
数据仓库能够帮助企业做出更好的决策,提高业务效率和效益;在数据仓库建设时,绕不开的话题就是数仓分层。
一、数据分层的好处
1. 降低数据开发成本
通用的业务逻辑加工好,后续的开发任务可以基于模型快速使用,数据需求的响应速度也会更快。
2. 降低任务运维成本
业务发展过程中,数据指标口径、统计逻辑变化是常态,任务失败也屡见不鲜。如果每一次调整都需要对所有的数据任务进行修改,再去回溯数据,那维护起来就比较困难,而且数据还会经常出错。
数仓分层就是希望通过对最基础的、常用的数据进行抽象,找出数据的主干,对主干进行修复后,下游的叶子节点就可以最小变动。例如,当产品改版后,涉及流量统计指标口径需要调整,通过数据分层,只修改最底层的源表的逻辑就可以实现整个链路的数据更新。
3. 方便共享复用,减少重复建设
不同的开发人员、不同时期开发的模型,如果没有分层管理规范,往往导致后期使用时找不到。需要花费很长时间沟通、翻代码确认,最终耗时反而没有重新写一套逻辑来的快。长此以往,数据复用度低,带来存储和计算资源的浪费。
通过数据分层,将数据有序的管理起来,就像图书馆的书架导航,可以快速帮助使用者找到所需要的书籍在那一层书架中。

4. 统一数据口径
同一个指标在数据加工处理时,复用的是同一个数据模型表,这样很大程度可以规避数据统计不统一的问题。
二、数据仓库的分层
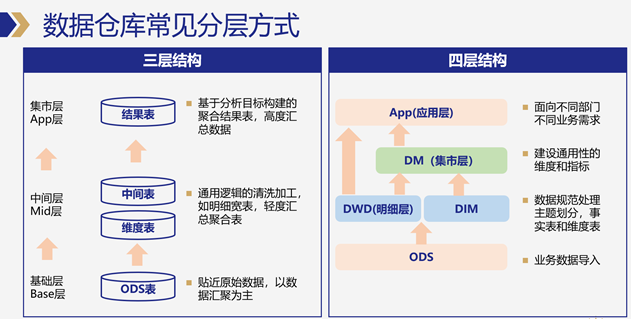
ODS层:源数据层,一般是从各种业务系统、日志数据库将数据汇集到数据仓库中,作为原始数据存储和备份。通过数据同步的方式,将业务从库数据同步到HDFS、Hive等,适合海量数据存储和加工处理的系统中。
DWD层:数据明细层,对ODS层数据进行规范化处理,例如脏数据过滤、数据格式化等,但仍以数据明细方式存储,且将数据进行主题、层级划分。
DIM层:维度表,在维度建模理论中,可以通过业务主题宽表关联维度表方式,快速输出直观的数据分析结果。
DM层:数据集市层,基于对业务的需求的理解和抽象,建立通用的指标和分析维度模型,数据仍以明细为主,部分可以直接累加和汇总的数据指标,可以采用聚合结果的方式呈现。
APP层:数据应用层,面向不同业务部门、不同产品需求提供具体业务场景的结果表,通过数据同步方式再从数仓同步到MySQL等查询引擎,供前端数据产品输出使用。定制化程度高。
三、阿里数仓分层
阿里巴巴数仓分层采用了比传统三层架构更为细致的分层结构,具体包括以下六层:
- 采集层:该层主要负责数据的采集和传输,从各种数据源(如业务系统、应用日志、社交网络等)中收集数据,并将数据传输到数据仓库中进行存储和处理。在采集层中,数据需要进行格式化、清洗、验证等处理,确保数据的准确性和完整性。
- 存储层:该层主要负责数据的存储和管理,包括数据的分区、压缩、索引等操作。
- 计算层:该层主要负责数据的计算和分析,包括数据的加工、转换、聚合等操作。
- 模型层:该层主要负责数据模型的设计和管理,包括物理模型、逻辑模型、维度模型、事实模型等。
- 应用层:该层主要负责数据的展示和可视化,包括BI工具、数据可视化工具、报表系统等
- 安全层:该层主要负责数据的安全和保护,包括数据的访问控制、数据加密、数据备份等。
阿里巴巴数仓分层相比传统的三层架构更为细致,每一层的功能更为明确和专业化,从而能够更好地支持企业的数据分析和决策支持工作。这种分层结构的优点在于,可以将数据处理和管理的工作划分为不同的层级,实现各层之间的解耦和协作,从而提高数据处理和管理的效率和准确性。
四、小结
数据仓库是企业决策过程中必不可少的组成部分,通过数据仓库可以有效地提高企业决策的效率和效益。数据仓库的分层架构可以帮助企业更好地管理和维护数据仓库,提高数据仓库的可扩展性、可维护性和可管理性。数据仓库的建设过程需要经过多个步骤,包括需求分析、数据清洗和预处理、数据仓库模型设计、数据集成和管理、元数据管理、数据挖掘和分析、部署和维护。
版权归原作者 小中. 所有, 如有侵权,请联系我们删除。