
深度学习是关于数据的,我们需要将数据以矩阵或更高维向量的形式表示并对它们执行操作来训练我们的深度网络。所以更好地理解矩阵运算和线性代数将帮助您对深度学习算法的工作原理有更好的理解。这就是为什么线性代数可能是深度学习中最重要的数学分支。在这篇文章中,我将尝试对线性代数做一个简单的介绍。
我们所说的数据是什么意思?
让我们考虑一个简单的例子,在这个例子中,你有每栋房子的属性,你的目标是尝试预测给定房子的价格。这些属性也称为解释变量(EV),我们将利用它们来训练我们的模型。为简单起见,我们将只考虑三个属性:卧室数量、房屋大小、位置。现在,每栋房子都将表示为一个包含三个值的向量。
[X_numberOfBedrooms, X_size, X_location]但是等等,这里我们只考虑一所房子。我们通常拥有由数千栋房屋组成的数据集,每栋房屋都称为一个数据点。此时,我们要做的就是将房屋的向量堆叠起来,形成一个矩阵。每行代表一所房子,每列代表一个解释变量。
x₁₁:第一个房子的房间数
x₂₁:第一个房子的大小
x₃₁:第一个房子的位置
简单线性回归
我们将尝试建立一个简单的模型来预测给定房屋的价格。让我们采用三个解释变量的线性组合。这可能是你能得到的最简单的模型;简单的线性回归。现在让我们正式来看一下:
Y = Xβ+ϵ
我们有三个权重乘以每个 EV。可以将它们视为每个变量在决定价格方面的重要性。简单的想一想:房子大,地段好,价格肯定高。因此,所有EV与价格呈正相关。通过查看最高权重,我们可以确定最相关的变量,这将使我们很好地了解模型对每个变量的敏感性。现在,让我们用矩阵表示法重写所有内容。
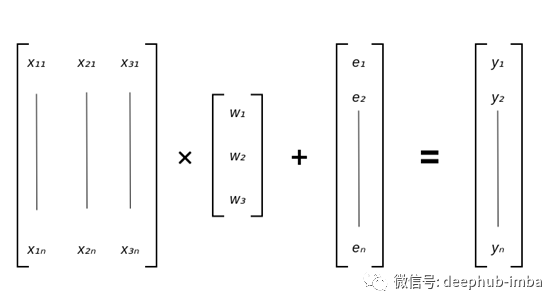
如您所见,以矩阵形式编写所有内容可以更简洁地描述正在发生的事情。但是我们如何乘以矩阵呢?别担心,它既简单又直观。
矩阵乘法
首先让我们地思考一下;我们只是想将每个 EV 与其相应的权重相乘。我们有 n 个房屋/示例,因此从逻辑上讲,我们应该将设计矩阵中的每一行与列向量 W 相乘。为简洁起见,我们将考虑一个包含两个示例和三个解释变量的简单示例:
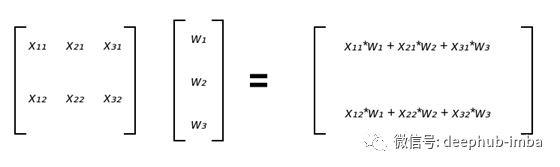
矩阵和列向量相乘将产生另一个列向量。
现在让我们考虑将两个矩阵相乘。不要忘记矩阵相乘,第一个矩阵的列数应该与第二个矩阵的行数相同。所得矩阵的大小可以很容易地计算出来:如果 A=[aij] 是一个 m×n 矩阵,而 B=[bij] 是一个 n×k 矩阵,则 AB 的乘积是一个 m×k 矩阵。现在已经知道如何将两个矩阵相乘。假设有多个列向量,相乘的过程与将矩阵与向量相乘的过程相同,但是我们要将得到的列向量并排堆叠成一个矩阵。
PyTorch 和张量
这里我们使用 PyTorch 并将它们用于矩阵乘法。PyTorch 是众所周知的深度学习库,张量(Tensor)起着至关重要的作用。您可以将张量视为更高维的矩阵,而 PyTorch 允许我们高效地对它们执行数值运算。现在可能已经猜到了,矩阵和张量构成了深度学习的基础。
让我们看一个简单的例子,我们初始化两个矩阵并对它们执行矩阵运算:
A = torch.tensor([[1,2,3] , [2,3,4]])
B = torch.tensor([[3,1] , [4,2] , [2,3]])
torch.matmul(A,B)

神经网络
把到目前为止我们学到的应用起来,我们就可以开始应用矩阵运算来表示神经网络了。将假设你了解神经网络的基础知识,让我们看看我们的模型架构对于单个隐藏层的需求。
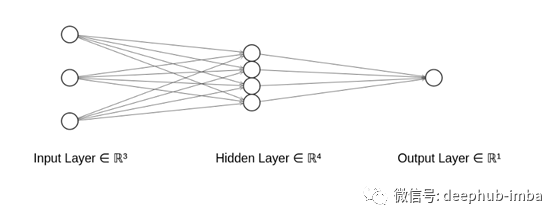
从上图可以看出,我们有输入神经元,它们的表示方式与我们的房屋数据相同。接下来,我们的隐藏层有四个神经元。每个神经元将是通过非线性函数的输入神经元的线性组合。在这个例子中,我们将考虑一个广泛使用且易于理解的激活函数。RELU是一种激活函数,如果输入值为负则输出零,否则输出输入。在数学上,ReLU 函数是 f(x)=max(0,x)。为了表示隐藏层中的四个神经元,我们将我们的设计矩阵与一个四列三行的权重矩阵相乘;行数应等于输入的维数,列数应等于后续层中目标神经元的数量。
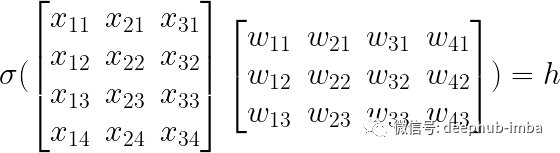
剩下的就是最终的输出层。输出神经元又是前一层神经元的线性组合。由于我们正在处理一个回归问题,我们需要一个无界的值,因此我们不需要最后一层的激活函数。这一层的矩阵乘法要容易得多,因为我们将只采用隐藏层的线性组合。这应该类似于线性回归,实际上,它正是线性回归。整个模型可以表示如下:

总结
所有深度学习操作都使用矩阵计算来表示。学习有关如何在矩阵和张量中表示数据的基础知识,将使您对底层的理论有更好的理解。如果相对线性代数进行更深入的学习,Gilbert Strang 教授的精彩讲座令人难忘(https://ocw.mit.edu/courses/mathematics/18-06-linear-algebra-spring-2010/)
本文作者:Taha Binhuraib