
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
如今,机器学习领域的科学进步速度是前所未有的。除非局限在一个狭窄的细分市场,否则要跟上时代的步伐是相当困难的。每天都有新论文出现并声称自己取得了一些最先进的成果。但是这些新发现中的大多数从来没有成为默认的首选方法,有时是因为它们没有最初希望的那么好,有时只是因为它们最终在新进展的洪流中崩溃了。
我最近浏览了一些有关于激活函数的相对较新的论文。让我们来看看几个最有前途的激活函数,看看它们为什么好以及何时使用它们。但在此之前,我们将快速浏览常用的激活,以了解它们解决或创建了哪些问题。如果您能区分 PReLU 和 RReLU,那么请跳过前两个部分。
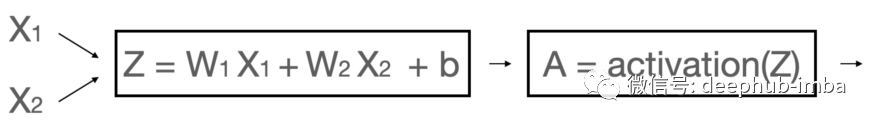
激活函数原则上可以是任何函数,只要它不是线性的。为什么?如果我们使用线性激活就等于根本没有激活。这样我们的网络将有效地变成一个简单的线性回归模型,无论我们使用多少层和单元。这是因为线性组合的线性组合可以表示为单个线性方程。
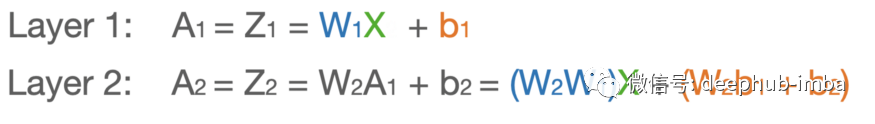
这样的网络学习能力有限,因此需要引入非线性。
经典激活函数
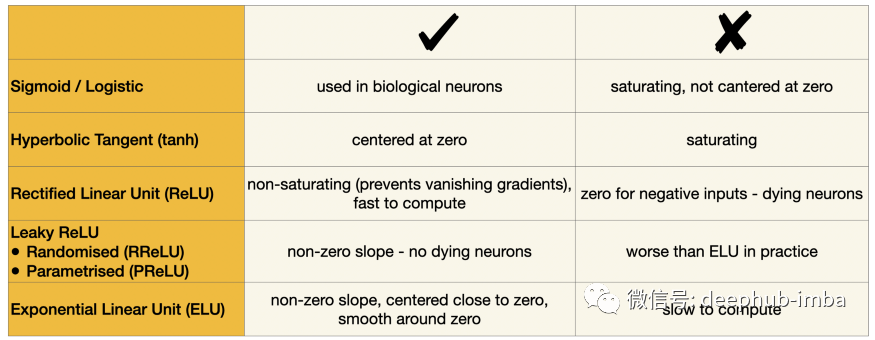
让我们快速浏览一下五个最常用的激活函数。在这里,它们是使用 numpy 实现的。
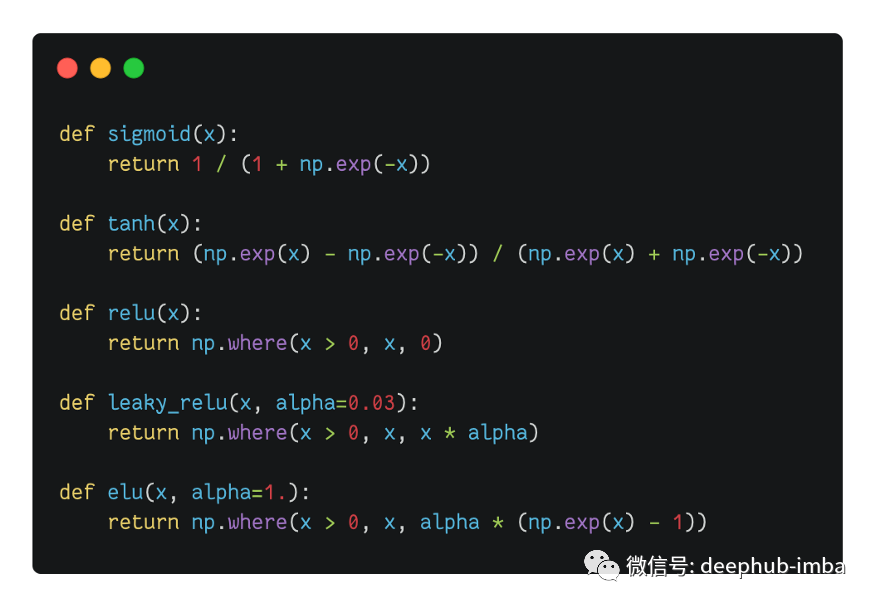
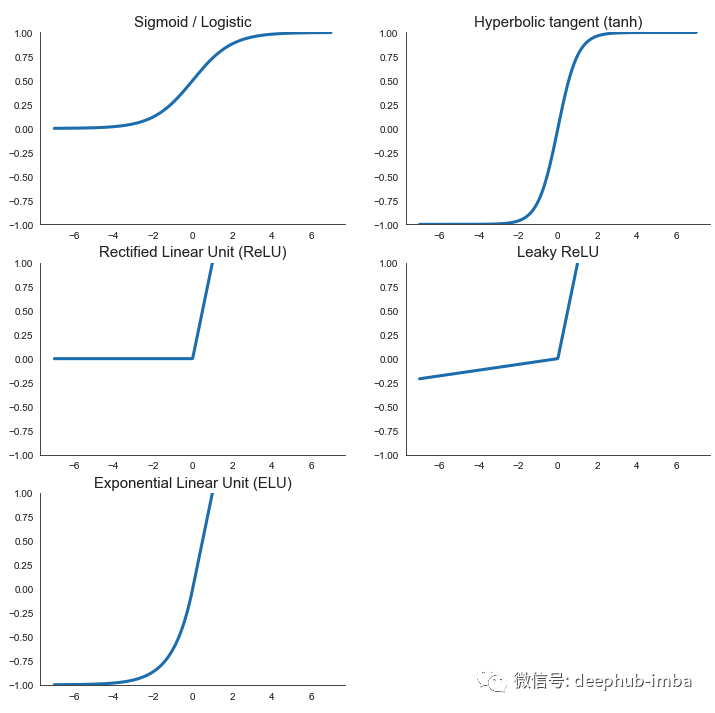
这是它们的样子:
让我简短地总结下他们。
Sigmoid 是在历史上是第一个取代早期网络中的阶梯函数的激活。从科学角度讲这来自于用于激活我们生物大脑中神经元的功能。sigmoid 定义明确的非零导数允许使用梯度下降来训练神经网络。从那时起,sigmoid 变成网络隐藏层内无法替代的激活函数,尽管他当初是被用作二元分类任务的最终预测层的(现在也这么使用)。
双曲正切 (tanh) 的形状与 sigmoid 非常相似,但它的值介于 -1 和 1 之间,而不是介于 0 和 1 之间。因此,它的输出更多地以零为中心,这有助于加速收敛,尤其是在训练初期。
然而,sigmoid 和 tanh 都有一个问题:它们都是饱和函数。当输入非常大或非常小时,斜率接近于零,使得梯度消失并且学习变慢。因此就出现额非饱和激活。最成功案例就是修正线性单元 (ReLU) 函数,它不会对正值饱和,并且计算速度很快,并且由于没有最大值,它可以防止梯度消失问题,直到现在还是使用最多的激活函数并且没有之一。但是它有一个缺点,称为死亡 ReLU。问题是 ReLU 为任何负值输出零。如果网络的权重达到这样的值,以至于它们在与输入相乘时总是产生负值,那么整个 ReLU 激活单元会不断产生零。如果许多神经元像这样死亡,网络学习能力就会受损。
为了缓解 ReLU 问题,有人提出了对 ReLU 的一些升级。Leaky ReLU 对于负值具有很小但非零的斜率,可确保神经元不会死亡。这类激活函数的一些奇特变体包括Randomized Leaky ReLU (RReLU),其中在训练时随机选择这个小斜率,或Parametrized leaky ReLU (PReLU),其中斜率被视为网络参数之一并通过梯度下降进行学习。
最后,指数线性单元 (ELU) 出现了,击败了所有ReLU 变体。它采用了所有世界中最好的:负值的非零梯度消除了神经元死亡问题,就像在leaky ReLU中一样,负值使输出更接近于零,就像在tanh中一样,最重要的是,ELU在零附近是平滑的,这加速收敛。不过它也有自己的问题:指数函数的使用使得计算速度相对较慢。
以下是为方便起见整理的经典激活的对比:
现在让我们来看看一些最近的发现吧!
Scaled ELU (SELU)
Klambauer 等人在 2017 年的一篇论文中介绍了 Scaled ELU 或 SELU 激活。顾名思义,它是 ELU 的缩放版本,在下面的公式中选择了两个缩放常数,例如在 TensorFlow 和 Pytorch 实现中。

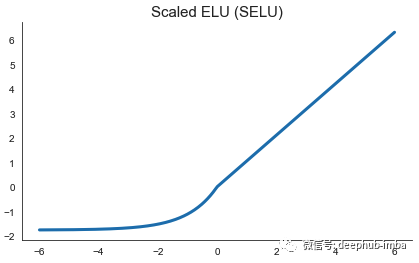
SELU 函数有一个特殊的属性。该论文的作者表明,如果正确初始化,使用线性层的前馈网络将自归一化,前提是所有隐藏层都被 SELU 激活。这意味着每一层的输出将大致具有等于 0 的平均值和等于 1 的标准偏差,这有助于防止梯度消失或爆炸问题,并允许构建深度网络。该论文在来自 UCI 机器学习库、药物发现基准甚至天文学任务的 120 多个任务上评估了这种自标准化网络,发现它们显着优于传统的前馈网络。
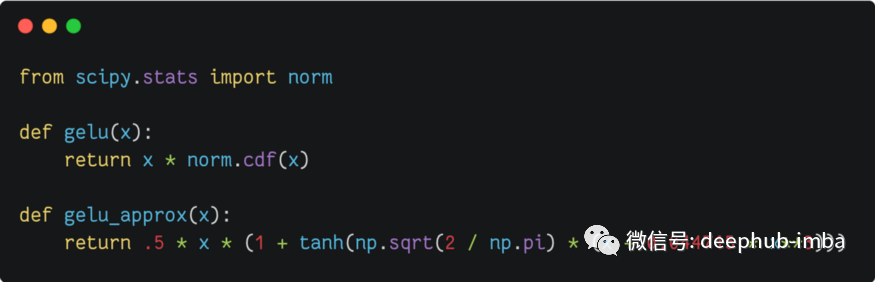
Gaussian Error Linear Unit (GELU)
Gaussian Error Linear Unit (GELU) 是 Hendrycks & Gimpel 在 2016 年的一篇论文中提出的。该函数只是将其输入与此输入处的正态分布的累积密度函数相乘。由于此计算非常慢,因此在实践中经常使用更快的近似值,仅在小数点后第四位有所不同。
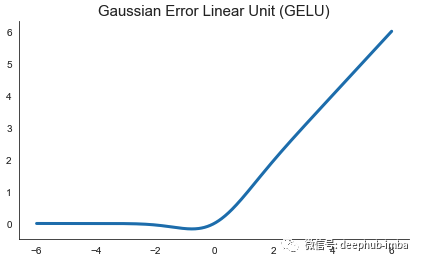
与 ReLU 系列的激活相反,GELU 根据其值对其输入进行加权,而不是根据其符号对它们进行阈值处理。作者针对 ReLU 和 ELU 函数评估了 GELU 激活,并发现所有计算机视觉、自然语言处理和语音任务的性能都有提高。
Swish
Swish 激活函数,由 Ramachandran 等人于 2017 年 Google Brain 上的发现。非常简单:它只是将输入乘以自己的 sigmoid。它的形状与 GELU 函数非常相似。

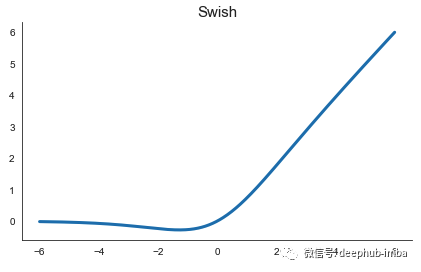
该论文的作者注意到,尽管已经提出了许多其他激活,但 ReLU 仍然是最广泛采用的,主要是由于使用新方法的收益和成本不一致。因此,他们通过简单地将 Swish 用作已针对 ReLU 优化的网络架构中的 ReLU 的替代品来评估 Swish。他们发现了显着的性能提升,并建议使用 Swish 作为 ReLU 的替代品。
Swish的论文还包含了一个有趣的讨论,关于什么激活函数是好的。作者指出,Swish工作得如此出色的原因是它的上无界,下有界,非单调,平滑。你可能已经注意到GELU也具有所有这些性质,我们稍后将讨论的最后一次激活函数也是这样。看来这就是激活研究的发展方向。
Mish
Mish 激活是迄今为止讨论中的最新的发现。它是由 Misra 在 2019 年的一篇论文中提出的。Mish 受到 Swish 的启发,并已被证明在各种计算机视觉任务中的表现都优于它。
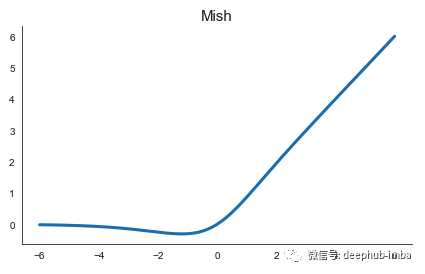
引用原始论文,Mish 是“通过系统分析和实验发现并使 Swish 更加有效”。就目前来说Mish可能是 最好的激活函数,但请原始论文仅在计算机视觉任务上对其进行了测试。
最后怎么选择激活函数?
Geron 在他的精彩著作《使用 Scikit-Learn 和 TensorFlow 进行机器学习实践》中陈述了以下一般规则:
SELU > ELU > Leaky ReLU > ReLU
但是有一些问题。如果网络的体系结构阻止自归一化,那么 ELU 可能是比 SELU 更好的选择。如果速度很重要,Leaky ReLU 将是比慢很多的 ELU 更好的选择。但是,这本书中没有讨论最近提出的激活。
一位前 Google 员工给出的第一条建议是用 Swish 替换 ReLU。它并没有改变游戏规则,但尽管如此,性能还是有所提高。
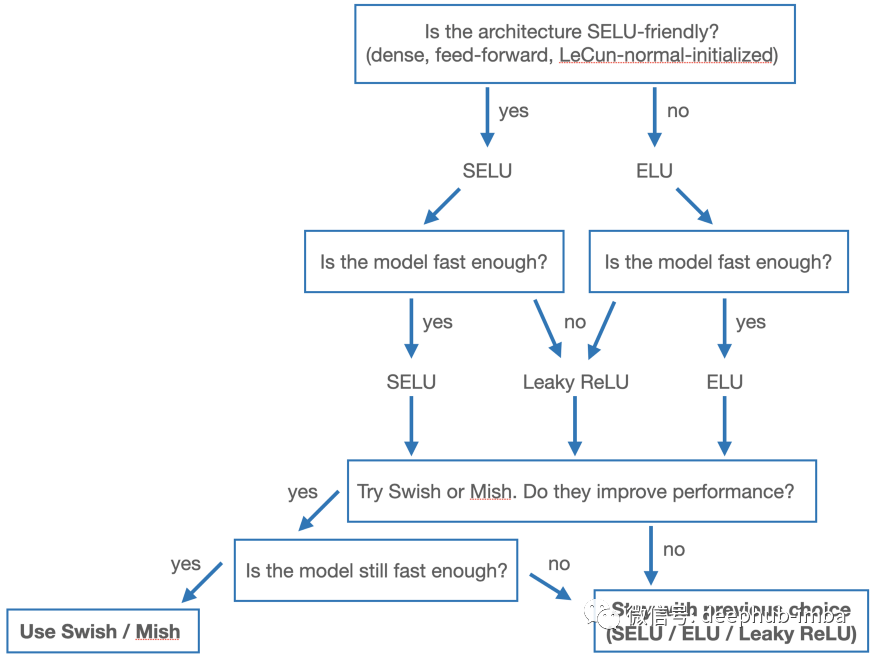
基于这一点和我的其他经验,我会在选择激活函数时建议以下主观决策树,假设架构的其余部分是固定的。
引用
- Geron A., 2019, 2nd edition, Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems
- deepdrive.pl’s image classification course (in Polish)
- 2016, Dan Hendrycks & Kevin Gimpel, Gaussian Error Linear Units (GELUs)
- 2017, Prajit Ramachandran, Barret Zoph, Quoc V. Le, Swish: a Self-Gated Activation Function
- 2017, Günter Klambauer, Thomas Unterthiner, Andreas Mayr, Sepp Hochreiter, Self-Normalizing Neural Networks
- 2019, Diganta Misra, Mish: A Self Regularized Non-Monotonic Activation Function
作者:Michał Oleszak