
本文仅代表个人观点,不保证正确性。
一、NCCL简介
1.什么是NCCL
NCCL是NVIDIA集合通信库(NVIDIA Collective Communications Library)的简称,是用于加速多GPU之间通信的库,能够实现集合通信和点对点通信。NCCL在通信方面做了很多优化,能实现Collective通信和点对点通信,能够在同一节点内或不同的节点之间提供快速的GPU通信服务,支持多种互连技术,在同一节点内包括NVLink、PCIe、Shared memory、GPU Direct P2P,在不同的节点间支持GPU Direct RDMA、Infiniband、socket

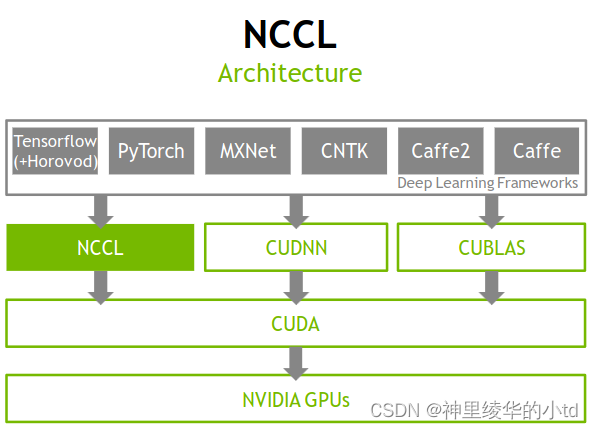
下面是NCCL在神经网络训练的整体架构示意图。在这个架构中,最顶层的灰色矩形方框代表的是深度学习框架,这个框架需要三个部分,CUDNN是一个深度学习库,实现并优化了多种神经网络的算法,加快了深度学习训练的速度,CUBLAS线性代数库,提供常见的线性代数操作,很好地支持深度学习框架,NCCL用于加速多GPU之间通信。NCCL、CUDNN、CUBLAS的底层都需要CUDA库的支持才能实现。CUDA提供一些接口可以方便地编写GPU程序,并可以在多个 GPU上并行运行。
2.GPU的通信方式
在NCCL出现之前,GPU之间常见的通信方式是使用MPI(Message Passing Interface)来实现,MPI是一种用于编写并行程序的标准接口,它可以在多台计算机之间进行消息传递和同步操作。在使用MPI时,GPU可以将数据复制到主机内存中,然后通过MPI发送到其他GPU的主机内存中。在同一主机中,GPU之间可以通过CUDA API提供的点对点通信功能,如果使用相同的PCIE总线来实现,这种通信方式可以省去将数据从GPU复制到主机内存这一步骤,减少数据拷贝的开销。
3.NCCL的优势
NCCL可以实现单机多卡、多机多卡之间的通信,将通信方式进行了整合和优化,在节点内和节点间的多个GPU上提供快速的集合通信服务,同时支持各种互连技术,包括PCIe、NVLINK、InfiniBand Verbs和IP socket,NCCL与大多数的多GPU并行化模型都能很好地兼容。
二、常见的相关技术
1.NVLink

在NVLINK方案推出之前,为了获得更多的强力计算节点,多个GPU通常与PCIe Switch直接与CPU相连,但是这种方案受制于PCIE的带宽,为了应对这一问题,提出了新的互联架构NVLink,NVLink不但可以实现GPU之间以及GPU和CPU之间的互联,还可以实现CPU之间的互联

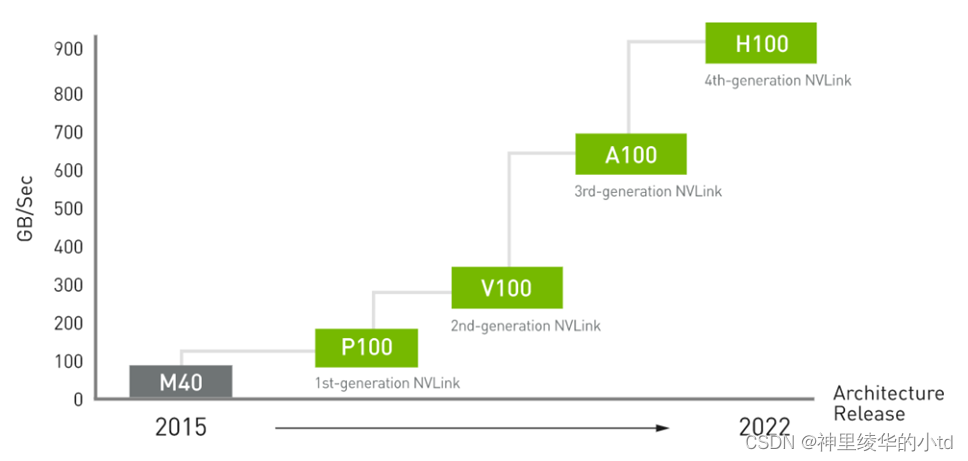
nvlink是一种双工双路信道,nvlink 二代的信号传输率到了25Gb/s,双信道总计50GB/s,同时提升了nvlink数到6路,每个v100的总带宽达到了300GB/s,第四代NVLINK的速度达到了900GB/s.
2.GDR
GDR(GPU Direct RDMA)是一种GPU与远程GPU直接通信的技术,以RDMA技术为基础,GPU通过与同一PCIE switch相连的RNIC与远程的GPU直接通信。与之前的技术相比,这一过程不需要CPU的参与,省去了系统内存拷贝这一步骤,减少了PCIE的传输次数

三、NCCL数据通信链路的选择
为指定通道选择可用的传输方案使用selectTransport函数,首先获取本地节点和远程节点的相关信息,然后针对每种可用的传输方式调用canConnect()函数来检查是否能够使用该传输方式进行通信。传输方式选择的顺序依次为P2P>SHM>netTransport>collnet,找到可以使用的传输方式后,该函数调用setup()进行配置连接,并将传输方式存储在相应的连接器(connector)中。最后该函数将选择的传输方式存储在transportType指针中,以便后续使用
ncclTopoSelectNets用于在拓扑系统中为指定 GPU 设备选择合适的网络,该函数为每个要通信的GPU生成一个list,对于每个GPU节点,该函数筛选具有匹配类型的NIC,并将结果存储在本地NIC计数器(localNetCount)和本地NIC索引列表(localNets)中,然后使用NVML设备对本地NIC索引列表进行shuffle,确保同一PCI交换机上的多个GPU不会同时使用同一个NIC,最后将每个新找到的NIC添加到nets中
版权归原作者 神里绫华的小td 所有, 如有侵权,请联系我们删除。