
AMQP.BasicProperties props = new AMQP.BasicProperties.Builder()
.contentType("text/plain")
.deliveryMode(2) // persistent delivery mode
.priority(1)
.build();
String message = "Hello World!";
channel.basicPublish("", QUEUE_NAME, props, message.getBytes("UTF-8"));
System.out.println(" [x] Sent '" + message + "'");
}
}
}
在上面的代码中,我们创建了一个消息属性对象
props
,设置了一些基本属性,然后在调用
basicPublish
方法时,将这个对象作为参数传入。
4.1.2 发送确认机制
为了确保消息的可靠发送,RabbitMQ提供了发布确认(publisher confirm)机制。这允许生产者确认消息是否已经被代理接收并且成功路由到匹配的队列。
发布确认机制使用起来相对简单。首先需要在连接对象上开启确认模式,然后监听
ConfirmCallback
回调函数,以接收确认信号:
import com.rabbitmq.client.*;
public class ConfirmedProducer {
private final static String QUEUE_NAME = "hello";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
channel.confirmSelect();
channel.addConfirmListener((sequenceNumber, multiple) -> {
// 处理确认消息
});
String message = "Hello World!";
channel.basicPublish("", QUEUE_NAME, null, message.getBytes("UTF-8"));
System.out.println(" [x] Sent '" + message + "'");
}
}
}
在这个例子中,通过调用
channel.confirmSelect()
方法启用发布确认模式。生产者可以使用
addConfirmListener
方法来添加确认监听器,以处理确认信号。
4.2 从队列中接收消息
消息接收是消息队列系统中的另一个关键操作。接收操作也分为阻塞和非阻塞模式。阻塞模式是默认的接收方式,非阻塞模式允许接收者在队列为空时立即返回,而不是等待消息到来。
4.2.1 阻塞与非阻塞接收模式
阻塞模式下,消费者会持续等待消息的到来,直到消息到达。对于这种模式,RabbitMQ客户端库提供了
basicConsume
方法,这是最简单的接收消息的方式:
import com.rabbitmq.client.*;
public class Consumer {
private final static String QUEUE_NAME = "hello";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [x] Received '" + message + "'");
};
channel.basicConsume(QUEUE_NAME, true, deliverCallback, consumerTag -> { });
}
}
在上面的代码中,
basicConsume
方法用于启动消费者的消费行为。方法的第二个参数为
true
表示启用自动确认消息模式。
非阻塞模式下,消费者会立即得到一个响应,即使队列中没有消息。这种模式通常用于轮询机制,可以通过设置
noAck
参数为
false
来实现:
channel.basicConsume(QUEUE_NAME, false, deliverCallback, consumerTag -> { });
4.2.2 接收确认与消息回执
消息接收的另一个重要方面是确认消息。默认情况下,RabbitMQ假定消息在到达消费者后被成功处理。消费者必须显式地确认(acknowledge)消息,以告诉RabbitMQ它可以安全地删除该消息。这有助于确保不会因消费失败而丢失消息。
在自动确认模式下,消息一旦投递给消费者,RabbitMQ就会认为消息已被接收。但是,在手动确认模式下,消费者需要在处理完消息后调用
basicAck
方法进行确认:
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
如果消费者在确认消息之前失败或崩溃,消息将被重新投递到另一个消费者(如果可用)。如果消费者成功地处理了消息并且希望确认,它应该调用
basicAck
方法。第二个参数为
false
表示单个消息确认,如果设置为
true
,则会确认所有当前消息之前的所有消息。
这节我们深入探讨了消息的发送和接收操作,在使用RabbitMQ进行开发时,理解这些操作对于设计可靠的消息传递系统至关重要。通过合理地利用消息属性、发送确认机制以及确认消息的策略,开发者可以构建出健壮、可靠的应用程序。
5. 队列声明与Direct交换机使用
5.1 队列的基本操作
5.1.1 队列的创建与绑定
队列是消息的存储地,在RabbitMQ中,所有的消息都必须经过队列进行传递。因此,队列的创建与管理是应用RabbitMQ不可或缺的一部分。创建队列可以通过AMQP协议中的
queue.declare
方法来实现。而在使用编程语言进行操作时,通常会借助相应的客户端库来完成。
以下是一个创建队列的基本操作示例代码:
import com.rabbitmq.client.Channel;
public class QueueDeclare {
public static final String QUEUE_NAME = "hello";
public static void main(String[] argv) throws Exception {
Channel channel = connection.createChannel();
// 创建队列,true表示如果队列不存在则创建,durable为true表示队列持久化
boolean durable = true;
boolean exclusive = false;
boolean autoDelete = false;
channel.queueDeclare(QUEUE_NAME, durable, exclusive, autoDelete, null);
channel.close();
connection.close();
}
}
在上述代码中,通过调用
queueDeclare
方法,我们声明了一个名为
hello
的队列。队列声明时,可以通过参数指定是否进行持久化(
durable
)、是否为排他队列(
exclusive
)以及是否自动删除(
autoDelete
)。这些参数需要根据实际应用需求进行配置。
5.1.2 队列的持久化设置
在消息系统中,持久化是指将数据写入到非易失性的存储介质中,确保在系统崩溃或重启后数据不会丢失。在RabbitMQ中,队列和消息都可以设置为持久化。
要设置队列的持久化,需要在队列声明时将
durable
参数设置为
true
。这样即使RabbitMQ重启,队列也不会丢失。需要注意的是,只有在持久化的交换机上声明持久化的队列才有意义,否则队列数据仍可能丢失。
channel.queueDeclare(QUEUE_NAME, true, false, false, null);
在上面的代码示例中,我们已经通过
queueDeclare
方法设置了队列的持久化。这样,即使RabbitMQ服务器重启,队列
hello
仍然存在。
持久化对性能有一定影响,因为它会将信息写入磁盘,因此会比非持久化的操作要慢。因此,在设计系统时需要在数据安全和性能之间做出适当的平衡。
5.2 使用Direct交换机路由消息
5.2.1 Direct交换机的工作原理
在RabbitMQ中,交换机负责接收生产者发送的消息,并根据绑定规则将消息路由到队列中。Direct交换机是最简单的交换机类型,它根据消息中的路由键(Routing Key)直接路由消息到绑定的队列。
Direct交换机的工作原理可以总结为以下步骤: 1. 生产者发送消息,并在消息中指定路由键。 2. 交换机根据路由键将消息路由到匹配的队列。 3. 如果消息的路由键与队列绑定的路由键完全相同,则该消息被路由到该队列。
在代码中实现Direct交换机的绑定可以使用如下方式:
channel.exchangeDeclare(EXCHANGE_NAME, "direct", true);
channel.queueDeclare(QUEUE_NAME, true, false, false, null);
// 将队列绑定到交换机,"routingKey"是绑定的路由键
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "routingKey");
5.2.2 配置Direct交换机与队列绑定
配置Direct交换机需要先声明交换机和队列,然后将队列绑定到交换机。这通常在RabbitMQ的管理界面中通过图形化的方式完成,也可以在代码中通过编程的方式进行。
在Java代码中,我们通过调用
channel.exchangeDeclare
来声明Direct交换机,然后使用
channel.queueBind
将队列绑定到这个交换机上。以下是一个完整的代码示例:
import com.rabbitmq.client.*;
public class DirectExchangeBind {
public static final String EXCHANGE_NAME = "directExchange";
public static final String QUEUE_NAME = "directQueue";
public static final String ROUTING_KEY = "directRoutingKey";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
// 声明Direct交换机,true表示交换机持久化
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.DIRECT, true);
// 声明队列,true表示队列持久化
channel.queueDeclare(QUEUE_NAME, true, false, false, null);
// 将队列绑定到交换机
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, ROUTING_KEY);
// 生产者发送消息
String message = "Hello World!";
channel.basicPublish(EXCHANGE_NAME, ROUTING_KEY, null, message.getBytes());
System.out.println(" [x] Sent '" + message + "'");
}
}
}
在这个示例中,我们首先声明了一个名为
directExchange
的Direct交换机,然后声明了一个名为
directQueue
的队列。通过
queueBind
方法,我们将
directQueue
绑定到了
directExchange
交换机上,并指定路由键为
directRoutingKey
。这样,当生产者通过
directExchange
发送消息时,只有路由键与
directRoutingKey
匹配的消息才会被路由到
directQueue
队列中。
通过上述的代码操作和逻辑分析,我们可以理解Direct交换机是如何工作的。在实际的应用场景中,通过灵活配置Direct交换机与队列的绑定关系,我们可以灵活控制消息的路由规则,以满足各种不同的业务需求。
6. 消息的持久化配置与RabbitMQ集群
在消息队列系统中,消息持久化和集群配置是确保消息可靠传输和高可用性的关键因素。本章将详细讨论如何配置消息持久化以及如何搭建和配置RabbitMQ集群。
6.1 配置消息持久化
6.1.1 消息持久化策略
消息持久化指的是将消息保存在磁盘上,以防止在RabbitMQ重启后消息丢失。有两种消息持久化的策略:
- 队列持久化:将队列信息保存到磁盘,即使RabbitMQ重启,队列也不会消失。
- 消息持久化:确保单个消息在发布时被标记为持久化,只有这样,消息才会在磁盘上保存。
要配置队列持久化,可以在创建队列时设置参数
durable=true
:
channel.queueDeclare("hello", true, false, false, null);
对于消息持久化,需要设置消息属性:
AMQP.BasicProperties properties = new AMQP.BasicProperties.Builder()
.deliveryMode(2) // persistent delivery mode
.build();
channel.basicPublish("", "hello", properties, "持久化消息".getBytes());
6.1.2 持久化对性能的影响
虽然消息持久化可以保证消息的可靠性,但它也会对性能产生影响。在启用持久化时,消息会写入磁盘,这会增加I/O操作的开销,从而导致消息传输的延迟增加。为了平衡性能和可靠性,RabbitMQ提供了不同的持久化策略,如选择合适的磁盘类型,使用高速缓存等。
6.2 RabbitMQ集群与高可用性
6.2.1 集群搭建与配置
搭建RabbitMQ集群的目的是为了提高系统的可用性和容错能力。RabbitMQ集群通常需要奇数个节点(最少为3个)以形成一个法定的仲裁集。集群搭建步骤如下:
- 确保所有节点的RabbitMQ服务都已停止。
- 在每个节点上编辑配置文件
rabbitmq.config,设置集群名称和集群节点。 - 启动所有节点的RabbitMQ服务。
- 使用RabbitMQ管理工具或者命令行来检查节点是否正确加入集群。
6.2.2 高可用性与故障转移
高可用性(HA)指的是系统无中断提供服务的能力。在RabbitMQ集群中,高可用性通过镜像队列实现,即在多个节点上复制队列数据,以确保单点故障不会影响整个系统的运行。以下是实现高可用性的关键点:
- 镜像队列配置:需要在集群启动时配置哪些队列应该被镜像。
- 故障转移:当一个节点失败时,另一个节点能够接管消息处理,保证服务不中断。
- 负载均衡:镜像队列允许在多个节点之间分配负载,提高消息处理能力。
RabbitMQ的镜像命令可以这样配置:
rabbitmqctl set_policy ha-two "^two\." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
在上述命令中,我们设置了策略
ha-two
,指定了队列匹配模式
"^two\."
,配置了两个镜像,并设置了自动同步模式。
通过以上章节的介绍,我们可以看到RabbitMQ消息持久化和集群配置的重要性,以及如何通过配置实现更稳定的系统架构。在下一章节中,我们将深入探讨如何监控RabbitMQ性能和维护系统健康。
本文还有配套的精品资源,点击获取
简介:RabbitMQ是一个广泛使用的开源消息队列系统,它通过AMQP协议提供了高度可用、可扩展和可靠的通信机制。本文将引导读者通过实例学习RabbitMQ的基本操作,包括安装配置、连接服务器、创建队列、发送和接收消息。通过实际编码演示了如何在Java项目中使用
rabbitmq-client
库与RabbitMQ交互,并介绍了如何进行异常处理、消息确认和持久化配置,以及如何利用RabbitMQ的集群特性提升系统的可用性和容错性。
本文还有配套的精品资源,点击获取
版权归原作者 坑货两只 所有, 如有侵权,请联系我们删除。