
简介
- 介绍计算框架对java开发的重要性
- 介绍flink的架构
- 介绍flink的编程模型:DataStream、DataSet、Table API、SQL
- 介绍flink的部署
计算框架
每个Java开发一定要懂至少一个流行的计算框架,因为现在的数据量越来越大,光靠数据库或者手写代码去实现难度已经越来越大,不仅涉及到资源调度,还要考虑分布式,并且还要考虑高可用、容错等等,因此我们需要借助现有的分布式计算框架来实现我们大规模分布式计算的目的。不仅能简化我们的程序设计,使我们更关注业务,并且也能防止重复造轮子。
随着数据规模的不断增加,相应的计算框架也在不停的升级迭代中,计算框架经历了如下几个阶段:
- 第一代批量计算框架MapReduce,计算模型检查,延迟高。
- 第二代流式计算Storm、Spark,实时计算的控制有限,内存要求高。
- 第三代批流一体计算Flink,批处理和流处理统一结合,控制灵活。 flink可以说是继承了历代计算引擎的各种优点,抛弃各种缺点而造就的高性能实时计算框架,这也是目前flink框架比对火热的原因。本文将主要介绍flink各个基本概念,让开发能直接上手使用。
Flink架构
flink适应场景
- 事件驱动应用
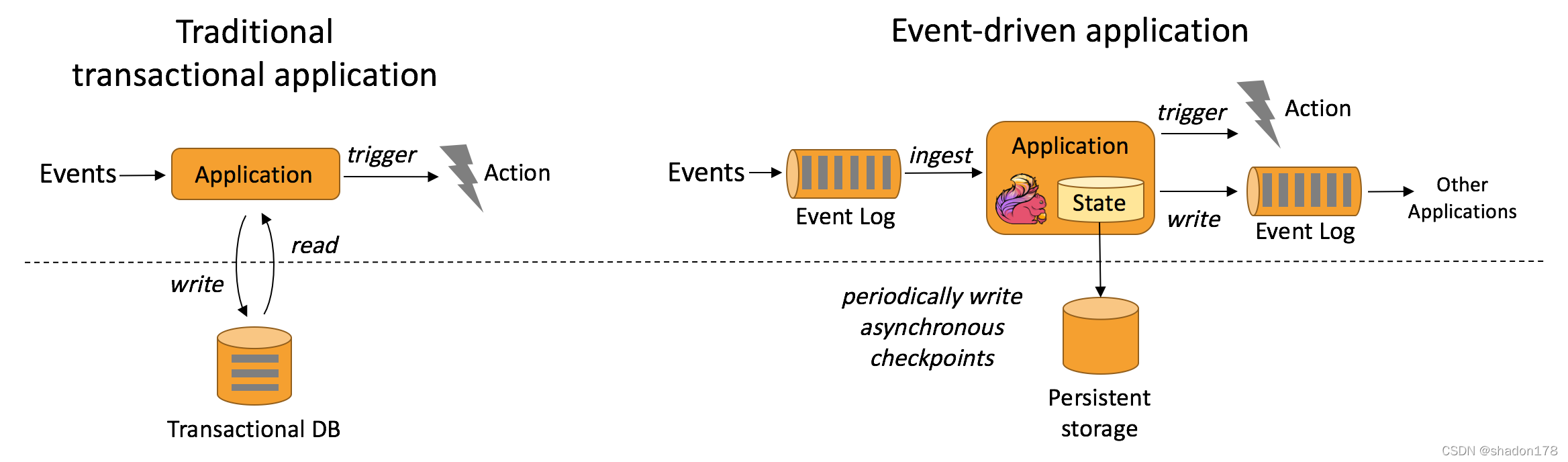 根据到来的数据和事件条件触发计算的流程操作。
根据到来的数据和事件条件触发计算的流程操作。 - 流批分析:
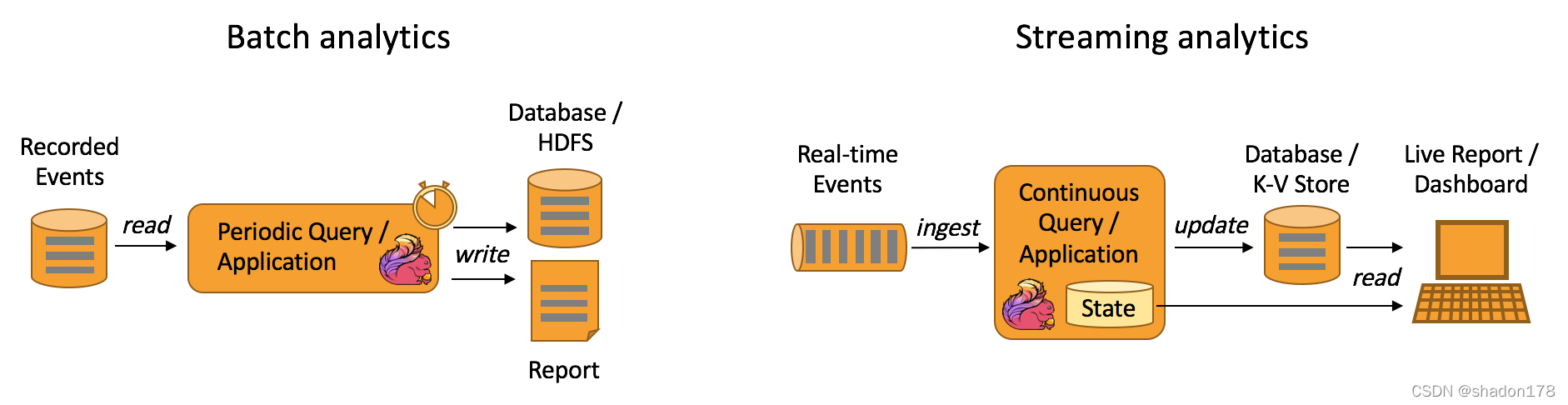 流式计算和批处理
流式计算和批处理 - 数据管道 & ETL
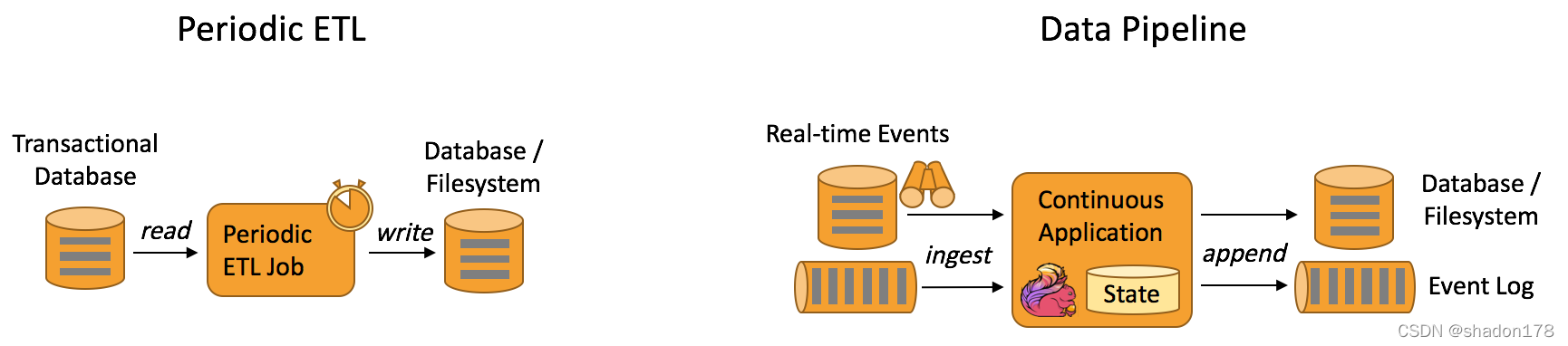 也是我们常说的ETL工具,也是目前我做数据抽取经常用到的工具。
也是我们常说的ETL工具,也是目前我做数据抽取经常用到的工具。
集群架构
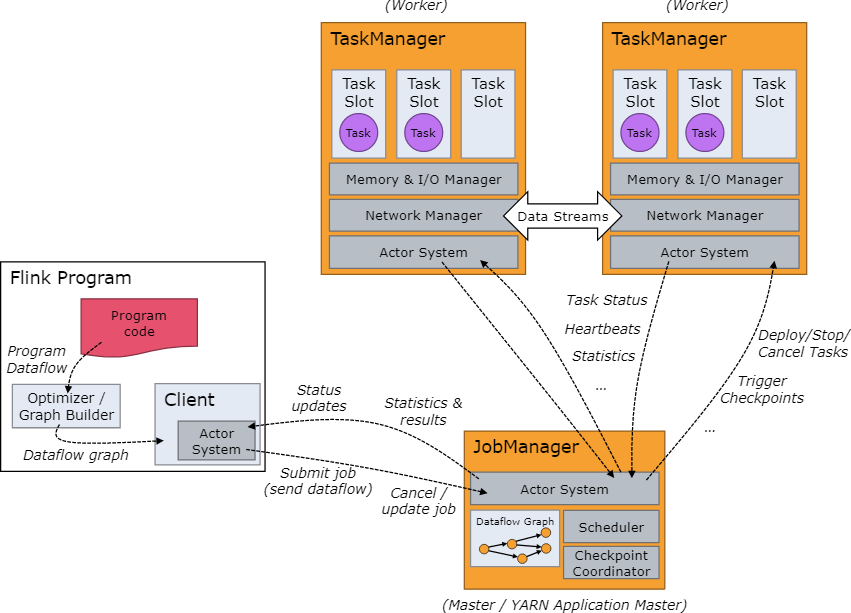
JobManager
Flink集群由一个JobManager进程和多个TaskManager进程组成。实际运行的JobManager只有一个,在高可用的环境下,可以存在多个JobManager,但是只有一个leader角色,其他都处于standby状态,待leader宕机时再转变成leader角色继续服务。
JobManager负责任务的划分、资源调度、分布式的协调等。其中又有3给主要组件组成:
- ResourceManager ResourceManager 负责 Flink 集群中的资源调度、回收、分配 - 它管理任务槽(task slots),这是 Flink 集群中资源调度的单位,后面会详细讲解任务槽的概念。
- Dispatcher Dispatcher 用来接受客户端提叫过来的计算程序,并为每个提交的作业启动一个新的 JobMaster。此外,还提供一个web界面用于查看执行情况、日志、监控指标等。
- JobMaster JobMaster 负责管理单个任务集(JobGraph)的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。
TaskManager
TaskManager负责执行作业中的任务,并且缓存数据以及与其他taskmanger交换数据。
在TaskManager 中资源调度的最小单位是槽,TaskManager 中槽的数量表示并发处理任务的数量,请注意一个槽中可以执行多个算子。.
任务和算子链
多个算子操作可以形成算子链,例如:map().keyBy().windows().apply().sink(),有5个算子,其中map、keyBy().windows().apply()、sink形成3个任务,每个任务由单独的线程执行,在执行过程中又将任务划分为具体的子任务,每个子任务负责部分数据的执行。如图所示: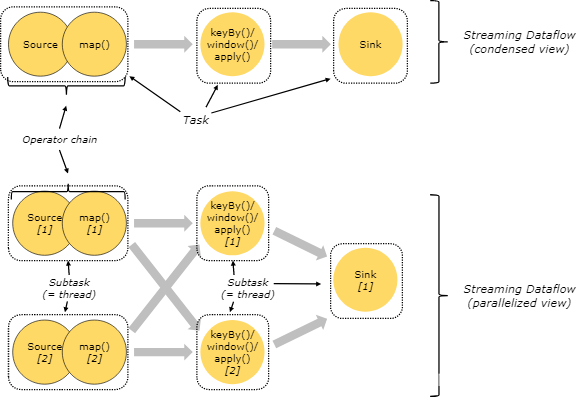
图的上半部分为任务视角,下半部分为进程视角,请仔细揣摩。
槽和资源划分
每个TaskManager都是一个 JVM 进程,可以在单独的线程中执行一个或多个子任务。为了控制一个 TaskManager 中接受多少个 任务,就有了所谓的槽。
每个槽平分TaskManager的托管内存,注意槽只分配给某个作业的任务,因此不同的作业任务执行时不会共用槽,也就形成了作业之间的资源隔离,但是一个作业的任务是可以公用槽的。槽只是隔离了内存使用,并没有隔离CPU资源。
通过调整槽的数量,用户可以定义子任务如何互相隔离。如果每个 TaskManager 有一个槽,这意味着每个 task 组都在单独的 JVM 中运行。更多个槽意味着更多子任务共享同一 JVM。同一 JVM 中的 task 共享 TCP 连接(通过多路复用)和心跳信息。它们还可以共享数据集和数据结构,从而减少了每个 task 的开销。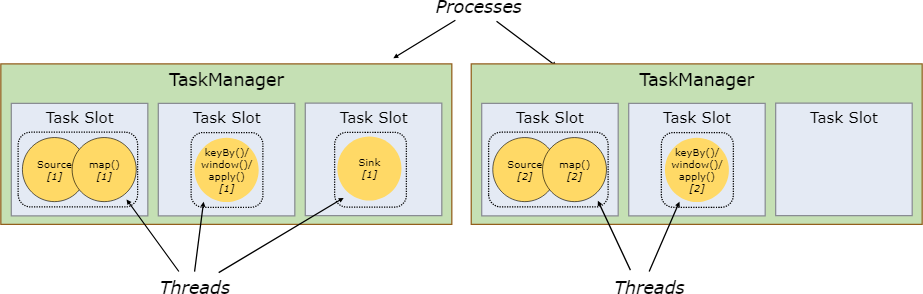
默认情况下,Flink 允许子任务共享槽,即便它们是不同的任务的子任务,但是必须是同一个作业。可以将整个作业的子任务都放入到一个槽中执行。允许槽共享有两个主要优点:
Flink 集群所需的槽和作业中使用的最大并行度恰好一样。无需计算程序总共包含多少个任务(具有不同并行度)。
容易获得更好的资源利用。如果没有槽共享,非密集 子任务(source/map())将阻塞和密集型 子任务(window) 一样多的资源。通过槽的共享,我们示例中的基本并行度从 2 增加到 6,可以充分利用分配的资源,同时确保繁重的子任务在 TaskManager 之间公平分配。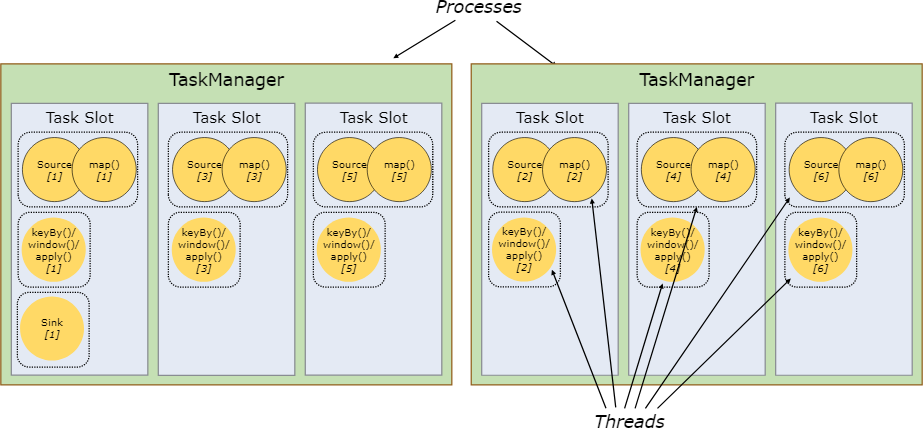
Flink集群环境(flink on yarn)
flink有多种集群的执行环境,大家必须根据不同的任务需要,选择适当的集群环境进行执行。
Flink Session 集群
集群生命周期:在 Flink Session 集群中,客户端连接到一个预先存在的、长期运行的集群,该集群可以接受多个作业提交。即使所有作业完成后,集群(和 JobManager)仍将继续运行直到手动停止 session 为止。因此,Flink Session 集群的寿命不受任何 Flink 作业寿命的约束。
资源隔离:TaskManager槽由 ResourceManager 在提交作业时分配,并在作业完成时释放。由于所有作业都共享同一集群,因此在集群资源方面存在一些竞争 — 例如提交工作阶段的网络带宽。此共享设置的局限性在于,如果 TaskManager 崩溃,则在此 TaskManager 上运行 task 的所有作业都将失败;类似的,如果 JobManager 上发生一些致命错误,它将影响集群中正在运行的所有作业。
其他注意事项:拥有一个预先存在的集群可以节省大量时间申请资源和启动 TaskManager。有种场景很重要,作业执行时间短并且启动时间长会对端到端的用户体验产生负面的影响 — 就像对简短查询的交互式分析一样,希望作业可以使用现有资源快速执行计算。
任务提交方式:
./bin/flink run -t yarn-session \
-Dyarn.application.id=application_XXXX_YY \
./examples/streaming/TopSpeedWindowing.jar
Flink pre-Job 集群
集群生命周期:在 Flink Job 集群中,可用的集群管理器(例如 YARN)用于为每个提交的作业启动一个集群,并且该集群仅可用于该作业。在这里,客户端首先从集群管理器请求资源启动 JobManager,然后将作业提交给在这个进程中运行的 Dispatcher。然后根据作业的资源请求惰性的分配 TaskManager。一旦作业完成,Flink Job 集群将被拆除。
资源隔离:JobManager 中的致命错误仅影响在 Flink Job 集群中运行的一个作业。
其他注意事项:由于 ResourceManager 必须应用并等待外部资源管理组件来启动 TaskManager 进程和分配资源,因此 Flink Job 集群更适合长期运行、具有高稳定性要求且对较长的启动时间不敏感的大型作业。
以前,Flink Job 集群也被称为 job (or per-job) 模式下的 Flink 集群。
Kubernetes 不支持 Flink Job 集群。
./bin/flink run -t yarn-per-job --detached ./examples/streaming/TopSpeedWindowing.jar
detached 参数表明任务一旦提交,客户端进程就终止了,集群会继续负责执行。
detached模型下如果需要继续查询任务执行情况,可以使用如下命令:
# 查询集群上运行的任务
./bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
# 取消正在运行的任务
./bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>
Flink Application 集群
集群生命周期:Flink Application 集群是专用的 Flink 集群,仅从 Flink 应用程序执行作业,并且 main()方法在集群上而不是客户端上运行。提交作业是一个单步骤过程:不需要先启动 Flink 集群,然后将作业提交到现有的 session 集群;相反,将应用程序逻辑和依赖打包成一个可执行的作业 JAR 中,并且由flink集群(ApplicationClusterEntryPoint)负责调用 main()方法来提取 JobGraph。例如,这允许你像在 Kubernetes 上部署任何其他应用程序一样部署 Flink 应用程序。因此,Flink Application 集群的寿命与 Flink 应用程序的寿命有关。
资源隔离:在 Flink Application 集群中,ResourceManager 和 Dispatcher 作用于单个的 Flink 应用程序,相比于 Flink Session 集群,它提供了更好的隔离。
Flink Job 集群可以看做是 Flink Application 集群”客户端运行“的替代方案。
任务提交方式:
./bin/flink run-application -t yarn-application ./examples/streaming/TopSpeedWindowing.jar
Flink的编程模型
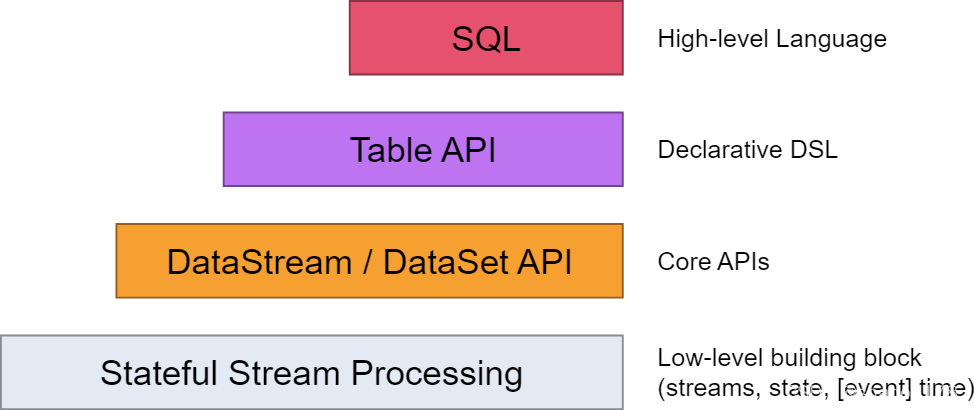
我们常用的Flink编程API有DataStream、DataSet、Table、SQL,每种API的抽象级别如图所示。最底层的Stateful Stream Processing是flink内部核心API,一般我们不会用到。之上就是我们常用的DataStream和DataSet API,分别代表流式和批处理的API,但随着Flink的批流一体,已经基本都是用DataStream来代替DataSet来使用了。在此之上就是Table API,可以像操作数据库表一样来进行关联、统计、聚合等操作。最上层就是我们比较熟悉的SQL语句了,可以用简单的SQL语句完成数据的处理操作。
DataStream
常用算子
1、map
DataStream → DataStream
简单的转换操作,将一个输入转换成一个输出。
DataStream<Integer> dataStream =//...
dataStream.map(newMapFunction<Integer,Integer>(){@OverridepublicIntegermap(Integer value)throwsException{return2* value;}});
2、flatMap
DataStream → DataStream
简单的转换操作,将一个输入转换成0个或多个输出。
dataStream.flatMap(newFlatMapFunction<String,String>(){@OverridepublicvoidflatMap(String value,Collector<String> out)throwsException{for(String word: value.split(" ")){
out.collect(word);}}});
3、Filter
DataStream → DataStream
过滤操作,只保留返回true的数据。
dataStream.filter(newFilterFunction<Integer>(){@Overridepublicbooleanfilter(Integer value)throwsException{return value !=0;}});
4、KeyBy
DataStream → KeyedStream
分区操作,根据指定的函数对所有数据进行分区,函数返回值相同的数据归为一个分区。
注意:由于结果取hash进行分区,因此key必须要实现hashcode,且不能使用数组。
dataStream.keyBy(value -> value.getSomeKey());
dataStream.keyBy(value -> value.f0);
5、Reduce
KeyedStream → DataStream
根据指定的操作将多个数据项合并成一个。
keyedStream.reduce(newReduceFunction<Integer>(){@OverridepublicIntegerreduce(Integer value1,Integer value2)throwsException{return value1 + value2;}});
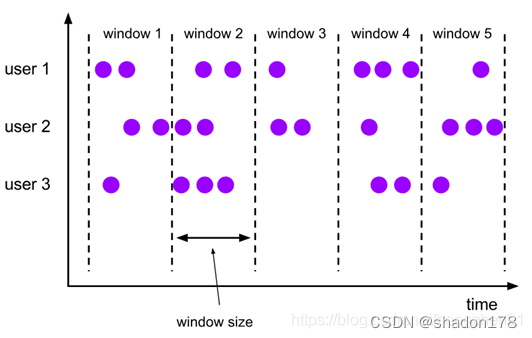
6、Window
KeyedStream → WindowedStream
将已经分区的数据,根据时间窗口再进行划分。例如:根据第一个字段进行分区,然后根据数据到来时间,每隔5秒形成一个子分区,代码如下:
dataStream
.keyBy(value -> value.f0).window(TumblingEventTimeWindows.of(Time.seconds(5)));
7、WindowAll
DataStream → AllWindowedStream
类似window操作,但是不需要提前分区,可以作用于整个数据流(DataStream)上
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)));
8、Window Apply
WindowedStream → DataStream
AllWindowedStream → DataStream
对每个时间分区进行具体操作,例如计算每个时间分区内的总和:
windowedStream.apply(newWindowFunction<Tuple2<String,Integer>,Integer,Tuple,Window>(){publicvoid apply (Tuple tuple,Window window,Iterable<Tuple2<String,Integer>> values,Collector<Integer> out)throwsException{int sum =0;for(value t: values){
sum += t.f1;}
out.collect (newInteger(sum));}});// applying an AllWindowFunction on non-keyed window stream
allWindowedStream.apply (newAllWindowFunction<Tuple2<String,Integer>,Integer,Window>(){publicvoid apply (Window window,Iterable<Tuple2<String,Integer>> values,Collector<Integer> out)throwsException{int sum =0;for(value t: values){
sum += t.f1;}
out.collect (newInteger(sum));}});
参数介绍:
- tuple: 代表上一步的key
- windows: 代表当前窗口
- values: 代表当前窗口内的所有数据
- out: 用于输出数据
9、WindowReduce
WindowedStream → DataStream
在每个时间窗口分区上进行reduce操作,也就是合并操作,例如求和、取平均等等操作。
windowedStream.reduce (newReduceFunction<Tuple2<String,Integer>>(){publicTuple2<String,Integer>reduce(Tuple2<String,Integer> value1,Tuple2<String,Integer> value2)throwsException{returnnewTuple2<String,Integer>(value1.f0, value1.f1 + value2.f1);}});
10、Union
DataStream* → DataStream
将所有流的数据合并起来,形成一个流。如果相同的流合并会导致数据重复一遍,只能对相同类型数据的流进行合并。
dataStream.union(otherStream1, otherStream2,...);
11、Window Join
DataStream,DataStream → DataStream
Join two data streams on a given key and a common window.
将2个流根据指定条件join起来,类似于数据库中2个表的join操作,然后再形成时间窗口:
dataStream.join(otherStream).where(<key selector>).equalTo(<key selector>).window(TumblingEventTimeWindows.of(Time.seconds(3))).apply (newJoinFunction(){...});
12、Interval Join
KeyedStream,KeyedStream → DataStream
将2给KeyedStream流用相同的key在指定的时间间隔内join起来,2个流的时间间隔满足条件:
e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound.
// join后的流满足条件:// key1 == key2 && leftStream.Timestamp - 2s < rightStream.Timestamp < leftStream.Timestamp + 2s
leftStream.intervalJoin(rightStream).between(Time.milliseconds(-2),Time.milliseconds(2))// 指定时间误差上限和下限.upperBoundExclusive(true)// 可选参数:不包含上限.lowerBoundExclusive(true)// 可选参数:不包含下限.process(newIntervalJoinFunction(){...});
13、Window CoGroup
DataStream,DataStream → DataStream
与join类似,但是它在一个流中没有找到与另一个匹配的数据还是会输出。
dataStream.coGroup(otherStream).where(0).equalTo(1).window(TumblingEventTimeWindows.of(Time.seconds(3))).apply (newCoGroupFunction(){...});
14、Connect
DataStream,DataStream → ConnectedStream
connect类似于union操作,将2给流的数据合并,但是union只能对同类型的流进行操作,而connect可以对不同类型的流进行合并。此外,可以在2给流之间共享状态。
DataStream<Integer> someStream =//...DataStream<String> otherStream =//...ConnectedStreams<Integer,String> connectedStreams = someStream.connect(otherStream);
15、CoMap, CoFlatMap
ConnectedStream → DataStream
类似map和flatMap操作,但是只能作用于ConnectedStream上,也即是在执行过connect的流上操作。
connectedStreams.map(new CoMapFunction<Integer, String, Boolean>(){
@Override
public Boolean map1(Integer value){ // 第一个流的map操作
returntrue;}
@Override
public Boolean map2(String value){ // 第二个流的map操作
returnfalse;}});
connectedStreams.flatMap(new CoFlatMapFunction<Integer, String, String>(){
@Override
public void flatMap1(Integer value, Collector<String> out){ // 第一个流的flatMap操作
out.collect(value.toString());}
@Override
public void flatMap2(String value, Collector<String> out){ // 第二个流的flatMap操作
for(String word: value.split(" ")){
out.collect(word);}}});
16、Iterate
DataStream → IterativeStream → ConnectedStream #
迭代计算,多用于图计算、机器学习等特殊领域。
// 定义一个迭代流IterativeStream<Long> iteration = initialStream.iterate();// 定义每个迭代的具体操作,每个迭代都会执行DataStream<Long> iterationBody = iteration.map (/*do something*/);// 定义继续迭代的数据需要满足的条件,满足条件的数据会继续下一次迭代。DataStream<Long> feedback = iterationBody.filter(newFilterFunction<Long>(){@Overridepublicbooleanfilter(Long value)throwsException{return value >0;}});// 指定继续迭代的条件
iteration.closeWith(feedback);// 继续处理跳过迭代的数据DataStream<Long> output = iterationBody.filter(newFilterFunction<Long>(){@Overridepublicbooleanfilter(Long value)throwsException{return value <=0;}});
在实现特殊算法的时候可能需要用到迭代计算,具体细节可以参考:
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/dataset/iterations/
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/overview/#iterations
这里暂不具体介绍迭代计算,感兴趣的同学可以百度一下。
DataSet
Table API
SQL
参考文档
Flink官方文档
版权归原作者 shadon178 所有, 如有侵权,请联系我们删除。