
一提到Kafka大家都想起了什么,反正在我的脑海里会出现这几个词汇:海量数据,发布订阅,日志处理......
第一次Kafka印象深刻是在我的一次项目部署过程中。本着我把它全学会了就是我的的思想,恬不知耻的将其一位大神的项目copy了下来。当时就觉得,对于已经能够成功搭建老版本Hadoop的我来说这不是小菜一碟吗(搭建完成后就觉得自己是运维届扛把子了)?当时的我是心高气傲,没想到后面的我,却是生死难料。作者推荐的版本是3.x,但是因为专业学的是一个很老的版本(2.几我忘了),我图省事就部了。可能因为2.8版本后的Kafka变动较大,环境搭好后跑了一下,我只能用稀碎来形容,前前后后折腾了十来天......
哈哈哈,Kafka就是这么一个让我又爱又恨的东西。好了,回到正题,Kafka的设计之处本来是一个日志处理工具,我上面所提到的项目中也是用来处理日志的。不过在逐渐的演变下,Kafka慢慢变成了一款性能十分优秀的消息队列。我觉得 Kafka 相比其他消息队列主要的优势如下:
- 极致的性能:基于 Scala 和 Java 语言开发,设计中大量使用了批量处理和异步的思想,最高可以每秒处理千万级别的消息。
- 生态系统兼容性无可匹敌:Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域。
Kafka起初的设计模式是队列模型,这是一个基于队列的消息模型,即消息传递通过队列来完成,并且生产者和消费者是一一对应的,一条消息只能被一个消费者消费,这种模型的好处在于只有一个队列,可以保证消费的顺序性,消息要么被消费掉,要么在队列中过期。不过像这种场景,现在我有条消息,想被多个消费者消费。即希望多个消费者拿到相同的消息内容,这种模型就不好实现了。
现在Kafka的消息模式是发布订阅模式。即我会向某一个主题发布一种消息,而这个主题的多个消费者可以到主题这里拿到消息。就像是作者和阅读者们的关系,从作者监督而言,我创建一篇Kafka的专栏,我想让我的文章被人看见,我只需要将文章放到该专栏即可。而订阅了这个专栏的读者们则可以不定时的从这个专栏获取到我的文章,从而阅读到文章的内容。换种角度,如果我想接收到某种消息,我只需要订阅相应的主题即可。对于消费者而言要做的事情就是根据自己的需要订阅相应的主题;对于生产者而言要做的就是发布消息。
Kafka里有很多重要的概念,比如Producer、Consumer、Broker、Cluster、Topic、Partition。看的人眼花撩乱,不过梳理这些概念的过程可以帮助我们来好好了解下Kafka的运作机制。
Producer:生产者,生产消息的一方,消息发布者。
Consumer:消费者,消费消息的一方。
Broker:这里可以理解为一个Kafka的实例,多个Broker组成一个Kafka Cluster
Cluster:多个Broker组成一个Kafka Cluster。
Topic:存在于代理之中,发布订阅模型的重要部分。
Partition:每个Topic中存在多个分区,每个分区可以横跨多个Broker。
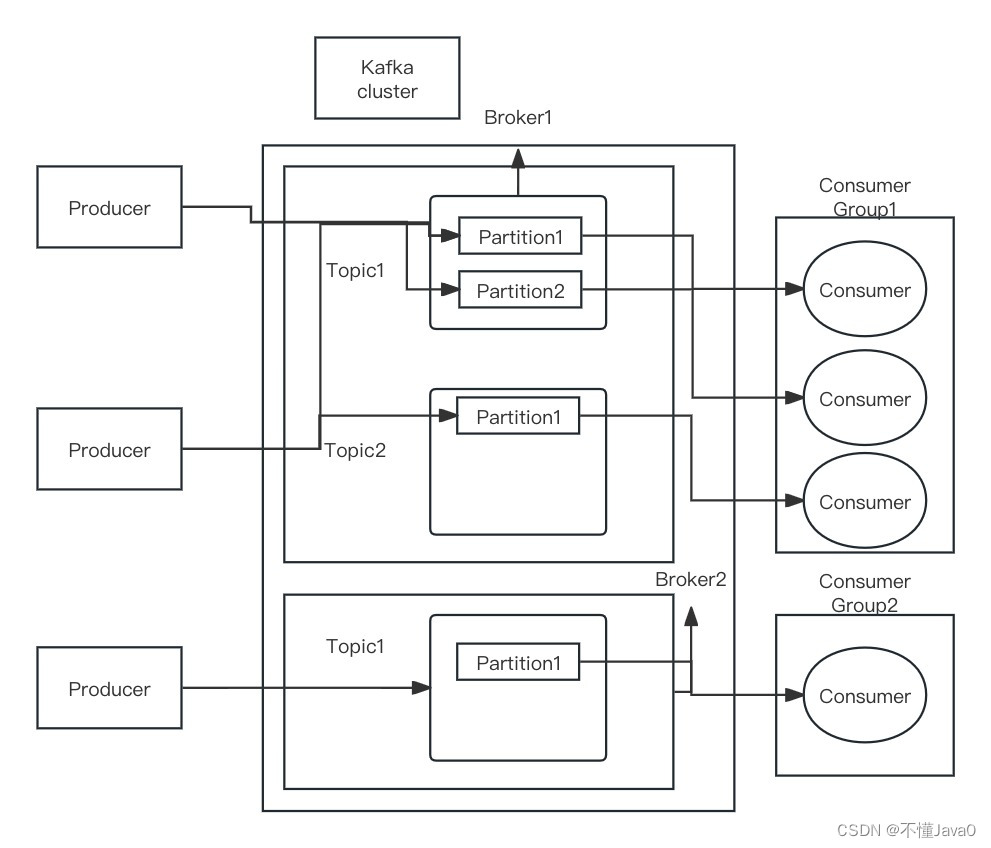
好吧,图画的有些稀烂,如果看不懂了,那就别看了。(看这位大神的图javaguide)
好的,现在我用人话把这个图叙述一遍。咱们依稀可以看到上面所说的发布订阅模型,里面有生产者、主题、消费者之类的信息,但是这个图明显远不止这些信息。我们可以看到这个Kafka集群中有两个Kafka代理,第一个代理中是有两个主题的,主题1和主题2,而代理2中也有一个主题1。
生产者如果想发布主题1类型的消息那么就可以在代理1和代理2两个不同节点上发布。这里这样的设计提升了Kafka发送和消费数据的能力。而消费者们自然可以从不同代理中拿到同一个主题的消息。这可以抽象为我想喝瑞幸咖啡,但是楼下的瑞幸经常爆满,每次都要排队很久。在生产者角度而言,我在楼下再开一家,这就解决了消费者排队等待产出的问题。在消费者角度,这家人多需要排队了,我仍然可以去另外一家店里喝到一模一样的咖啡。
这样的机制为 Kafka提供了很高的性能可是问题来了,假设我有两个相同主题的不同消息A和B,分别发送到了Broker1和Broker2上,原本的消息执行顺序应该是先A后B,可是当分到不同代理节点后,先不要说它们被消费者取到的顺序了,甚至都可能会被不同的消费者拿到。所以消息的顺序性就很难保证了。
对于这种对消费顺序要求强的目前我所知道的有两种办法,第一种呢就是只用一个节点,一个分区,那这样就不会出现消息发送到不同节点,导致纤细消费顺序混乱的情况了,但是这样也就失去Kafka的架构优点了
第二种方法是在每次产生消息后消费者将其路由到指定的代理和分区里,这样也能解决问题。
如何防止Kafka的消息丢失和重复消费
消息丢失有哪几种?我们对于消息没有被消费者成功消费的情况统一称为消息丢失,那么参考上图的话就有很多种情况了。
- 生产者丢失消息:网络原因,消息从生产者这里并没有发送到相应主题上
- 消费者丢失消息:消费者在拿消息的中途挂掉导致没有拿到消息;消费者拿到消息以后还没有消费就挂掉导致消息没有正确被消费
针对第一种情况,我们不能在生产者发送消息后就认为消息发送成功了,Kafka用send()发送消息是异步操作,即负责发送消息的线程进行“发送”操作后就会直接返回,不会等待消息经过网络线路到达相应主题。这保证了效率,可是消息在去往Topic的旅途中出现意外,最终没有到达主题怎么办,Kafka说:“哎!这可就不是我的事了啊。”可怜的消息,就要孤单的上路了......
那消息能答应,业务也不答应呀,那我要你Kafka何用,你连消息的准确性都不能保证。Kafka说哎呀你别急嘛,那我发送了后,再等待结果结果返回不就行了嘛。“不行不行,这样也太慢了。”Kafka:“那我用回调函数总该好了吧。”......
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o);
future.addCallback(result -> logger.info("生产者成功发送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()),
ex -> logger.error("生产者发送消失败,原因:{}", ex.getMessage()));
然后生产者这里的问题算是解决了。消费者这边,我们就需要先了解下Kafka对于数据的多副本机制了
我们知道消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。偏移量(offset)表示 Consumer 当前消费到的 Partition(分区)的所在的位置。Kafka 通过偏移量(offset)可以保证消息在分区内的顺序性。
我们知道消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。偏移量(offset)表示 Consumer 当前消费到的 Partition(分区)的所在的位置。Kafka 通过偏移量(offset)可以保证消息在分区内的顺序性
我们最开始也说了我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。多个 follower 副本之间的消息同步情况不一样,当我们配置了 unclean.leader.election.enable = false 的话,当 leader 副本发生故障时就不会从 follower 副本中和 leader 同步程度达不到要求的副本中选择出 leader ,这样降低了消息丢失的可能性。
Kafka 如何保证消息不重复消费?
kafka 出现消息重复消费的原因:
- 服务端侧已经消费的数据没有成功提交 offset(根本原因)。
- Kafka 侧 由于服务端处理业务时间长或者网络链接等等原因让 Kafka 认为服务假死,触发了分区 rebalance。
解决方案:
- 消费消息服务做幂等校验,比如 Redis 的 set、MySQL 的主键等天然的幂等功能。这种方法最有效。
- 将
enable.auto.commit参数设置为 false,关闭自动提交,开发者在代码中手动提交 offset。那么这里会有个问题:什么时候提交 offset 合适?- 处理完消息再提交:依旧有消息重复消费的风险,和自动提交一样- 拉取到消息即提交:会有消息丢失的风险。允许消息延时的场景,一般会采用这种方式。然后,通过定时任务在业务不繁忙(比如凌晨)的时候做数据兜底。
版权归原作者 不懂Java0 所有, 如有侵权,请联系我们删除。