
在过去的三年中,基于transformer的语言模型(LMs)在自然语言处理(NLP)领域一直占据着主导地位。Transformer 通常是在大量非结构化文本上预先训练的巨大网络,它能够捕捉有用的语言属性。然后,我么可以对预先训练的模型进行微调,以适应各种各样的最终任务,如回答问题或机器翻译,通过微调即使是在少量的标记数据上也可以训练出可用的模型。Switch Transformer发布前,谷歌的T5模型一直是多个NLP基准上的记录保持者,但是最近被它自己的Switch Transformer超越。
并非所有的知识一直都是有用的。在项目总结时这种观察在某种程度上是显而易见的,根据这个观点,谷歌大脑创建了新的Switch Transformer 。
Switch Transformer因其一万亿参数而得到媒体的报道。虽然模型的尺寸确实引人注目,但我发现它的效率更引人注目。对于谷歌的公司规模,这一成就并不难预料;主要的基础模块(Tensorflow, Mesh, Tensorflow, TPUs)已经存在了一段时间。更值得注意的是,在相同的计算成本(以每个输入令牌的FLOPS计算)下,Switch Transformer可以比它的T5的前身可以显着更快地进行预训练。考虑到建立更大模型的持续趋势,Switch Transformer让我们看到了扩大模型尺寸并不一定意味着要消耗更多的资源。
一些说明
以下将使用Switch Transformer这个名称来指代新提出的体系结构,而不是其特定的1.6万亿个实例化实例。本文在多个维度上扩展了该体系结构,包括层数,自我关注头和“专家”。具有特定配置和参数计数的模型的特定实例具有诸如Switch-Base,Switch-Large,Switch-XXL和Switch-C(后者具有1.6万亿个参数)的名称。当将Switch Transformer与其T5的前身进行对比时,作者特别小心地比较了两种架构的兼容实例。再次重申下 本文的Switch Transformer并不仅仅指Switch- C,Switch- C是目前Switch Transformer最大的实例。
为什么称作Transformer的开关(Switch)
与硬件网络交换机如何将传入的数据包转发到其预期的设备类似,Switch Transformer将输入信号通过的模型进行路由操作,仅激活其参数的子集。隐含的假设是并非模型中存储的所有信息都与特定输入相关。这有点解释起来非常的简单,例如在预培训期间遇到的Python 3文档对阅读莎士比亚戏剧时并没有很大帮助。更加直观的解释是并不是所有的知识都能一直有用,这一点是显而易见的,这是Switch Transformer能够提升效率的关键,因为它使推理成本与模型的总尺寸没有了线性的关系。
架构的细节
本节假设你熟悉Transformer体系结构。如果没有,您可以查看无数教程中的一个,比如插图中的Transformer。简而言之,一个Transformer是由多头自注意层组成的深层堆栈。在标准架构中,每层的末尾都有一个前馈网络(FFN)用于聚合来自多个头的输出。Switch Transformer用多个FFN代替了单个FFN,并称它们为“专家”(可以说是一个双曲线)。在每一个转发过程中,在每一层,对于输入中的每一个令牌,模型只激活一个专家。换句话说,在前向传递过程中,Switch Transformer使用的参数数量与标准Transformer的数量大致相同,且具有相同的层数(加上路由参数,这些参数在大小上可以忽略不计)。
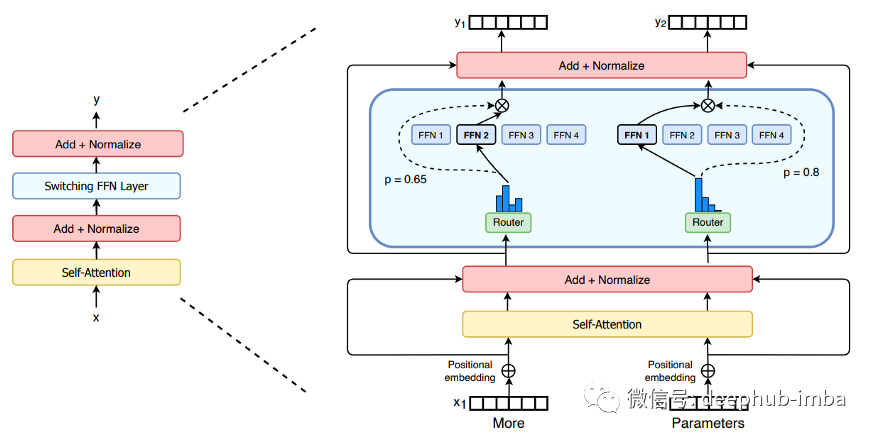
复制FFN权重而不是模型的其他参数(如自我注意中的键/查询/值矩阵)的决定似乎是实验性的。作者论文说,他们试图在模型的其他部分增加专家,结果导致训练不稳定。
模型如何决定启用哪位专家?
给定一个嵌入x的中间令牌(由下面的层产生),模型需要选择一个FFN专家来传递它。决策过程依赖于一个简单的操作序列:
- 将嵌入X乘以路由矩阵Wᵣ(与模型的其余部分一起训练的可学习参数),得到每个专家的得分:得分= x * Wᵣ
- 分数被归一化为概率分布,因此专家们的总和为1:p = softmax(分数)
- 嵌入x以最高的概率通过专家i。最后,输出(即更新的令牌嵌入)是专家产生的激活,并通过其概率得分加权:x'=pᵢ*Eᵢ(x)
Switch Transformer的贡献
它表明一个专家就足够了
神经网络中条件计算的基本思想(每个输入仅激活参数的一个子集)并不是什么新鲜事物。早在四年之前发布的诸如Outrageously Large Neural Networks[2]之类的先前研究就在LSTM的背景下探索了专家混合层:在这样的层上,网络选择了多个专家并汇总了他们的输出。先前的工作认为,至少要有两名专家才能可靠地训练路由参数;先前的理论是,专家与给定输入的相关性只能相对于其他专家来衡量,因此需要对比其中至少两个。
Switch Transformer显示,在存在一个额外的损失项(鼓励跨专家统一使用)的情况下,选择一名专家就足以训练有用的路由参数。但是 这种损失为何如此有效的原因还需要进一步研究。一种可能的解释(论文中未提及)是,虽然每层上的每个令牌都可以激活一位专家,但训练批次却包含多个令牌。由于新增加的损失术语鼓励专家的多样性,因此多令牌批次将在多个专家之间进行某种间接比较。
激活一位专家可以节省FLOPS和通信成本(因为只有一位专家需要将其输出发送到网络的其余部分)。
它提供了训练不稳定的解决方案。
与传统的Transformer相比,Switch Transformer需要跳过其他障碍。首先,关闭模型某些部分的硬切换机制引入了稀疏性。已知模型稀疏性会导致训练不稳定。换句话说稀疏模型可能对随机种子敏感(确定初始参数值,训练数据改组,要剔除的值等),因此有不同训练会导致不同的表现。为了解决训练的不稳定性,作者建议通过将参数的标准偏差来解决。
其次,为了降低计算成本,与更标准的float32相比,Switch Transformer使用bfloat16格式(“ Google Brain Floating Point”)。精度低是训练不稳定的另一个原因。作者通过让专家内部使用float32来解决此问题,同时将bfloat16 API暴露给网络的其余部分。由于每个专家都设置在单个设备上,因此float32值永远不会离开芯片,并且设备间的通信仍保持较低的精度。
它提供了有关规模和效率的有趣研究
考虑到建立更大模型的持续趋势,Switch Transformer让我门看到了扩大模型尺寸并不一定意味着要消耗更多的资源。
通过改变计算预算和参数计数等方面,论文做出了以下有趣的观察:
- 将专家库从1(相当于标准的Transformer)增加到2、4、8,依此类推,直到256,这表明性能持续提高,而没有额外的计算成本(因为无论库的大小如何,只有一位专家被激活 )
- Switch Transformer实现了与常规Transformer相同的性能,而且速度更快。例如,Switch-Base模型在缩短约7倍的时间内即可达到完全融合的T5-Base模型的LM性能。
下游微调的性能
作者表明,Switch-Base和Switch-Large实例化的性能超过了T5-Base和T5-Large实例化的性能,不仅在语言建模方面,而且在大量下游任务(如分类、参考解析、问题回答或总结)上都是如此。
引用
- Fedus et al.: Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity (2021)
- Shazeer et al.: Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer (2017)
作者:Iulia Turc
本文地址:https://towardsdatascience.com/the-switch-transformer-59f3854c7050
deephub翻译组