
以Ubuntu22.04版本为例
一、查看网络信息
Ubuntu系统一般是不配有ifconfig命令的,虽然使用ip addr命令也能查看网络配置,但个人觉得还是ifconfig命令展示的更为清晰。
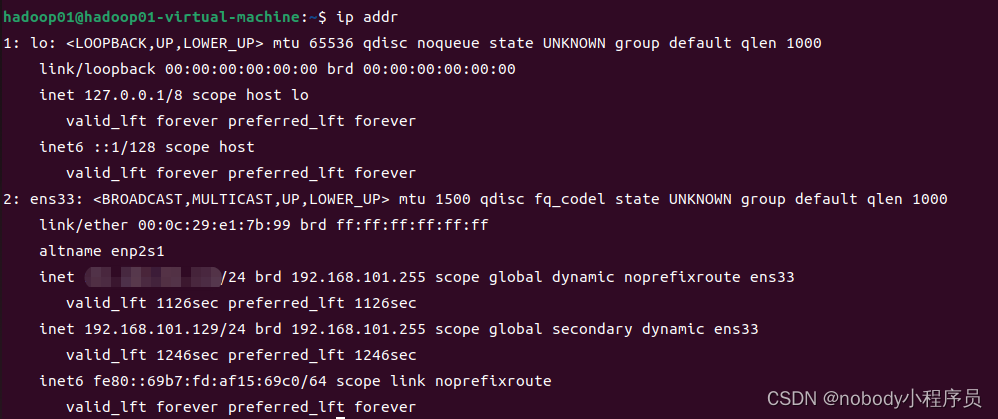
ip addr命令展示的网络配置
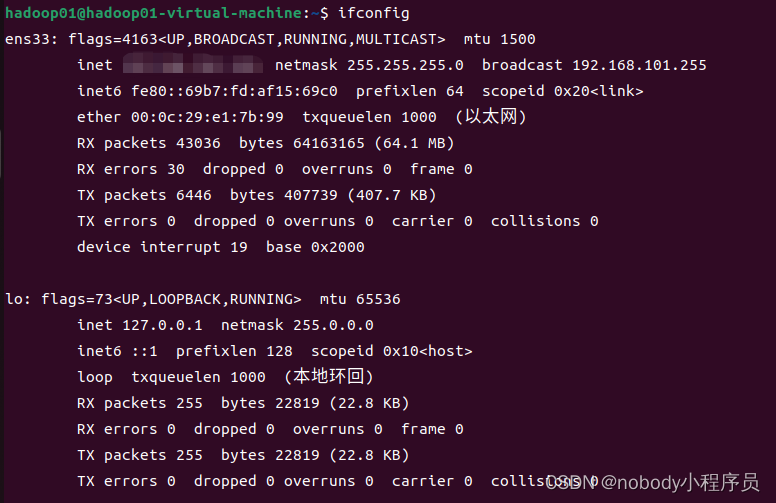
ifconfig命令展示的网络配置
安装ifconfig管理命令,在终端输入
sudo apt-get install net-tools
随后输入
ifconfig
查看网络配置
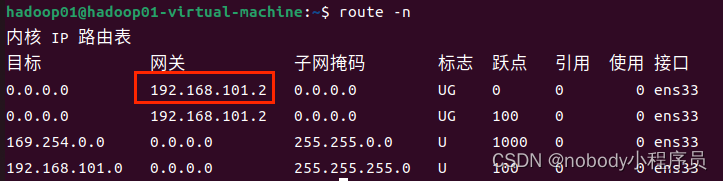
再输入
route -n
查看网关地址
二、修改网络配置
Ubuntu17.10以下版本,在/etc/network/interfaces里面配置IP,Ubuntu17.10以上版本,在/etc/netplan/XX-installer-config.yaml的yaml文件中配置IP地址。
先找到本机的文件名(etc->netplan)
再终端中输入
sudo gedit /etc/netplan/01-network-manager-all.yaml
打开文件后看到的应该是
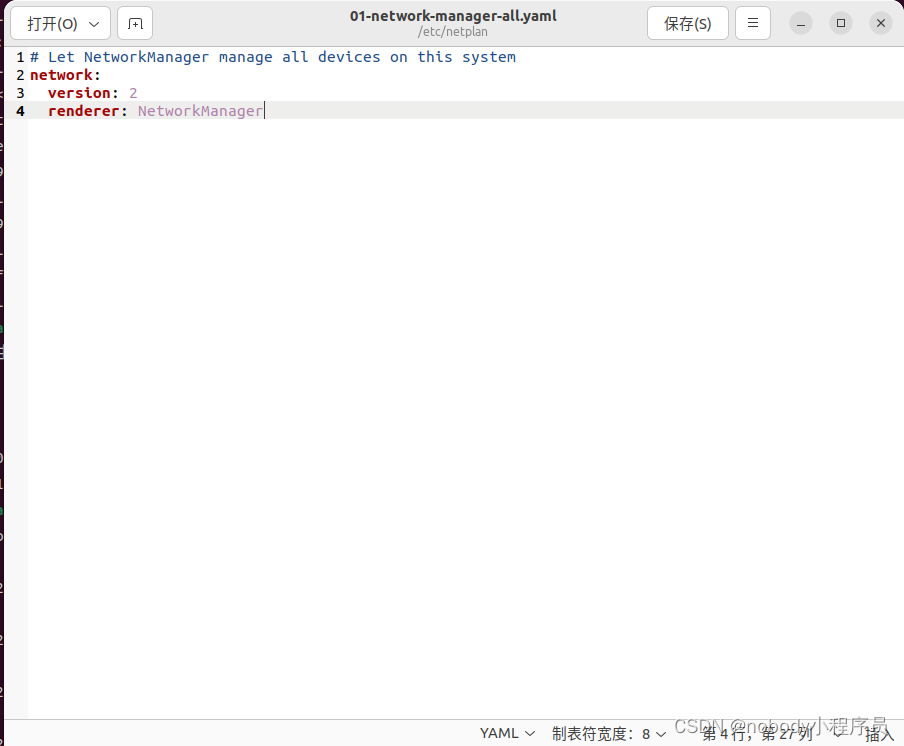
在network:和version:中间加入
ethernets:
ens33:
addresses: [192.168.101.101/24]
dhcp4: false
optional: true
gateway4: 192.168.101.2
nameservers:
addresses: [192.168.101.2,114.114.114.114]
记得改成自己的网络信息

之后输入
sudo netplan apply
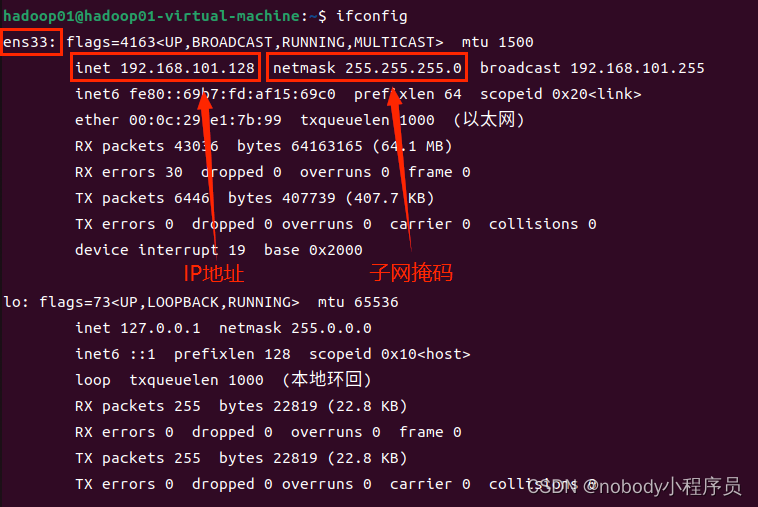
再次用ifconfig命令查看网络信息
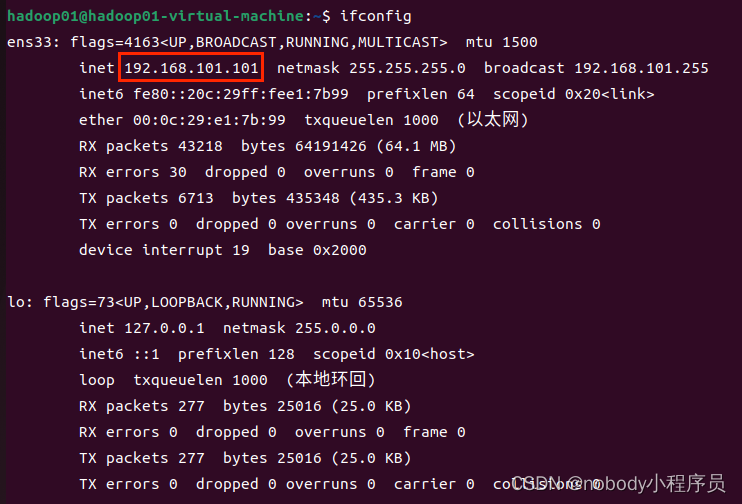
变得和配置的ip一样,配置成功。
三、安装SSH客户端
为了方便虚拟机与宿主机(装着虚拟机的电脑)的文件传输,可以借助远程SSH连接工具。最好用的是SecureCRT,不过不是免费的(提供30天免费试用)。我们可以选择免费的Bitvise SSH Client。官网为:https://www.bitvise.com/ssh-client-download。
下载安装包:
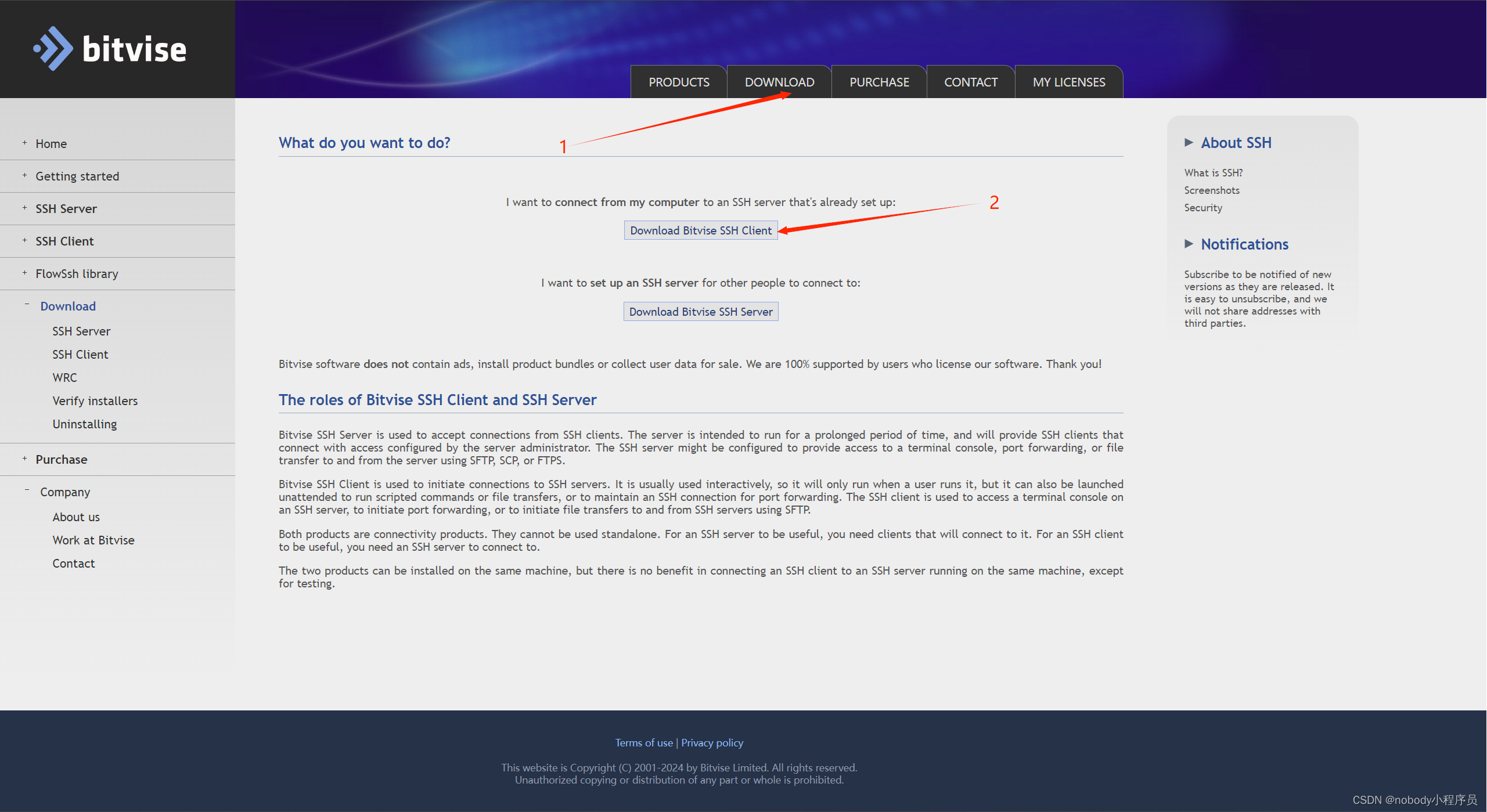
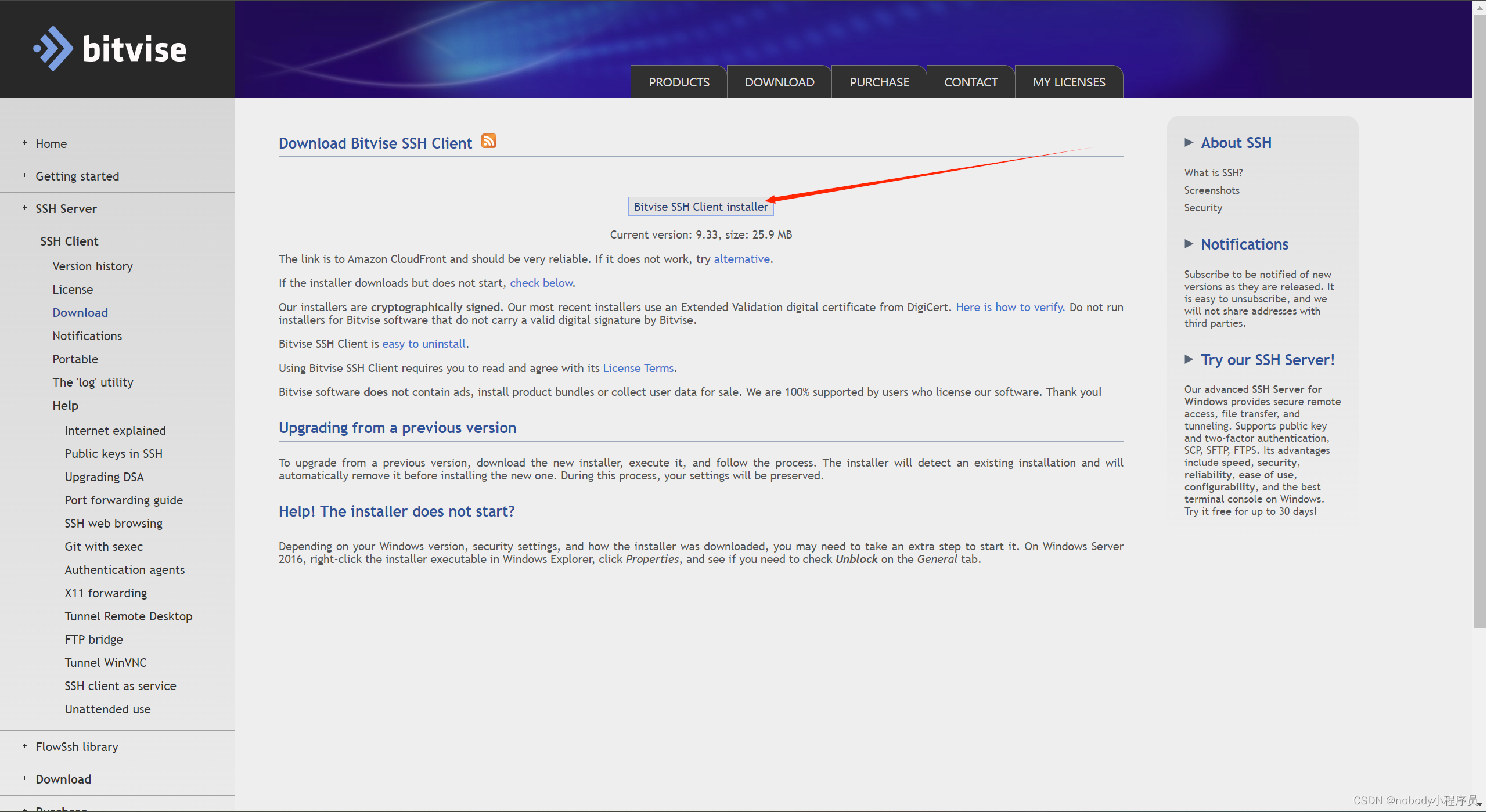
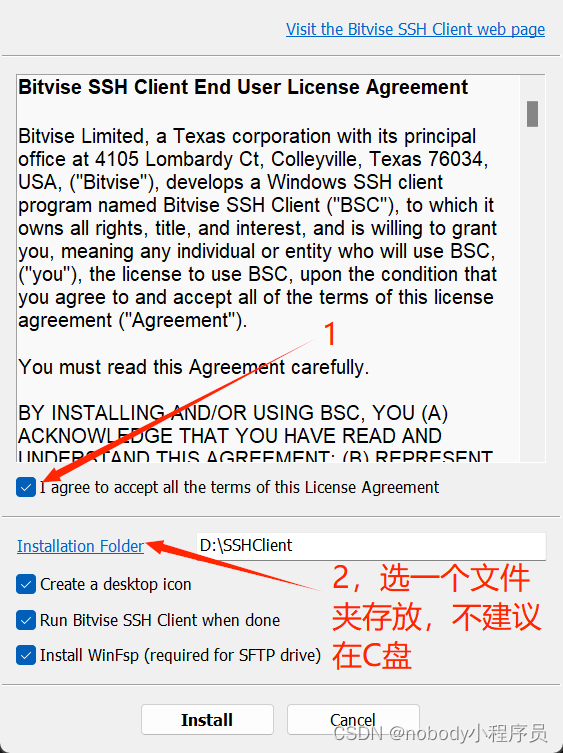
打开安装包
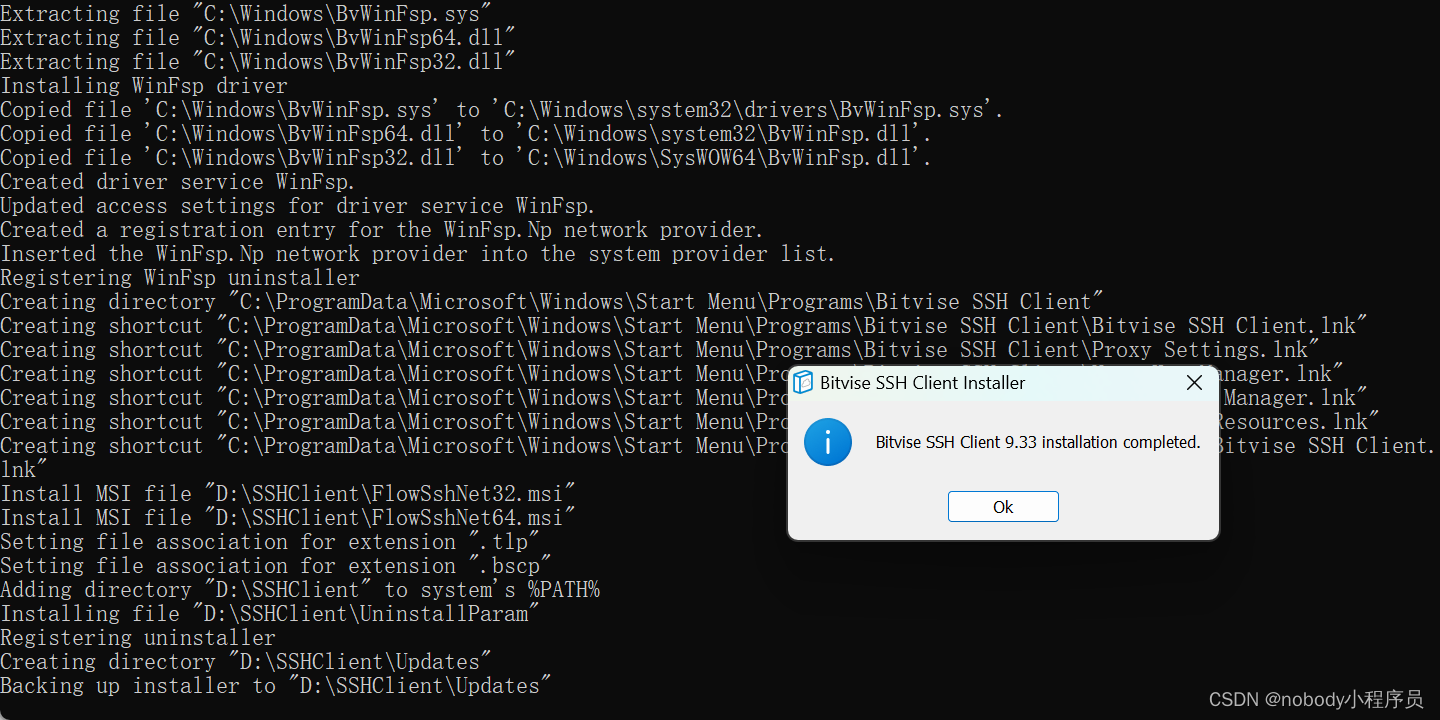
安装完成
进入Bitvise SSH Client,输入虚拟机信息
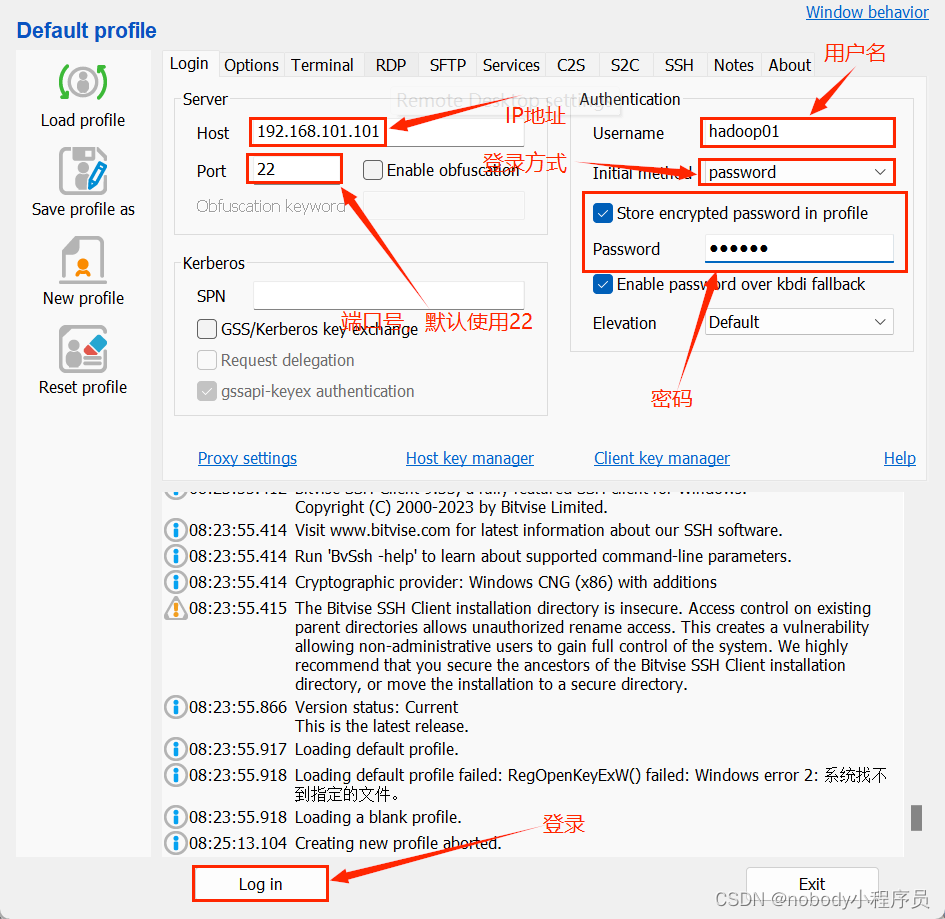
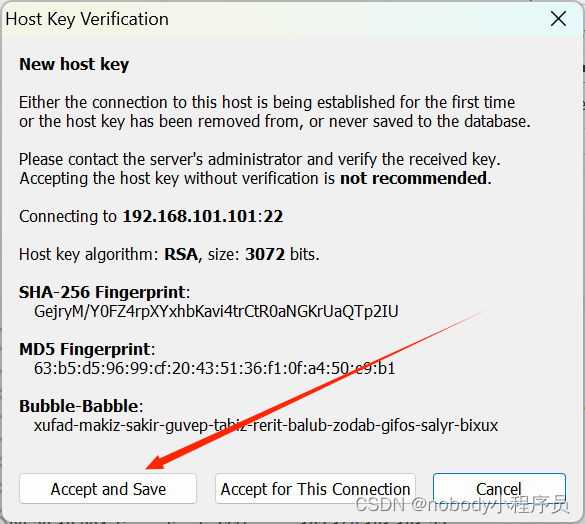
第一次连接回跳一个弹窗,选择接受即可
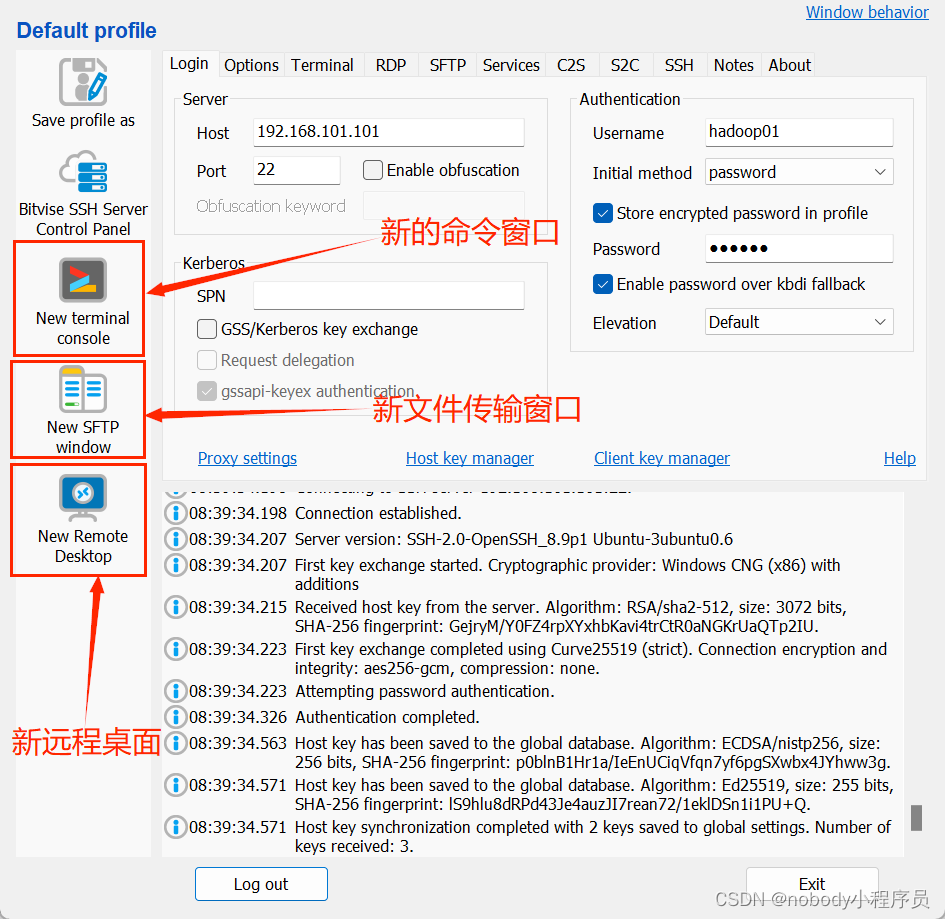
之后便可以远程使用你的虚拟机了
四、虚拟机配置JDK
虚拟机JDK版本尽量和主机保持一致,以安装JDK17为例。另外注意的是Hadoop从2015年开始,只支持JDK7+,注意版本不要太低。
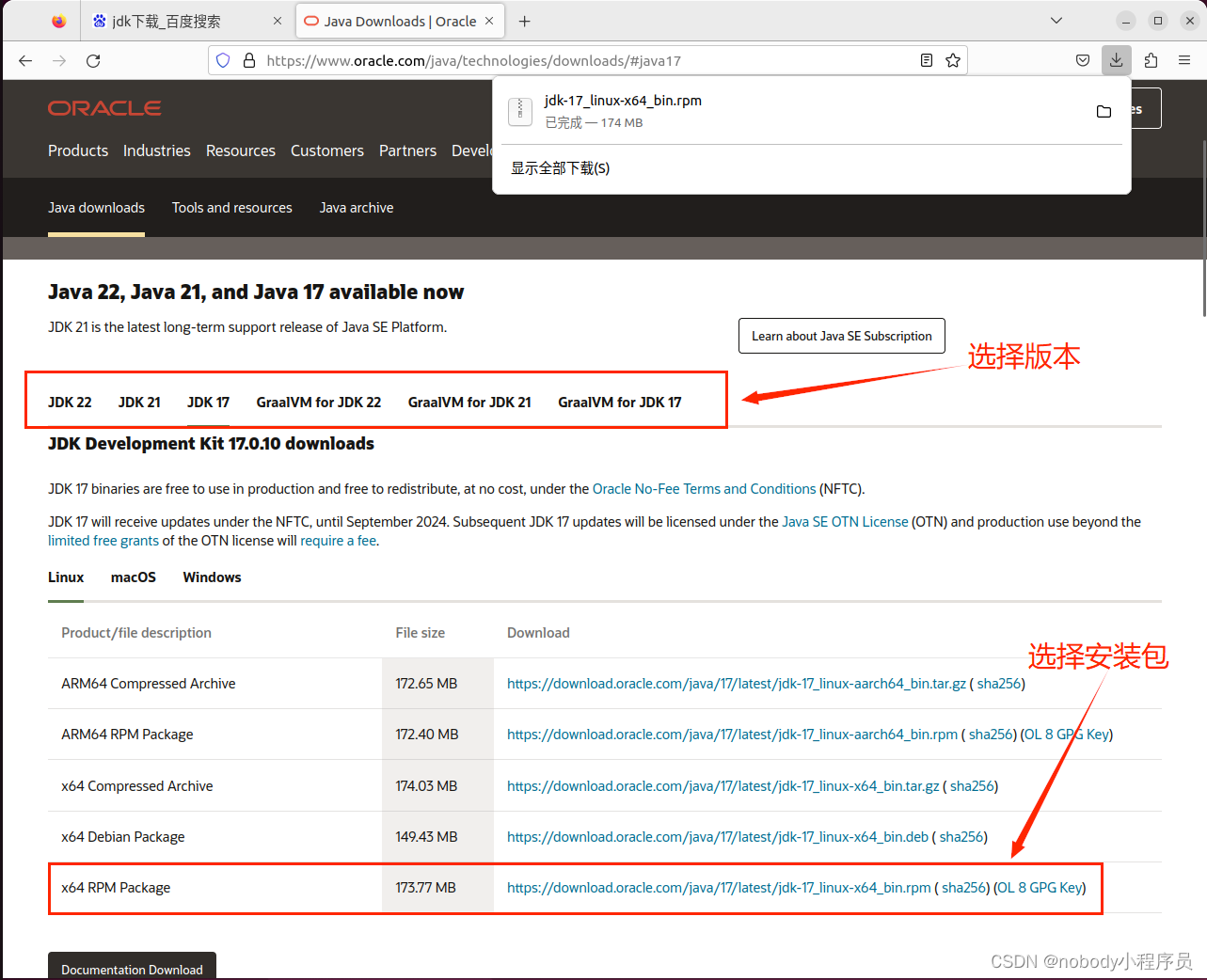
先进入官网Java Downloads | Oracle下载安装包,这里我们使用RPM包安装,实际上tar.gz包更灵活一些,有需要自行学习使用。
输入
sudo alien -i -c -v '/home/hadoop01/下载/jdk-17_linux-x64_bin.rpm'
来解压安装包,一般默认路径为usr/java/jdk-17
如果显示alien找不到命令,说明系统没有安装alien,输入
sudo apt-get install alien
即可,接着继续配置
sudo gedit /etc/profile
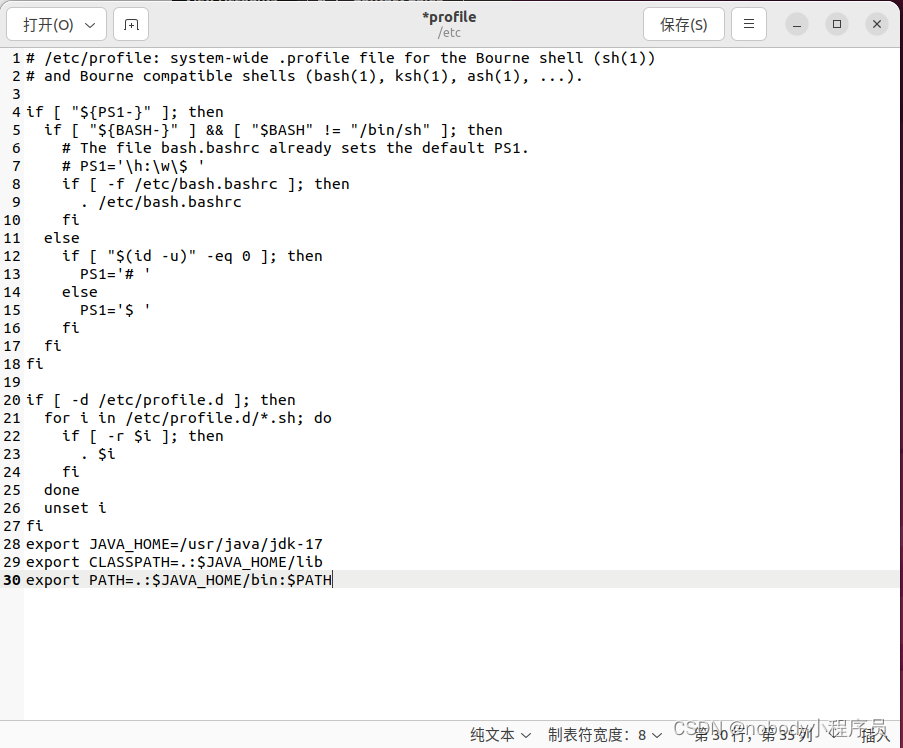
在末尾加上
export JAVA_HOME=/usr/java/jdk-17 //你安装jdk的路径,可能不一样
export CLASSPATH=.:$JAVA_HOME/lib
export PATH=.:$JAVA_HOME/bin:$PATH
保存之后在终端中输入
source /etc/profile
使配置生效。
再检查一下java环境是否配置成功
终端中输入
java -version

成功显示版本,配置成功。
五、Spark下载
进入官网Downloads | Apache Spark,选择版本下载安装包
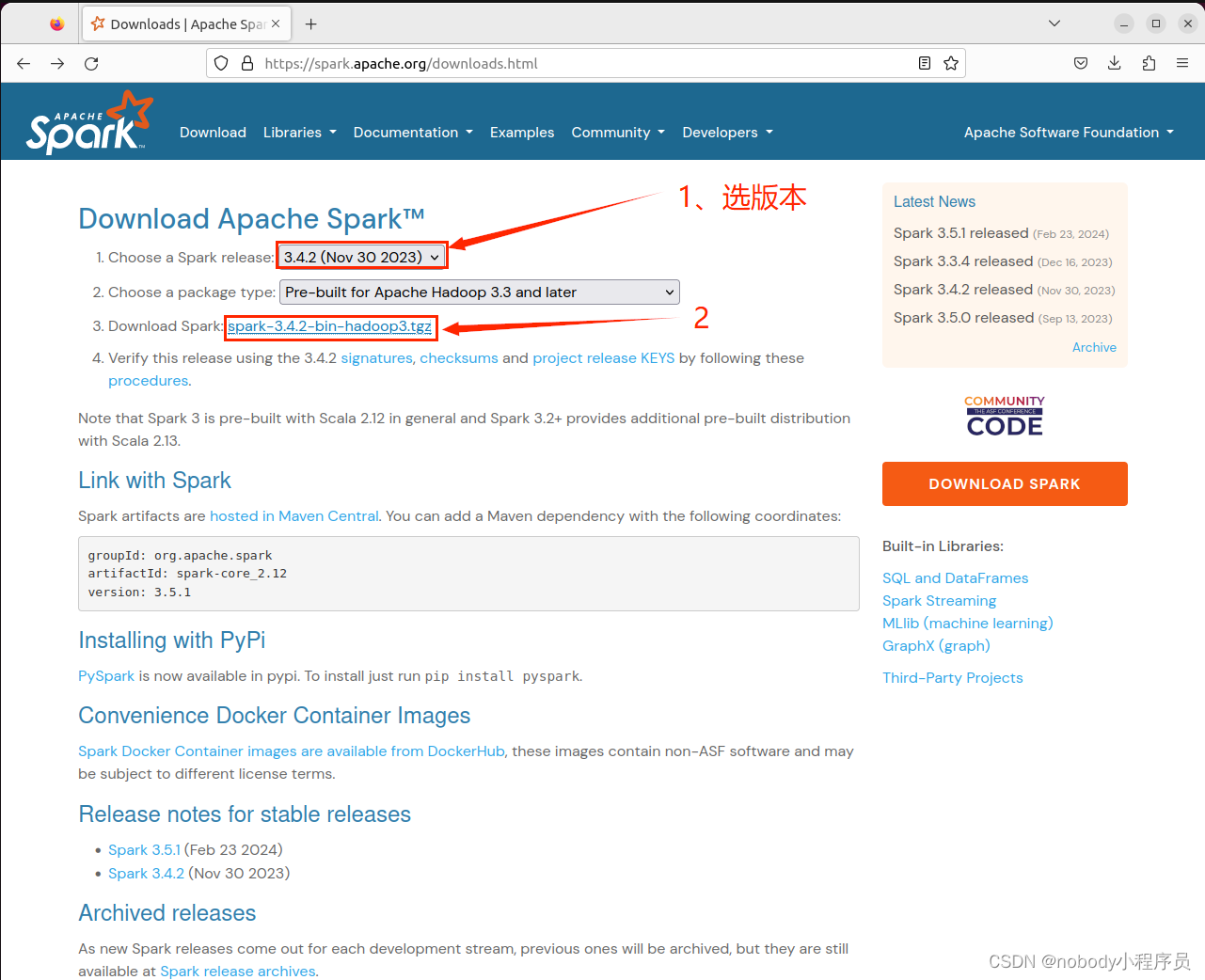
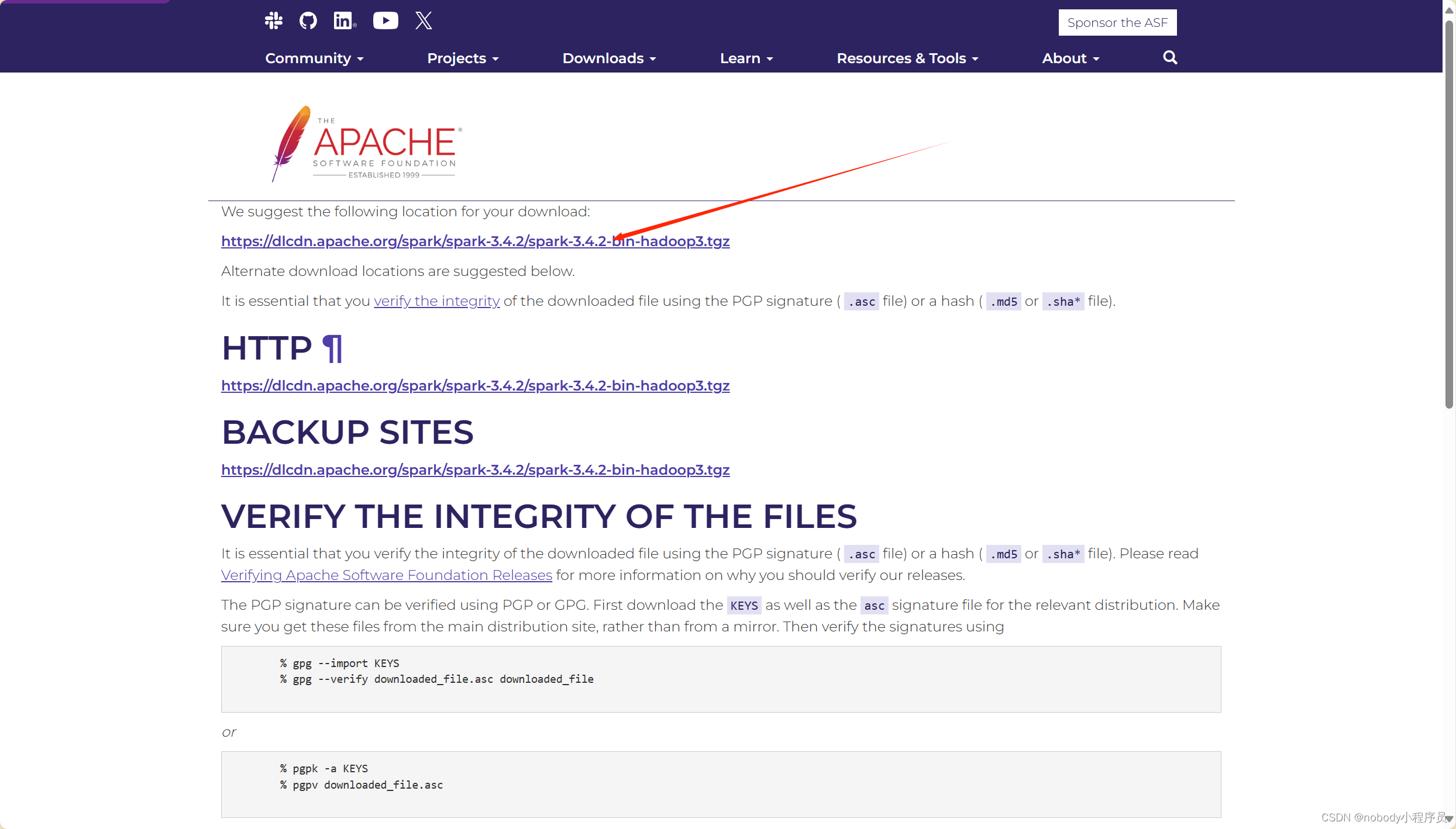
如果在虚拟机下载很慢,可以在主机上下载好,在传到虚拟机上。
使用Bitvise SSH Client,选择新建文件传输窗口

选好想传输的文件和想传输到的位置,直接拖动文件到目标位置

传到虚拟机上后输入
tar xvf '/home/hadoop01/下载/spark-3.4.2-bin-hadoop3.tgz'
解压安装包,解压完成后主页面会多出一个spark文件夹
输入以下命令进入交互式编程界面
cd '/home/hadoop01/spark-3.4.2-bin-hadoop3' //进入解压后多出来的目录
./bin/spark-shell --master local[2] //打开spark-shell, local是指运行在本地,[2]是指启动两个工作线程
等待一段时间后会出现如下画面
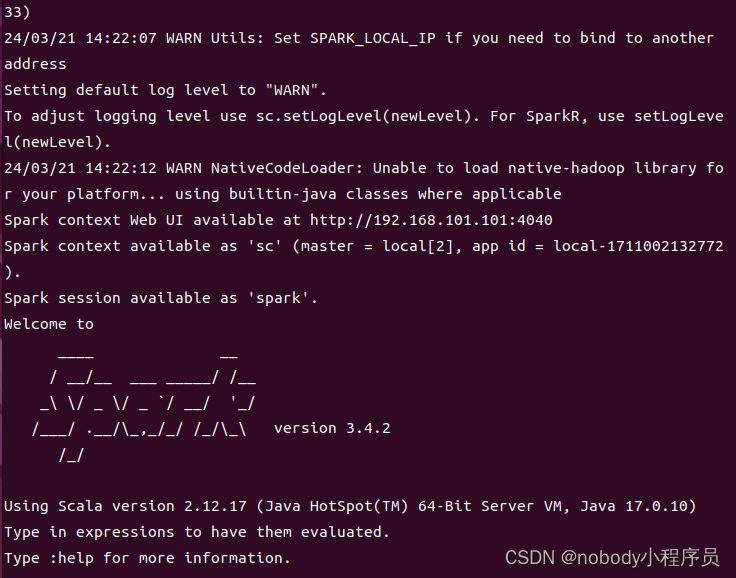
spark安装成功。
同时启动spark服务时Master会启动一个Web服务,默认绑定在本地的4040端口上
版权归原作者 nobody小程序员 所有, 如有侵权,请联系我们删除。