
前言:
💞💞大家好,我是书生♡,今天主要和大家分享一下什么是海豚调度?怎么使用可以将海豚调度应用到我们的项目开发中?希望对大家有所帮助。
💞💞代码是你的画笔,创新是你的画布,用它们绘出属于你的精彩世界,不断挑战,无限可能!
个人主页⭐: 书生♡
gitee主页🙋♂:闲客
专栏主页💞:大数据开发
博客领域💥:大数据开发,java编程,前端,算法,Python
写作风格💞:超前知识点,干货,思路讲解,通俗易懂
支持博主💖:关注⭐,点赞、收藏⭐、留言💬
目录
1. 什么是海豚调度
- Apache DolphinScheduler(海豚调度)是一个分布式、去中心化、易扩展的可视化DAG工作流任务调度系统,致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
- Apache DolphinScheduler 旨在解决复杂的大数据任务依赖关系,并为应用程序提供数据和各种 OPS 编排中的关系。 解决数据研发ETL依赖错综复杂,无法监控任务健康状态的问题。 DolphinScheduler 以 DAG(Directed Acyclic Graph,DAG)流式方式组装任务,可以及时监控任务的执行状态,支持重试、指定节点恢复失败、暂停、恢复、终止任务等操作。

2. 海豚调度的作用
解决大规模数据处理流程中的复杂依赖关系和高效执行问题。
Apache DolphinScheduler致力于简化数据处理流程的运维工作,帮助提升其数据驱动业务的效率和效果。适用于大规模数据处理与分析场景。
3. 海豚调度的优点
- 分布式架构:
DolphinScheduler采用分布式去中心化的设计,具有高可用性和水平扩展能力,可以在大型集群中运行并调度成千上万个任务。
- 可视化 DAG 工作流设计且简单易用:
提供了可视化的界面来定义和编排数据处理流程,通过拖拽方式构建有向无环图(DAG),清晰地表示任务之间的依赖关系。
用户可以通过简单直观的操作界面创建、编辑、发布和监控工作流任务,同时支持自定义插件机制,能够方便地添加对新类型任务的支持。
- 多租户和权限管理:
支持多租户模式,可以为不同团队或项目分配资源,并提供详细的权限控制,确保安全可靠的数据处理流程。
- 容错与恢复机制:
采用checkpoint和重试策略,确保在出现故障时能够自动恢复任务执行,提高系统的稳定性和可靠性。
- 多种任务类型支持:
可以调度包括但不限于SQL、Shell、Python、Spark、Hive等多种类型的任务,满足不同场景下的大数据处理需求。
- 强大的调度功能:
支持定时调度、依赖调度以及手动触发任务,还具备动态参数传递、跨工作流依赖、邮件告警等功能。
- 开箱即用:
配置简单,用户无需过多关注底层细节即可快速部署并开始使用。
4. Dolphin Scheduler 的使用
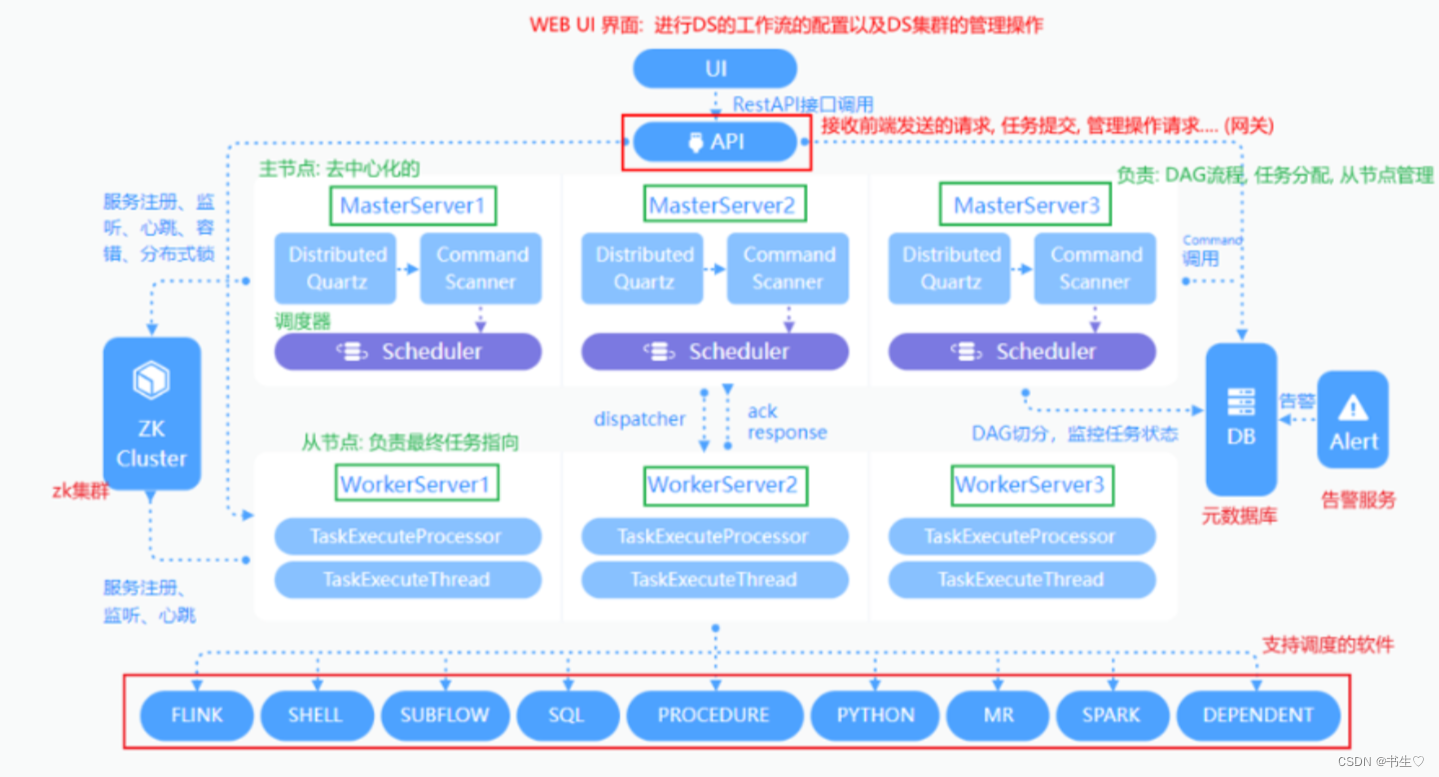
4.1 Dolphin Scheduler 的架构
具体流程:
- 首先在DS的web页面进行工作流的配置操作,将我们的任务添加进来,将其提交执行。
- 通过接口的调用,接收到被发送的请求,接受任务。
- 选择一台主节点的Master 用来进行任务的分配(底层最终是有对应scheduler具体完成,Master只是负责管理分配)
- 将对应的任务交给WokerServer 去执行,执行过程中worker对应有一个logger服务进行日志的记录。
- 当执行完成后, 通知Master, Master进行状态变更。
注意:在整个过程中,告警服务 Alert会一直进行实时的监控,一旦出现错误,会及时的反馈。
4.2 启动DS服务
首先要进入到安装了DS的目录下面,执行在bin目录下的启动脚本。
cd /export/server/dolphinscheduler/./bin/start-all.sh
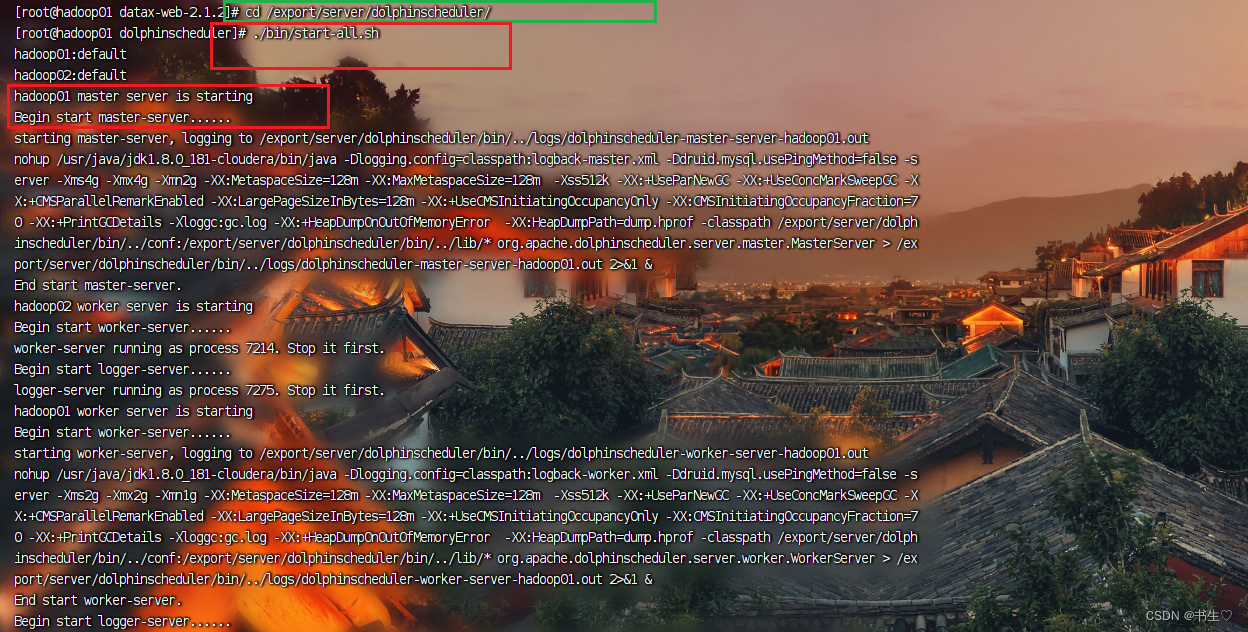
我们怎么确定他一定启动成功了呢?
通过jps查看服务是否真的启动成功!!!!
如果下面几个服务全部出现就说明启动成功了。
jps

DS web页面访问地址: http://192.168.88.80:12345/dolphinscheduler/ui/view/login/index.html
进入之后就是这个页面了。
4.3 DS的安全中心
安全中心下面,这么多服务都是干嘛的呢?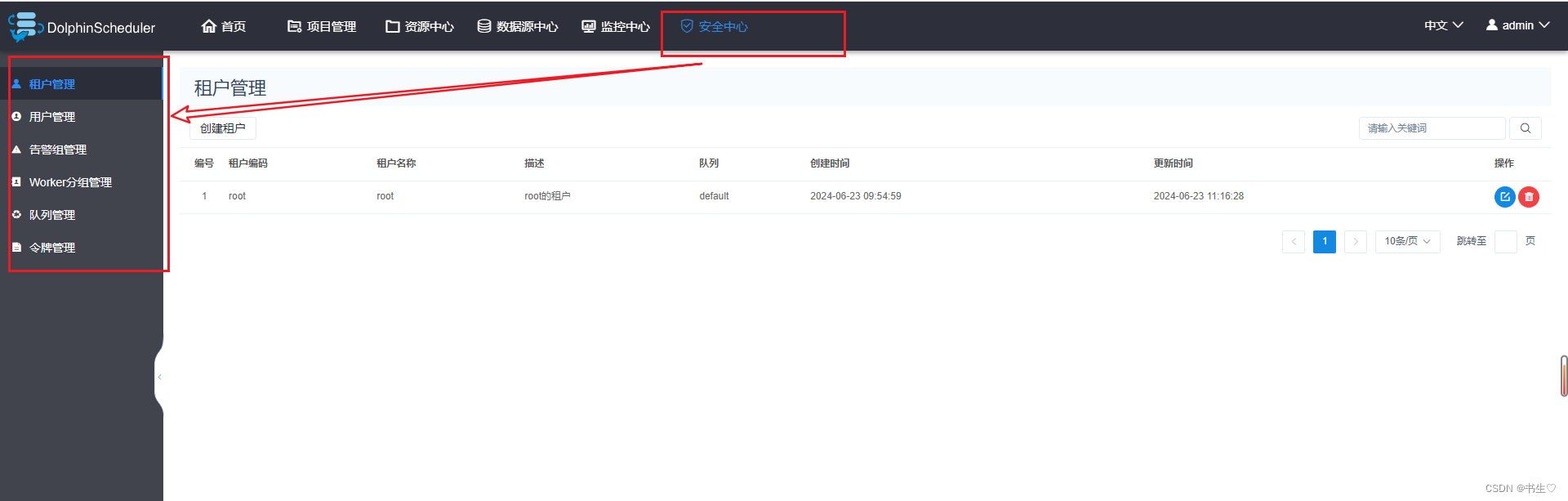
- 租户管理 作用:当DS操作的时候,采用什么身份去操作。这个就是由租户决定的。
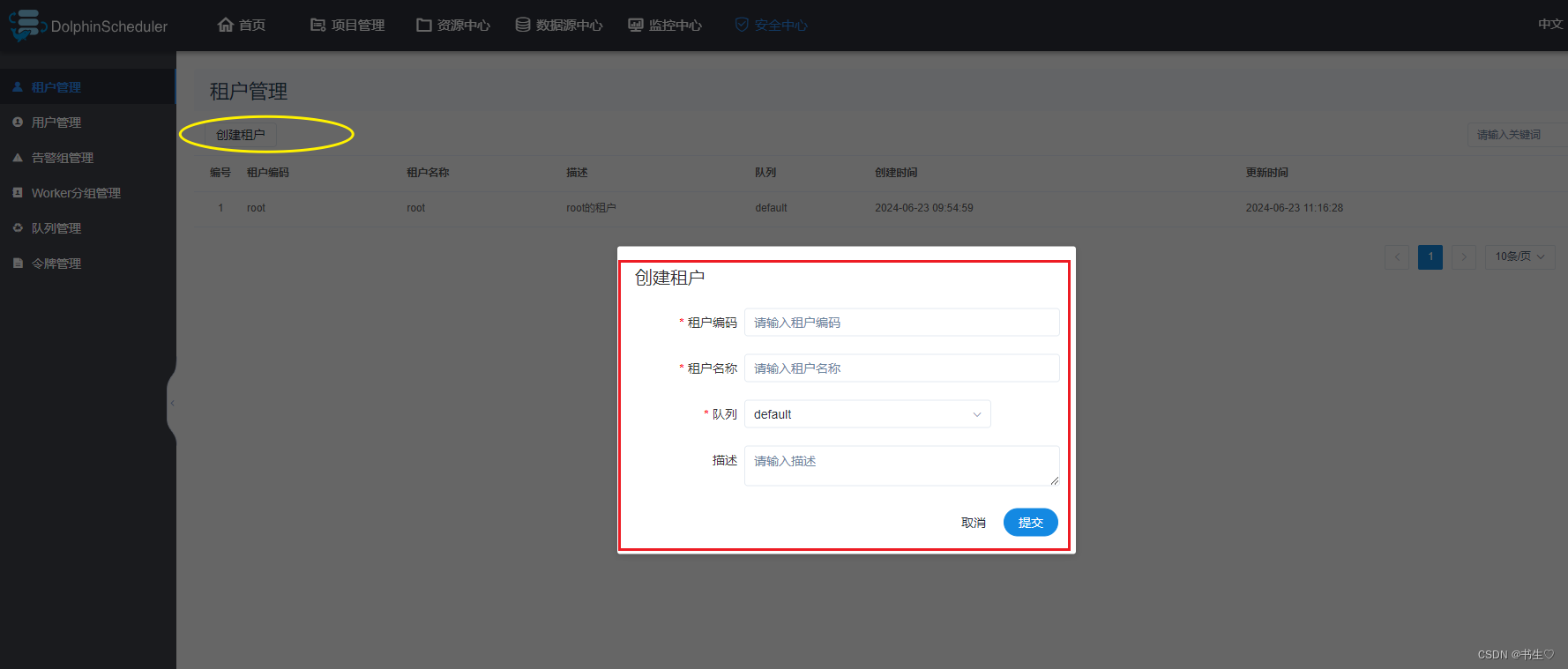
- 队列管理 当任务通过DS提交到资源队列,将任务提交到哪一个队列中。就是根据选择的队列决定的。
注意:此名称的设置,要和目标资源队列名称一致。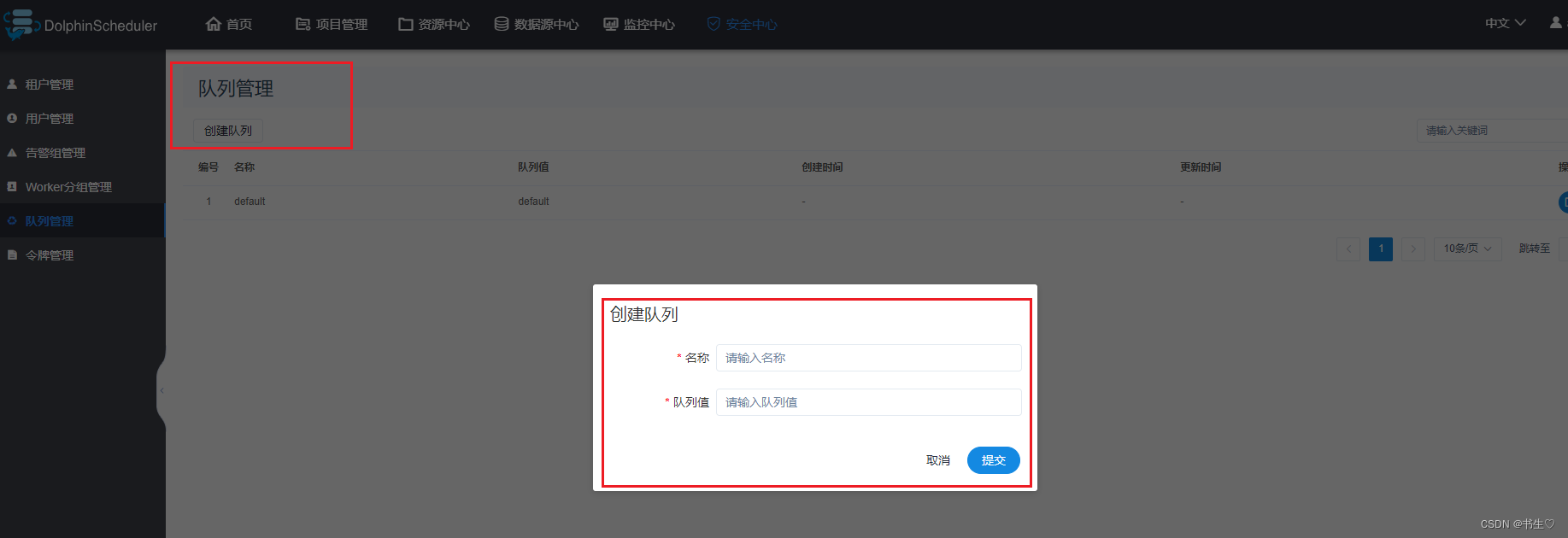
- 用户管理 这个是登录DS的用户账户,一般有一个默认的admin的权限账户。也可以添加用户账户来登录DS。
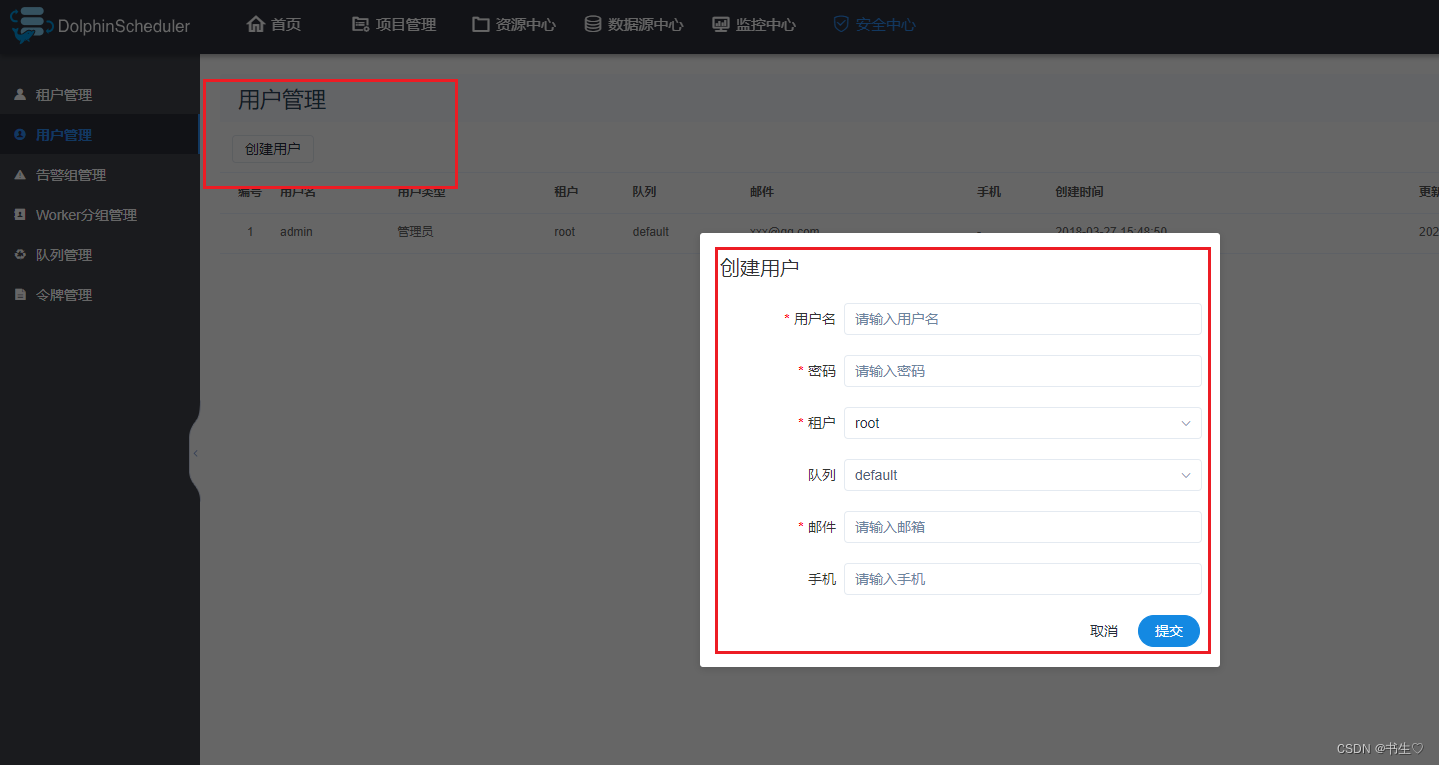
- 告警服务 发生警告的时候,采用什么方式。
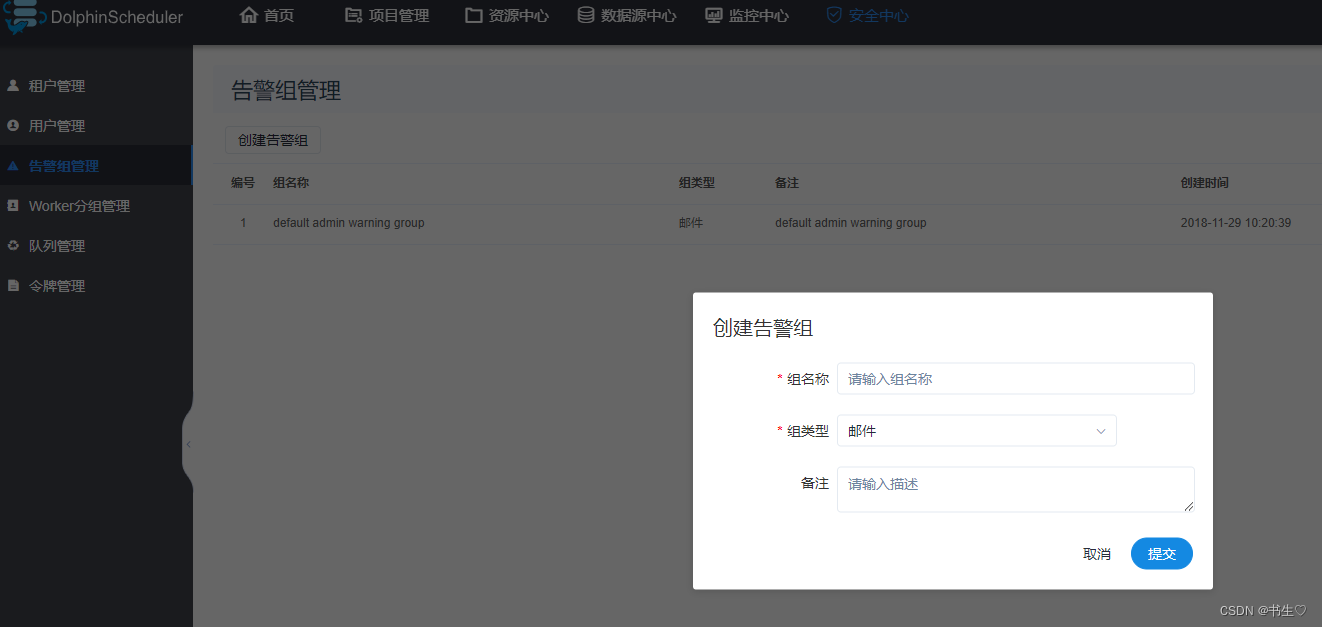
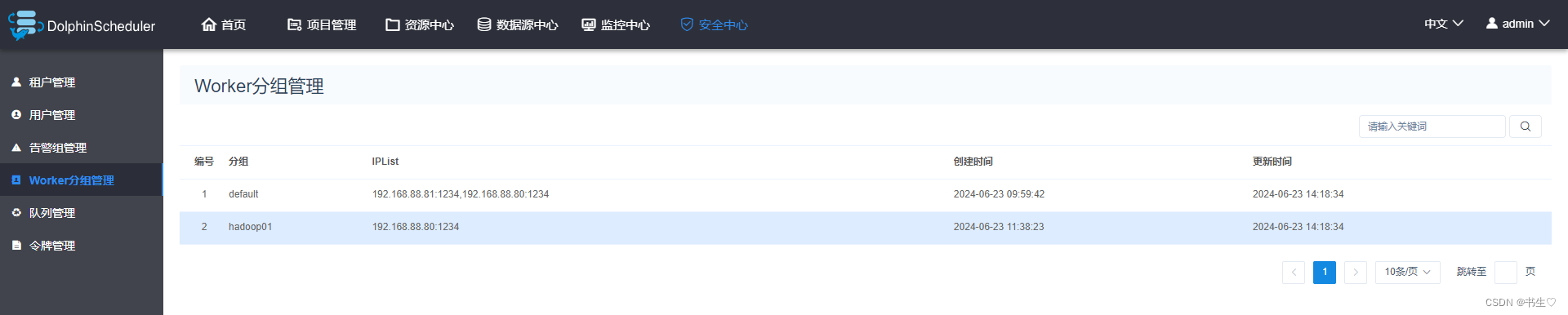
- worker 分组 任务最终是由worker节点执行的?由哪个worker执行取决你选择哪个节点。
4.4 项目调度练习
需求:我们想要先创建一个 root目录下的 aa/bb 文件夹 ,然后在 aa/bb文件夹下面创建一个txt文件。
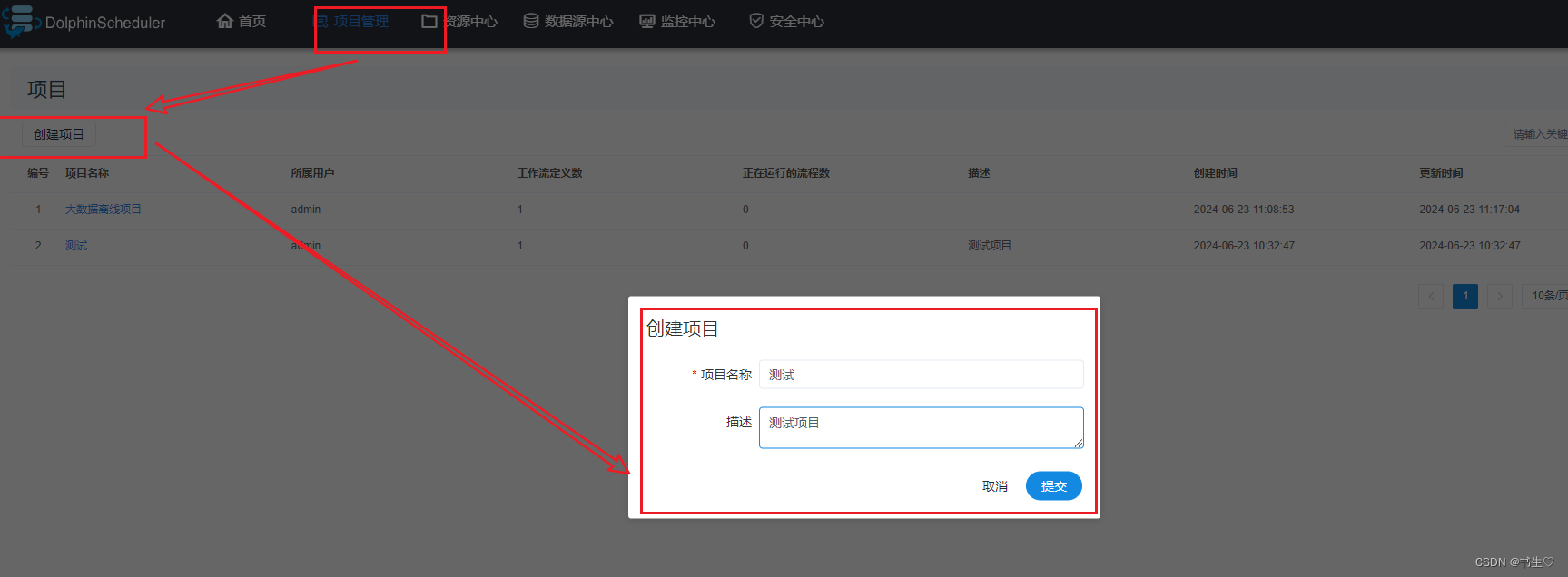
- 配置项目名称,告诉我们这个操作在哪个项目下。 点击项目管理。点击添加项目,写入项目名称和描述。
 2.创建工作流 先点击项目管理,直接进入到项目中。
2.创建工作流 先点击项目管理,直接进入到项目中。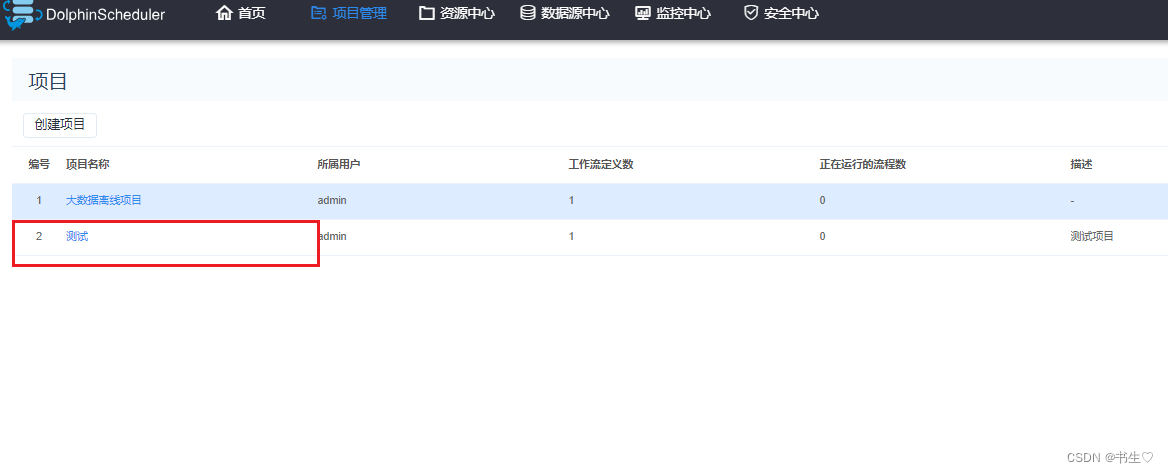
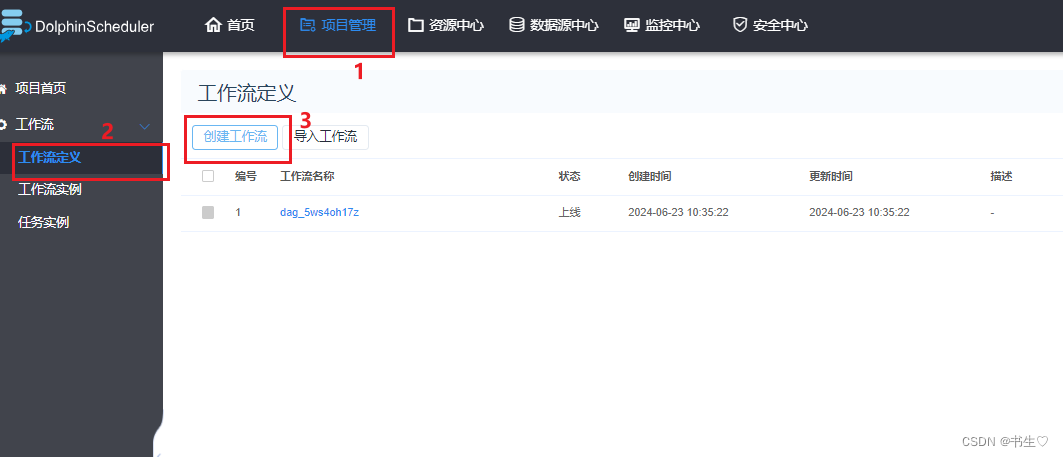
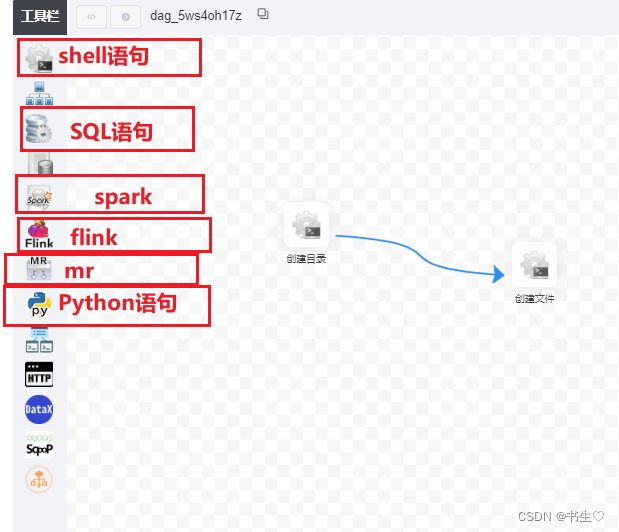
我们要先从左边拖拽处第一个 shell语句。
创建目录节点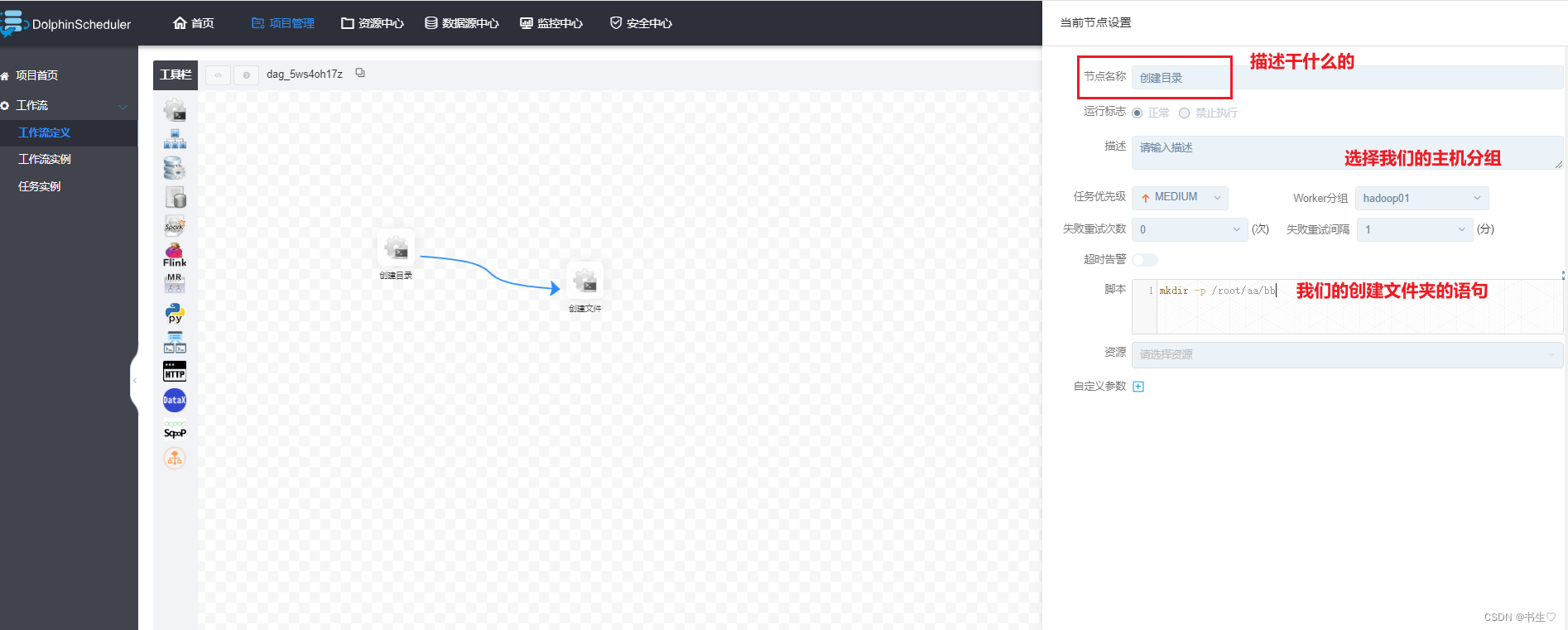
创建文件节点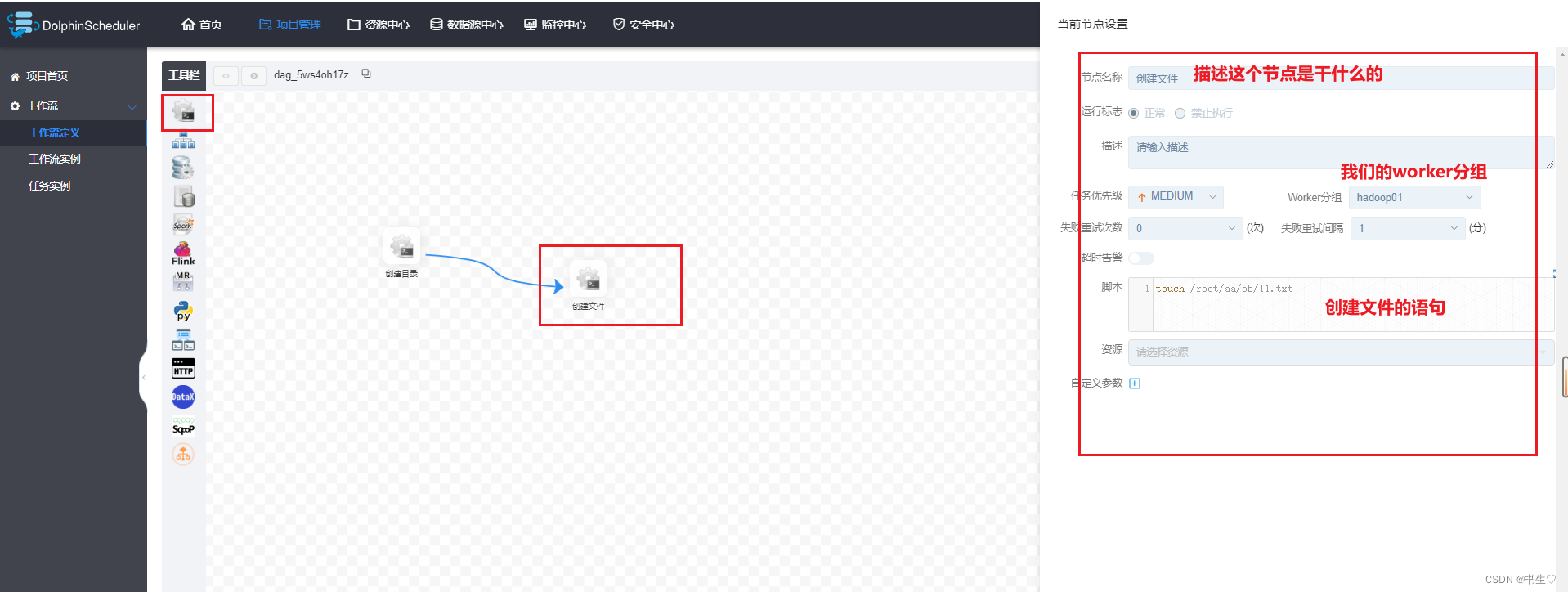
点击右上角了直线,将两个节点连接起来。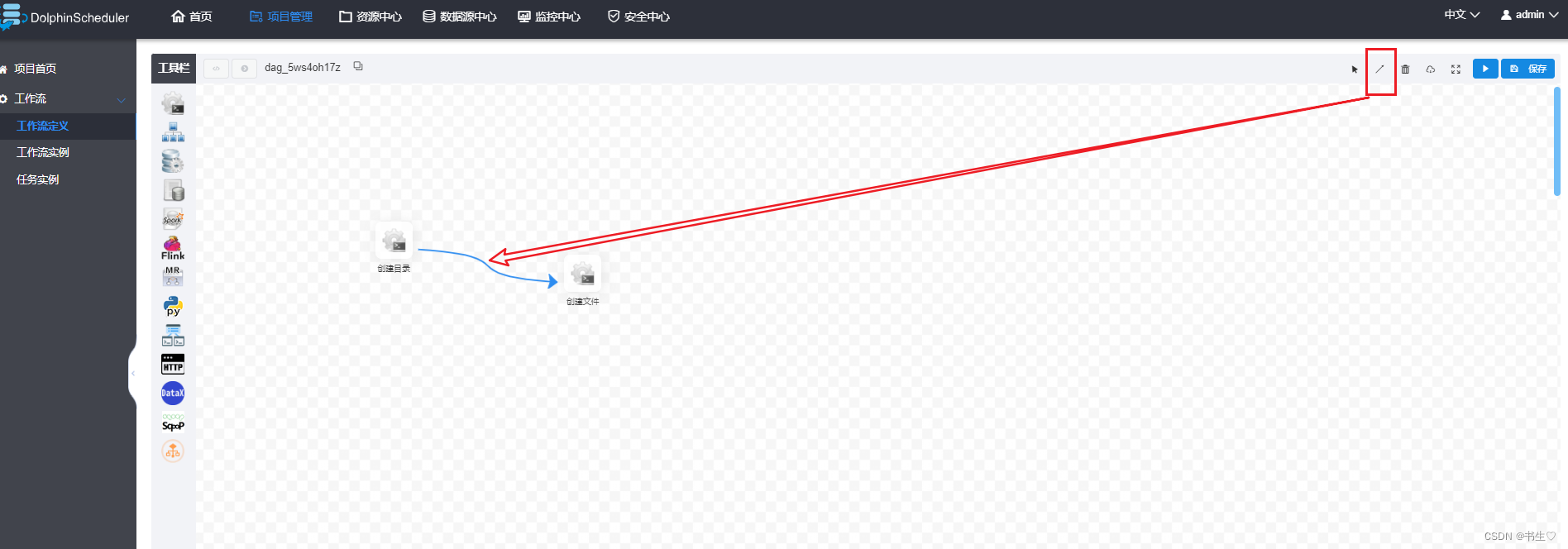
3. 点击保存,选择租户为root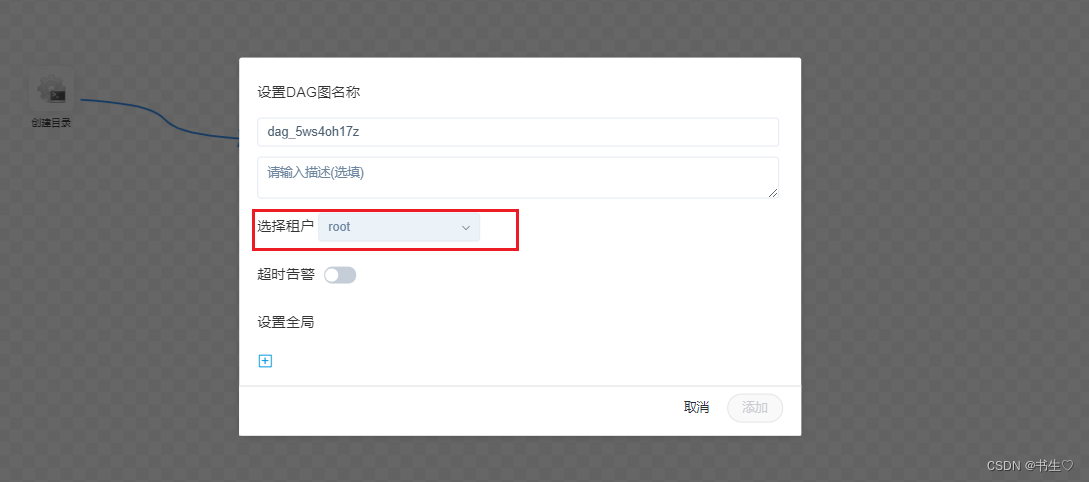
4. 上线运行工作流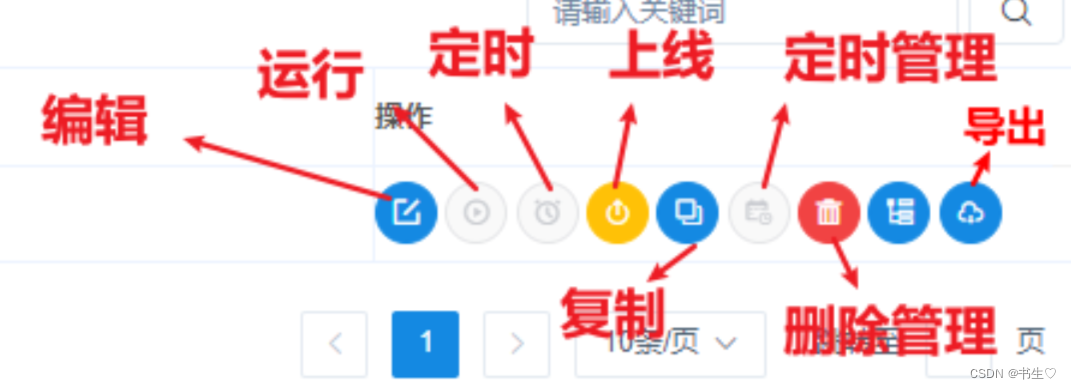
先点击上线,再点击启动,将我们的worker 分组改为我们的主机。
- 点击工作流实例和任务实例 可以查看程序是否启动成功,以及是否启动完成。

4.5 数据源中心
点击上面的数据源中心,点击创建数据源,添加对应的信息。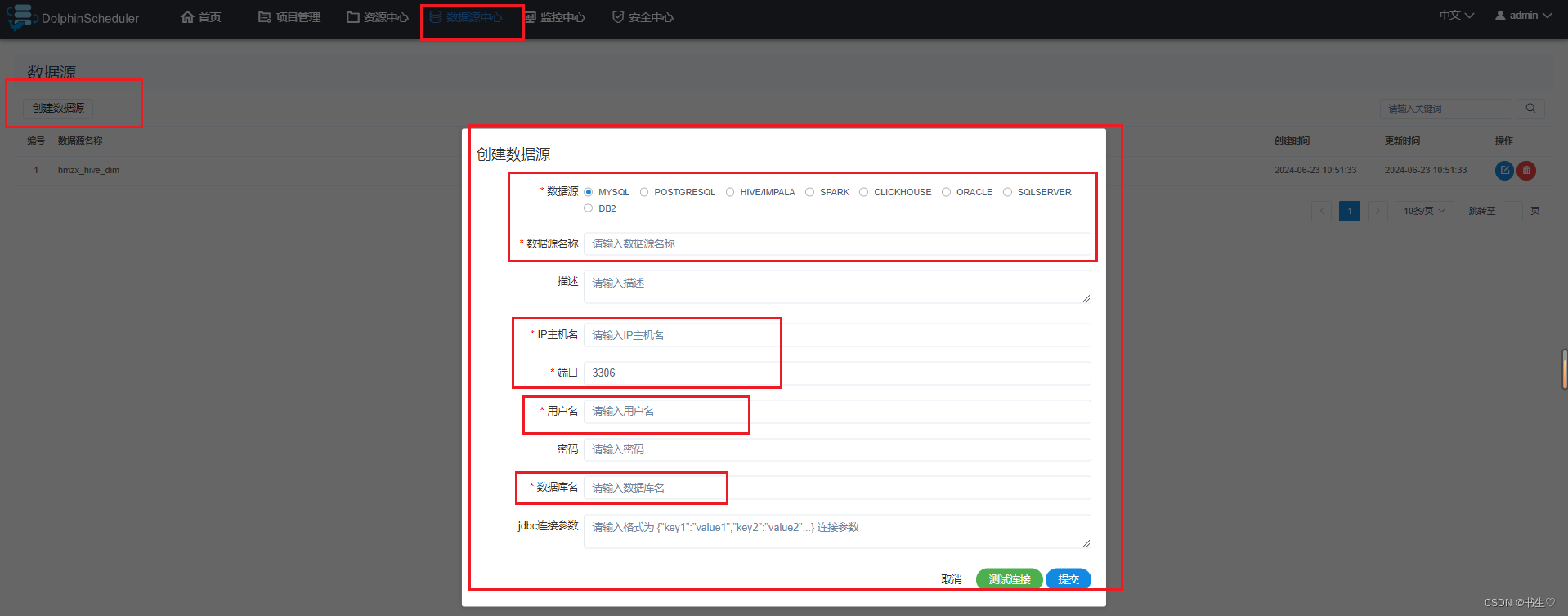
比如:我想连接HIve中的一个库,数据源先选择hive,取一个名称,IP地址就是服务器的ip地址,
端口 写对应的数据库的端口 Hive的是10000,mysql是3306等等。用户名哥密码按照对应的数据库的用户名和密码书写。最后是选择连接那个库?
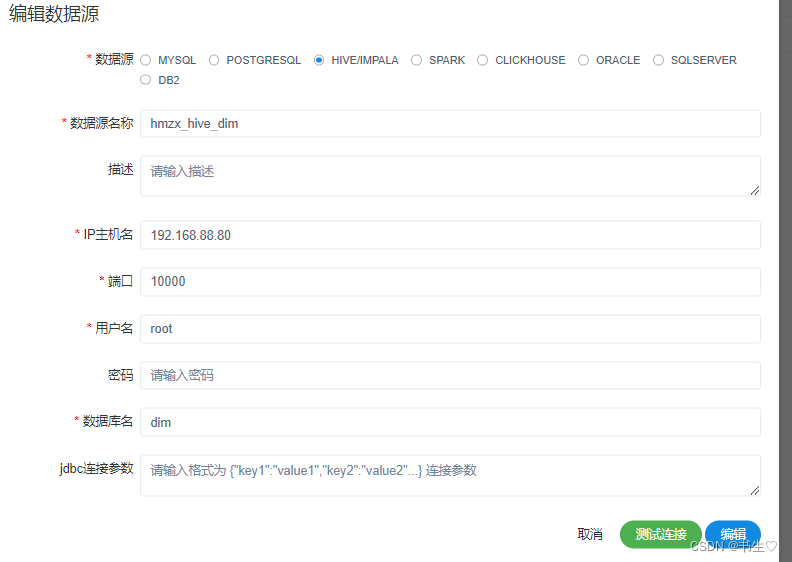
4.6 定时操作
如果我们想让这个程序定时的运行,那我们就可以这是设置定时管理。
- 在工作流定义,点击定时
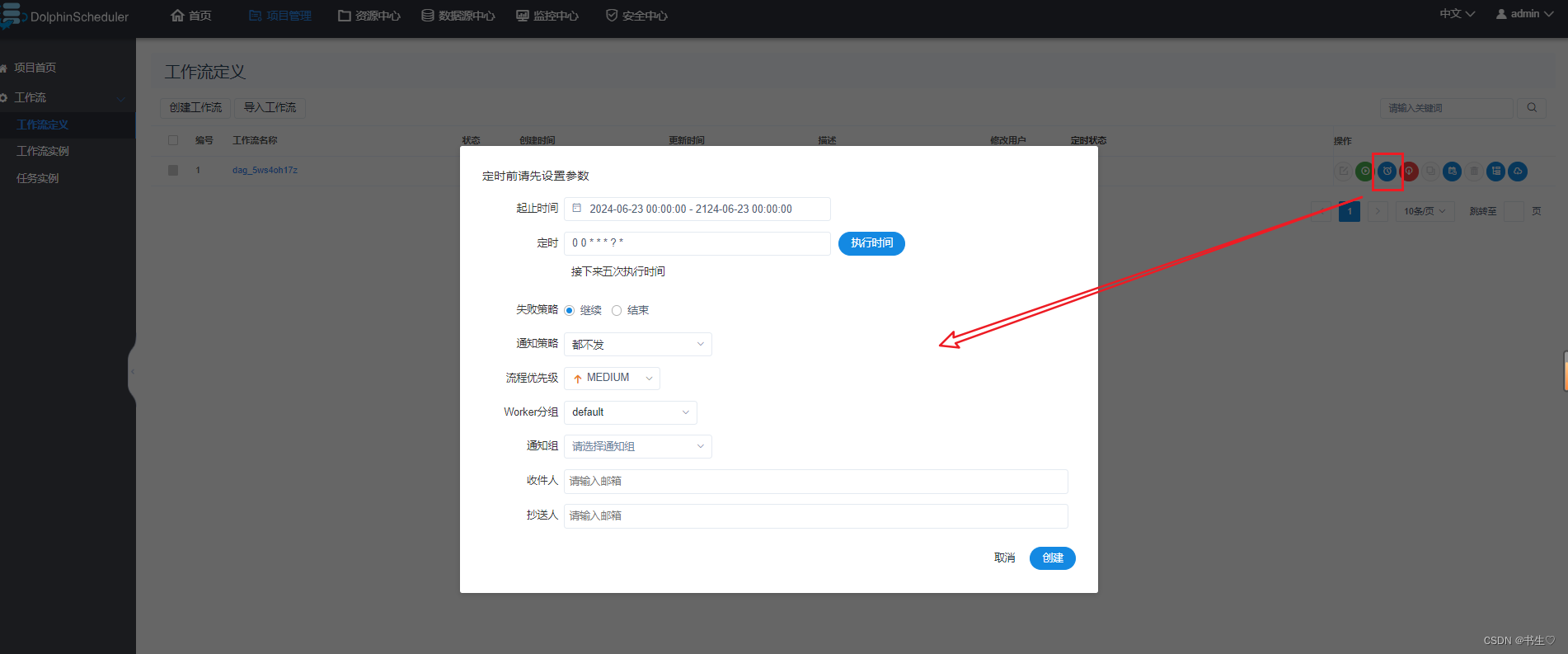 设置我们想要程序执行的时间 这里我们设置每5秒执行一次。
设置我们想要程序执行的时间 这里我们设置每5秒执行一次。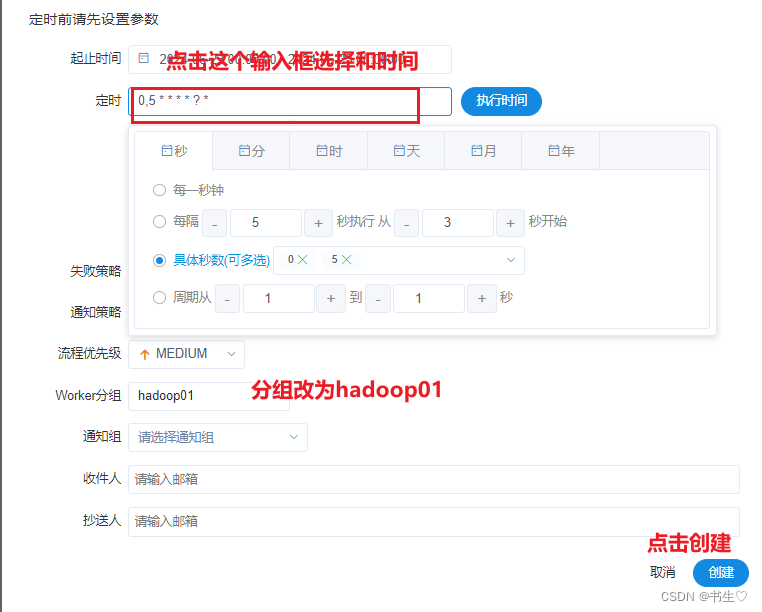 然后点击定时管理
然后点击定时管理
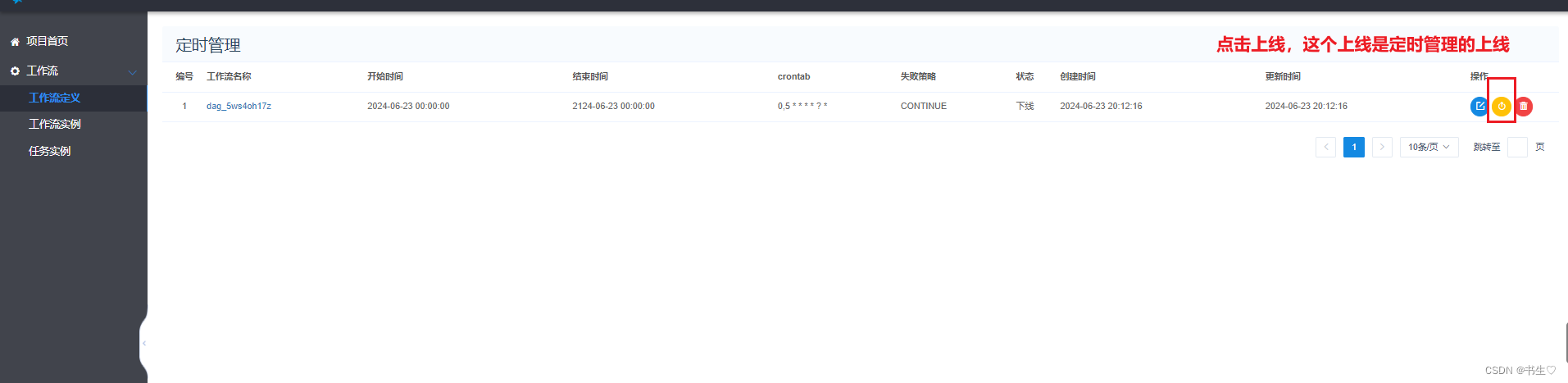
最后我们执行那个的时候,就可以让其每5秒执行一次。
5. 线上部署操作
我们的操作是将Hive中的dim层一个表导入到dwd层(分区的),在通过json将其导入到postgres中。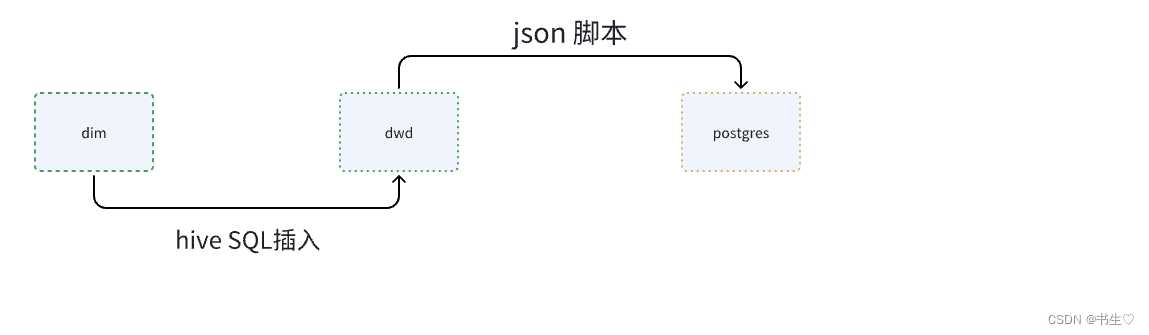
设置启动提示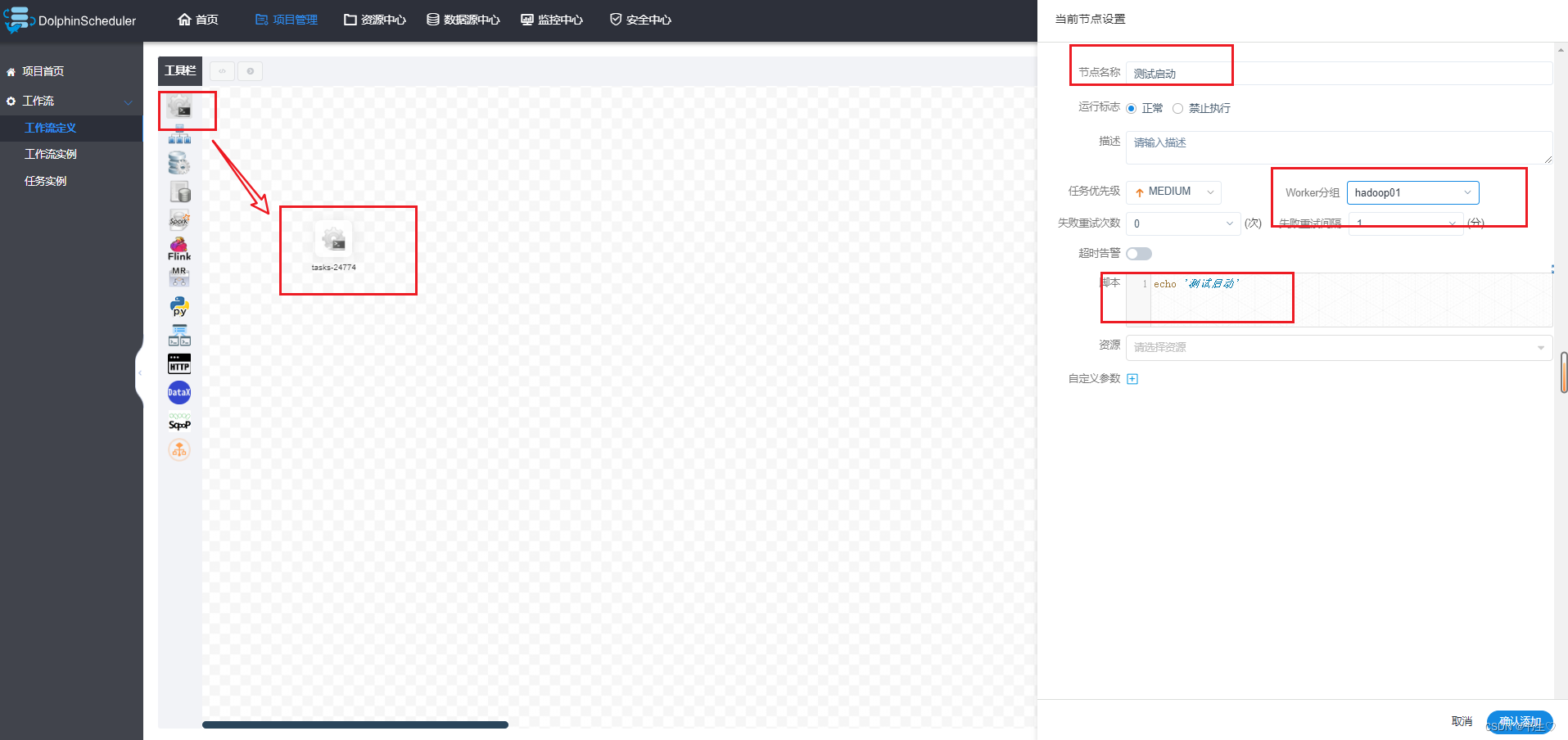
设置从dim层到dwd层的节点。先拖拽处一个可以执行SQL的节点,填写数据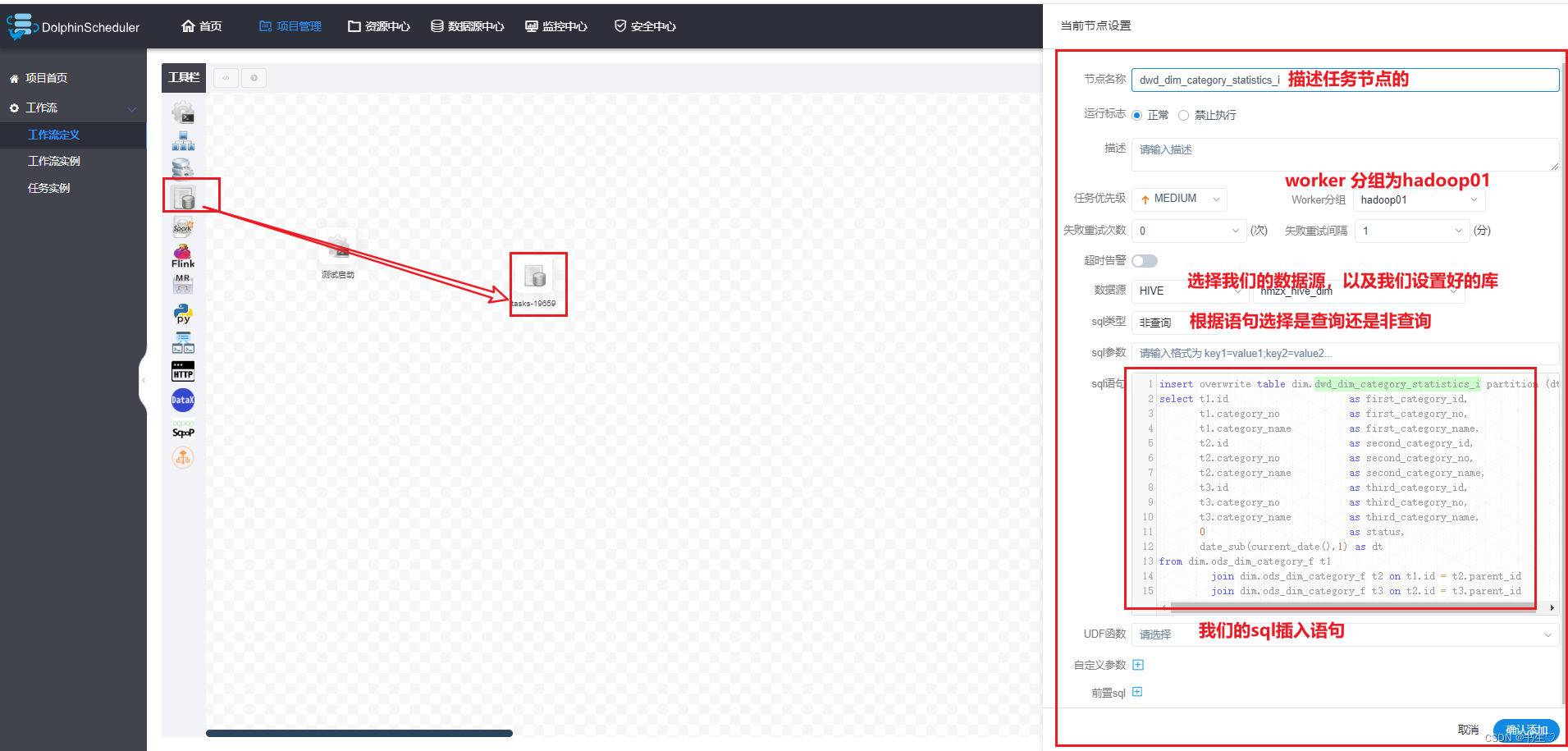
从dwd层到postgres是需要通过脚本的,因此我们选择一个执行shell的执行脚本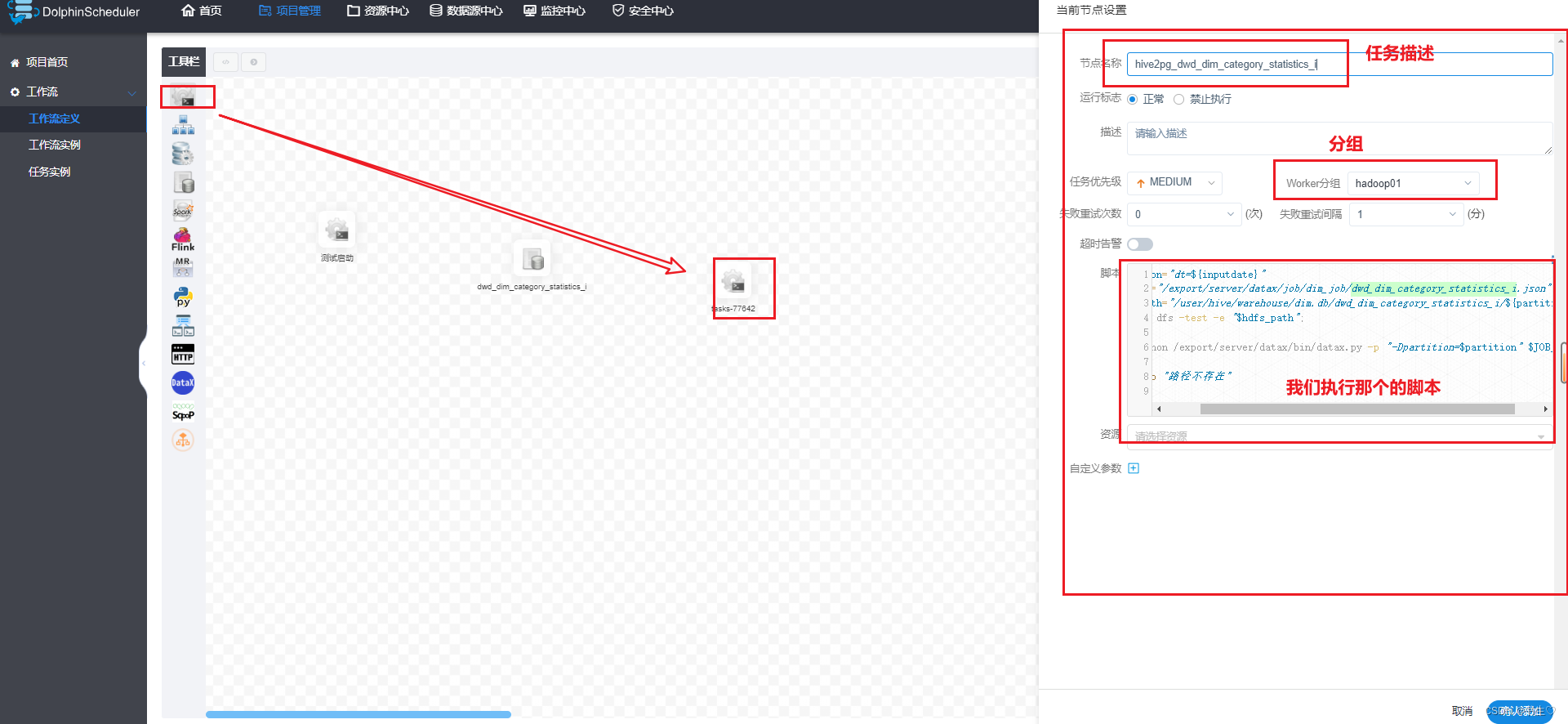
最后用线连起来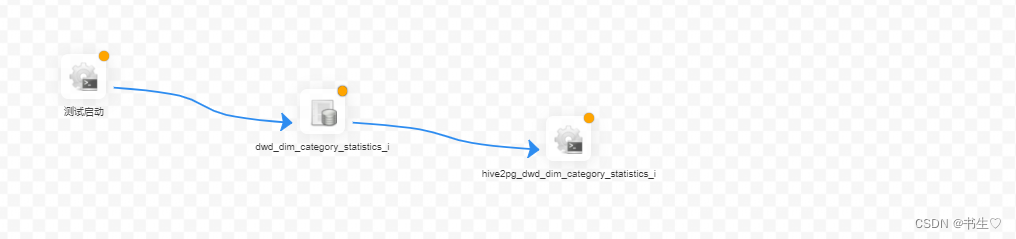
保存的时候注意 我们的是需要进行动态分区的,因此在保存的时候需要有点设置。 设置我们的分区时间,模版如下!!!
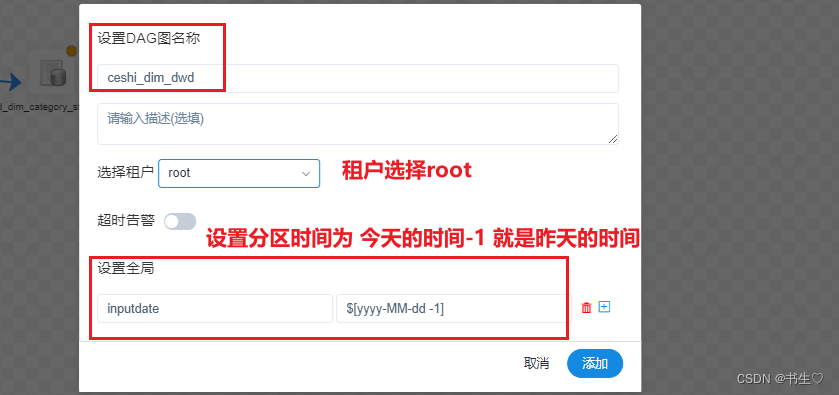
最后上线启动就可以啦。
编程之路虽充满挑战,但我们的智慧与毅力定能化难为易。愿在代码的海洋中遨游,创造出无数令人赞叹的程序。
版权归原作者 书生♡ 所有, 如有侵权,请联系我们删除。