
一、准备需要的安装包
1、安装jdk1.8
https://www.oracle.com/java/technologies/downloads/
找到对应的版本下载安装后配置环境变量
在控制台输入 java -version
查看对应版本,出版本后及为安装成功

2、安装scala:
https://www.scala-lang.org/download/2.12.12.html
现在多数用使用spark3.0以上版本,spark3.0版本不支持scala2.12以下版本
在官网下载完成后解压tar包(配置环境变量)
在控制台输入scala 能进入scala及为安装成功

3、安装maven
https://maven.apache.org/download.cgi
进入maven官网后下载对应的.tar.gz包即可
下载完成后对maven进行解压(idea不需要配置maven环境变量)
但需要对maven进行必要的配置修改!!(maven默认的服务器在在国外,后续idea配置maven时,下载会非常慢,需要把服务改到国内的阿里云maven仓库)
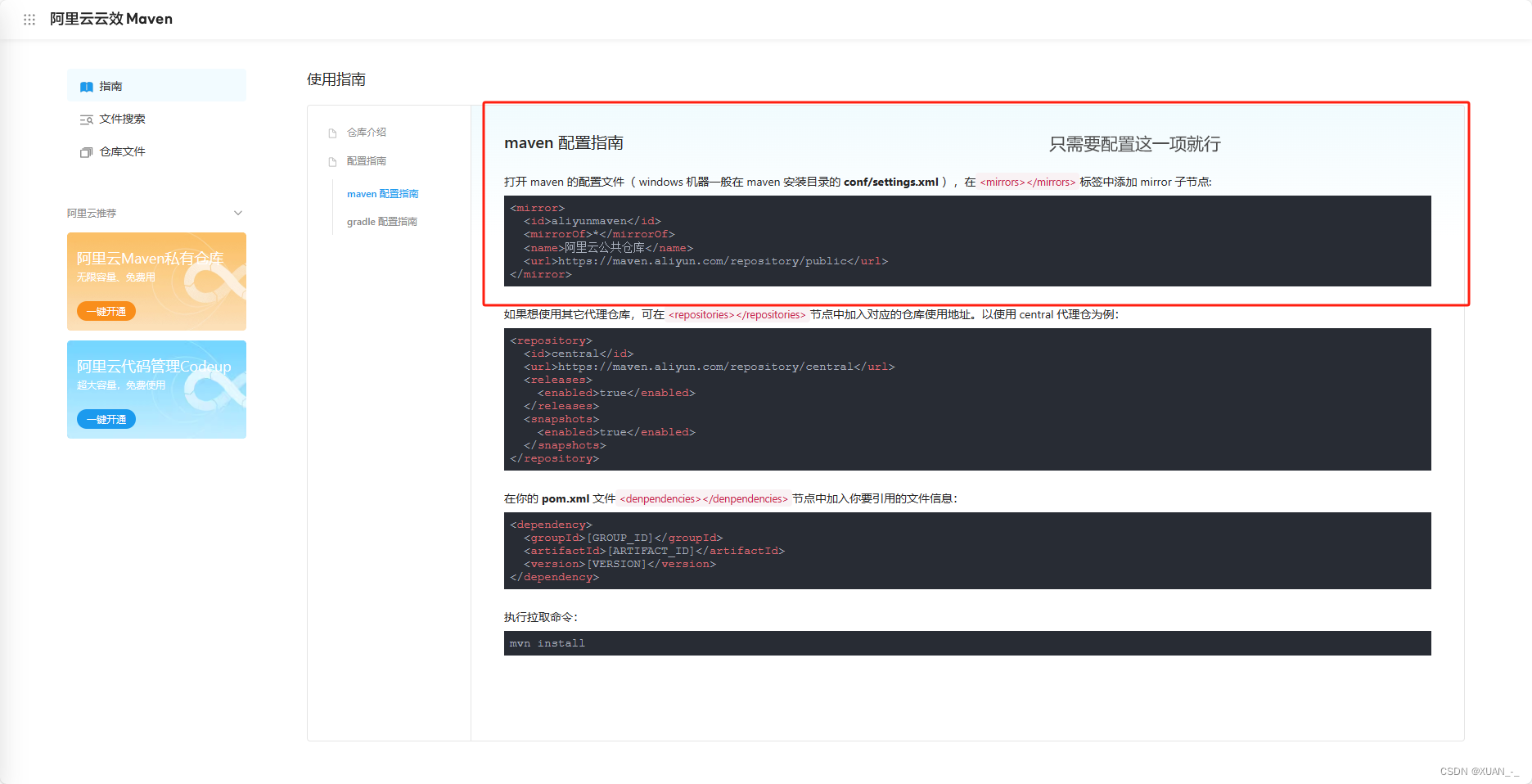
https://developer.aliyun.com/mvn/guide
进入阿里云的maven仓库按照指示进行配置
4、安装idea
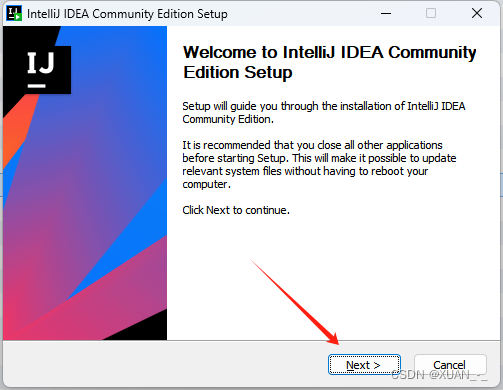
1、点击下一步
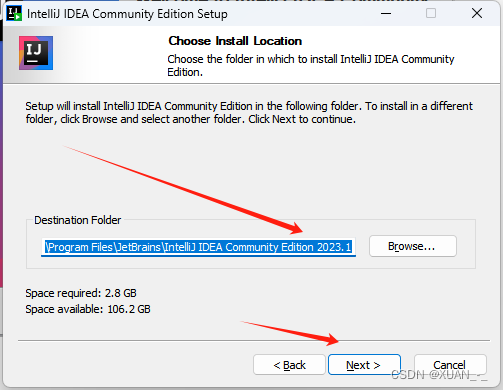
2、选择安装目录,点击下一步
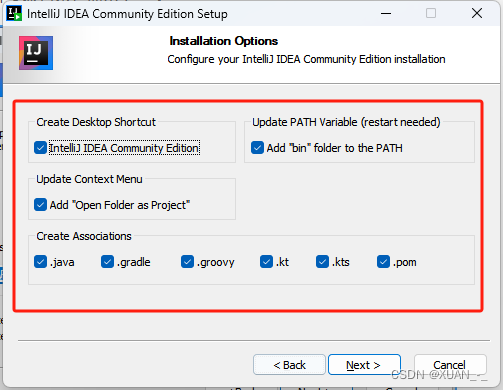
3、可以全选
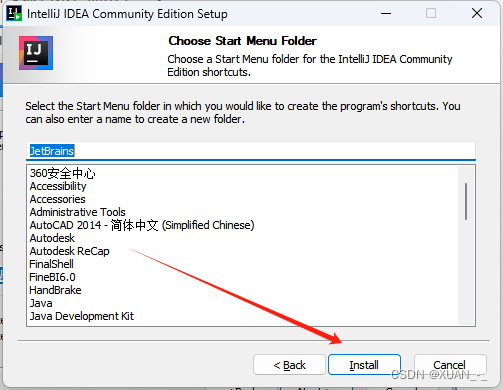
4、点击安装
安装完成打开idea
二、配置idea maven环境(MapReduce)
1、进入idea后先不要创建项目,如果创建项目后先退出项目(这样配置的就是全局设置)
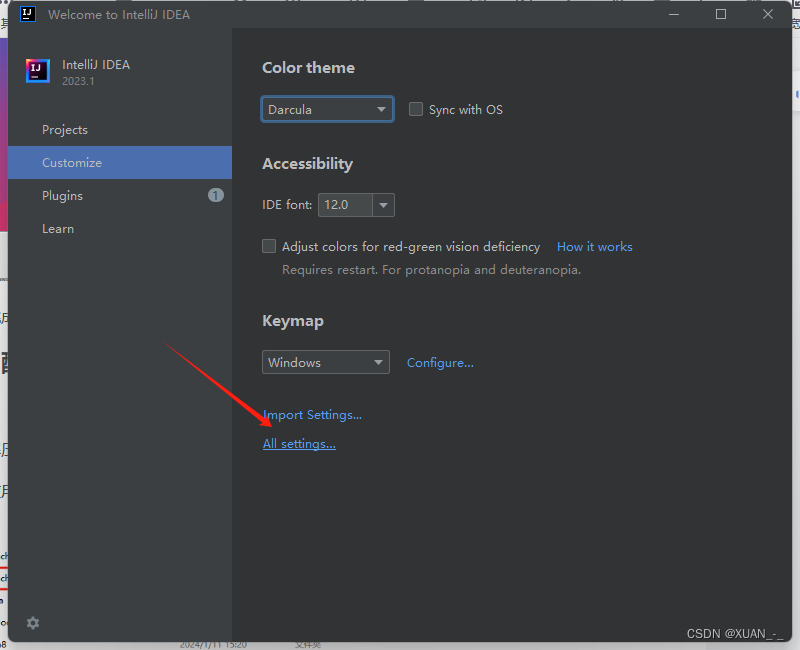
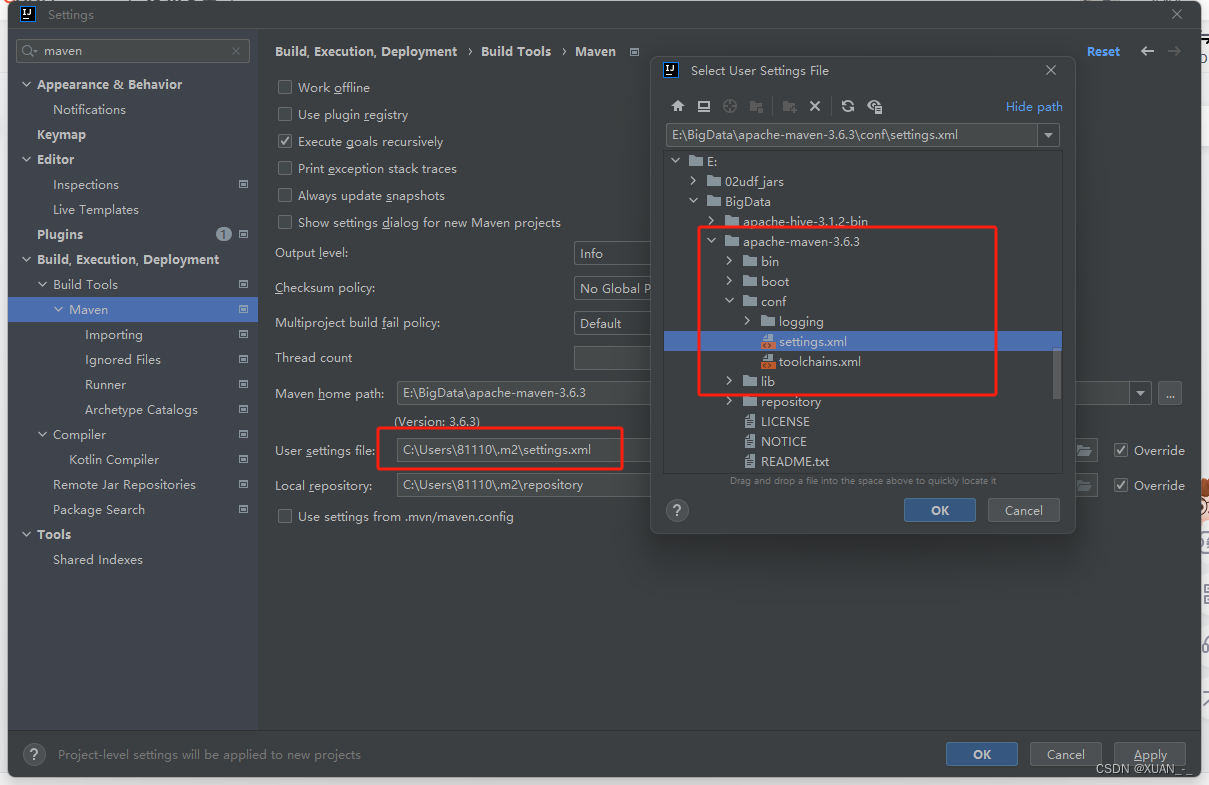
3、进入maven的配置目录
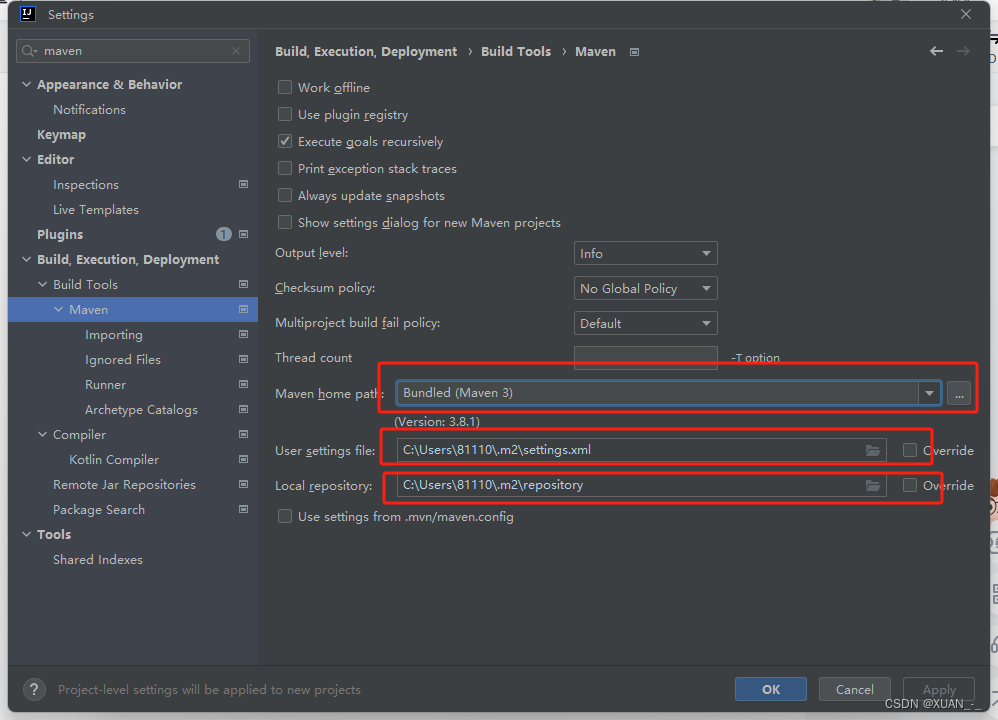
4、修改maven目录(设置为自己的maven解压目录)
目录不存在自行创建目录
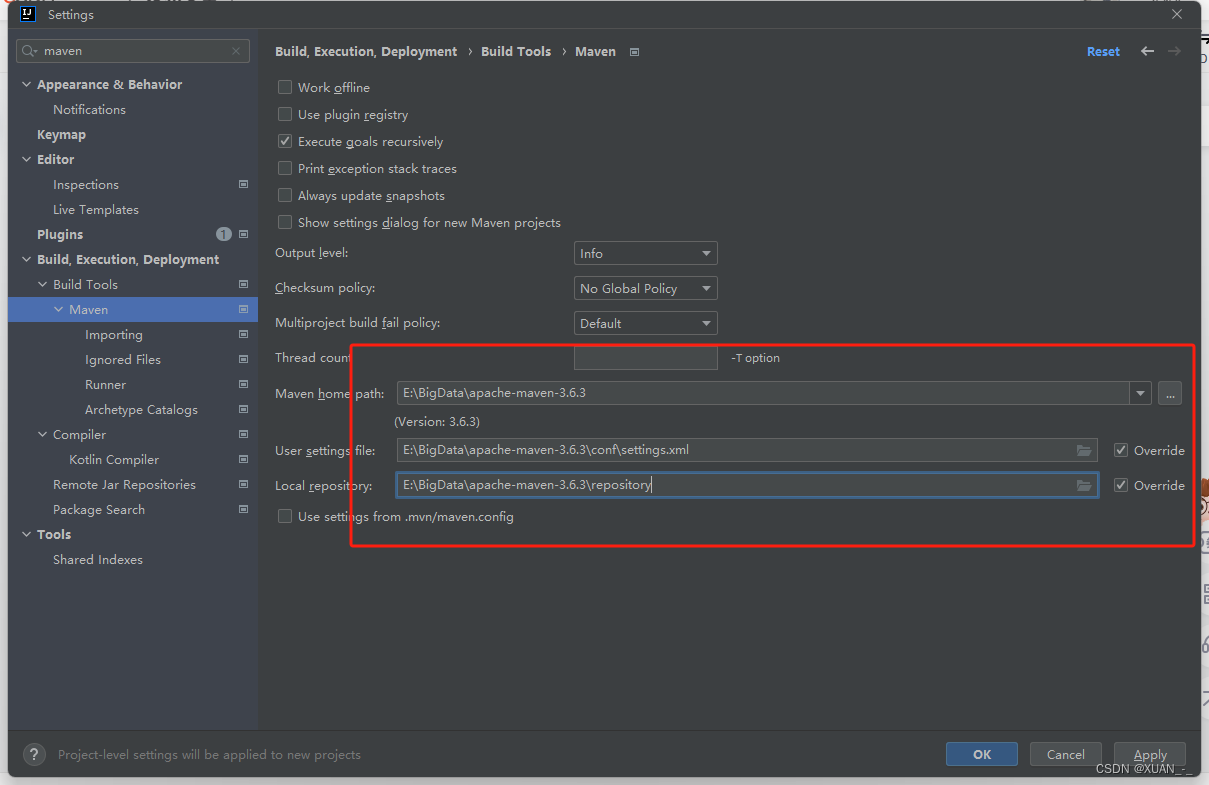 5、进入Runner进行配置
5、进入Runner进行配置
-DarchetypeCatalog=internal

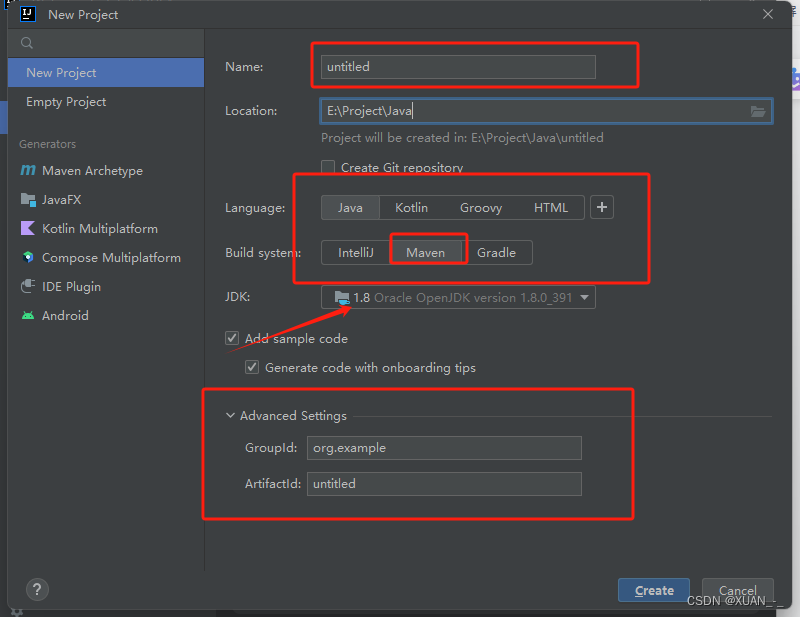
1、创建项目
1、创建一个Java Maven项目

2、创建完成后进入pom.xml配置文件进行maven配置
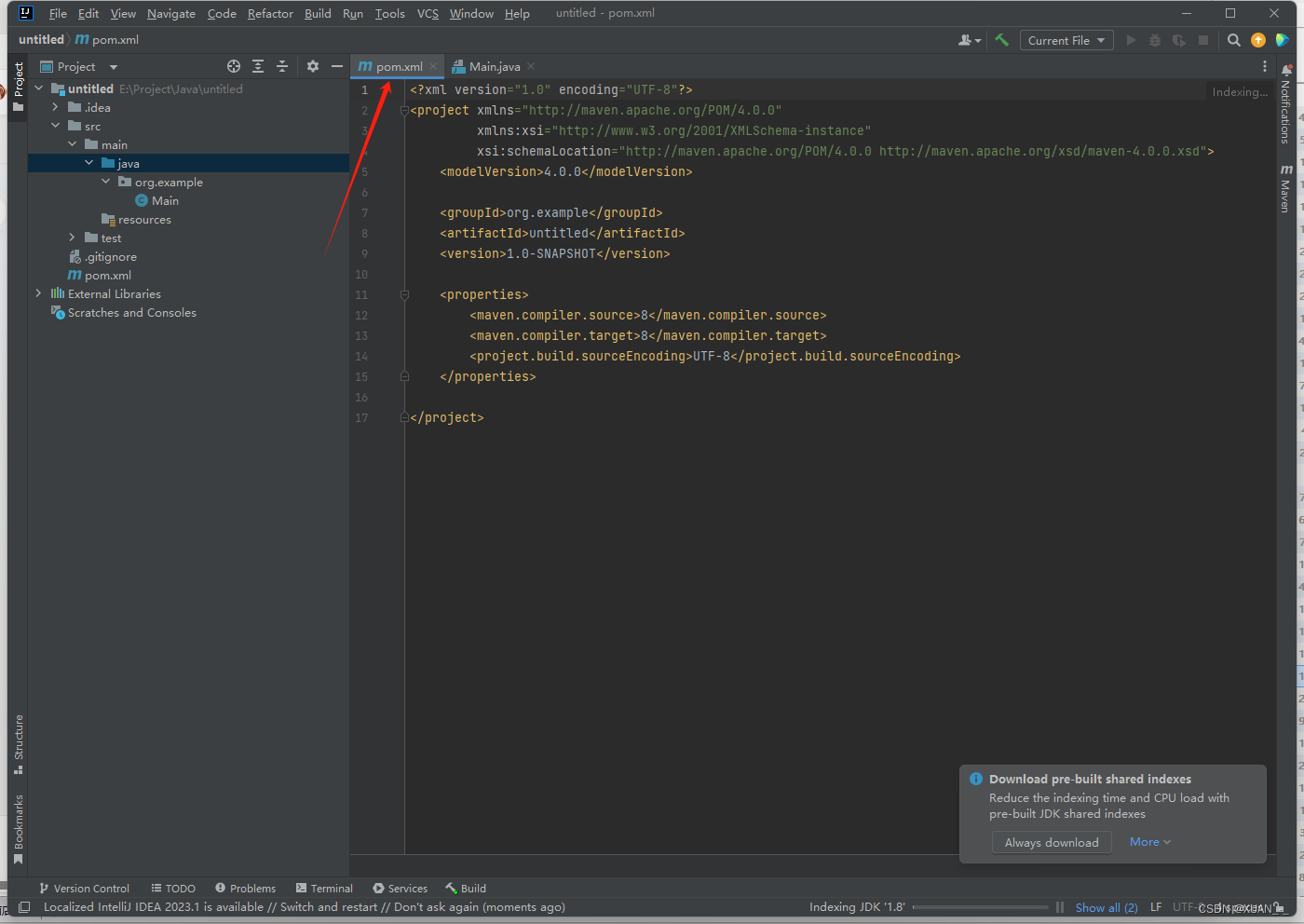
3、输入mapreduce所需要的maven
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.10.1</version>
</dependency>
</dependencies>
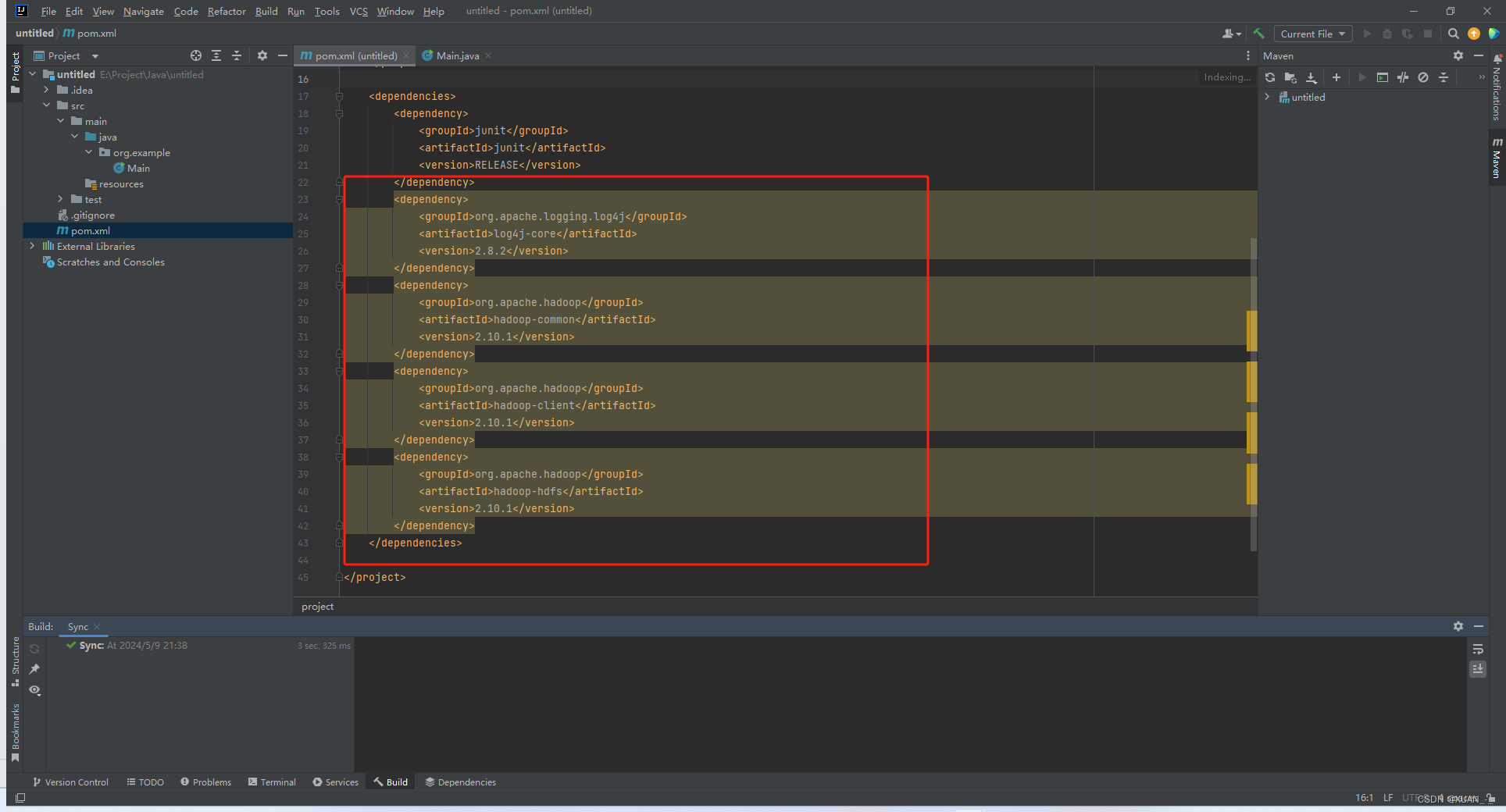
4、刷新,下载程序所需要的maven jar包
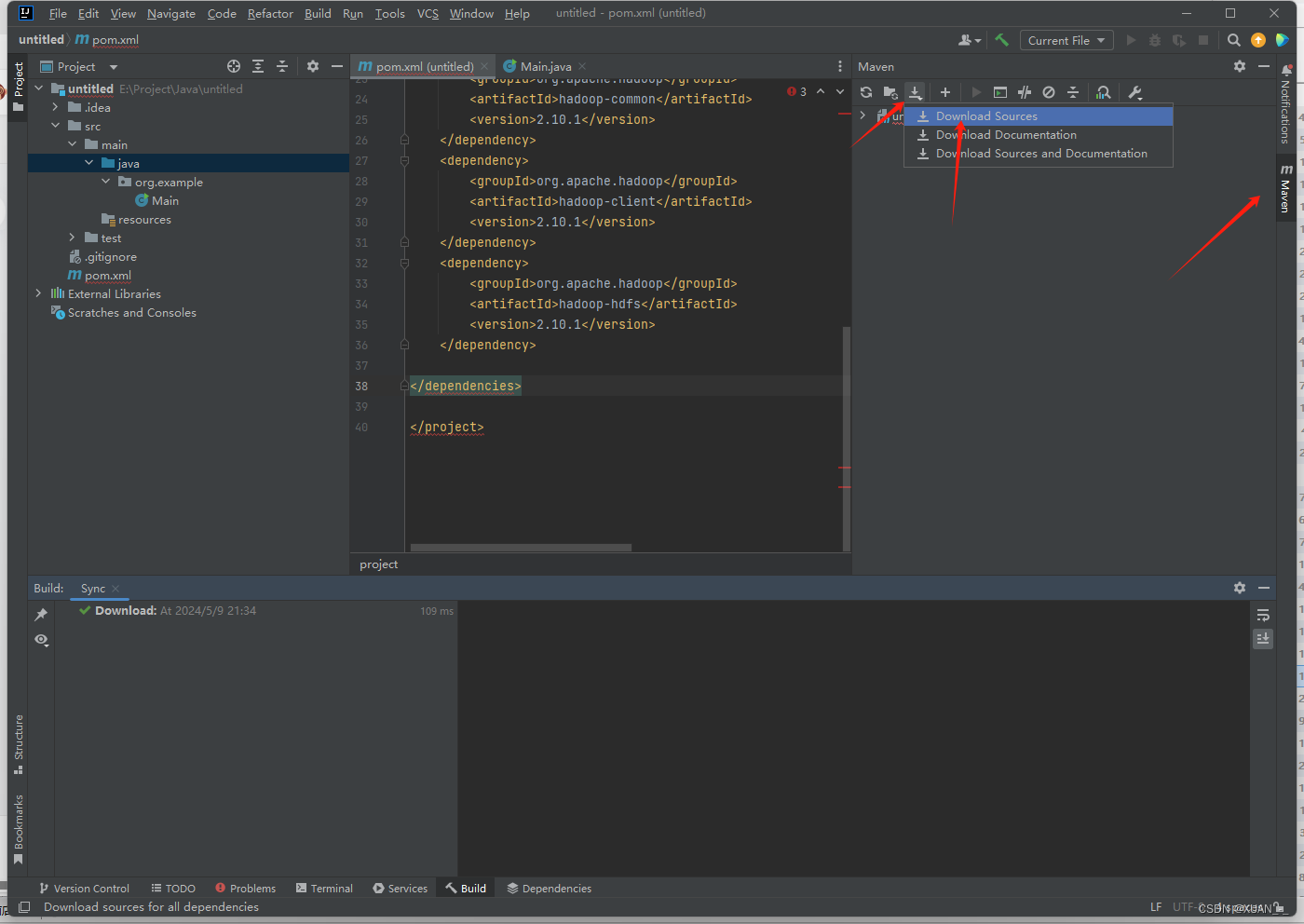
5、jar包下载完成后进行程序测试(写一个简单的wordcount程序)
测试代码放在下面了
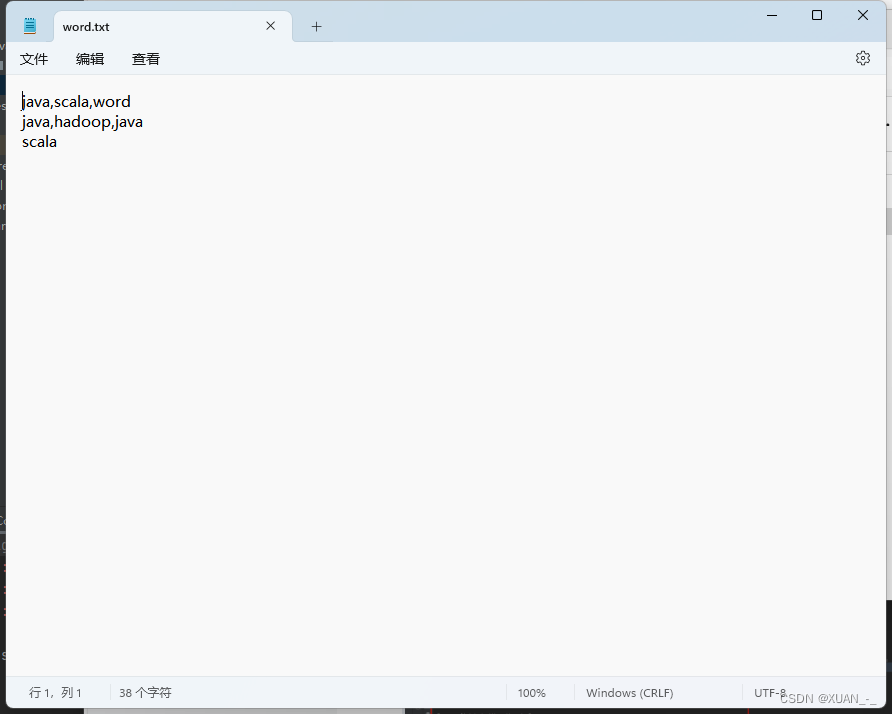
原始数据:
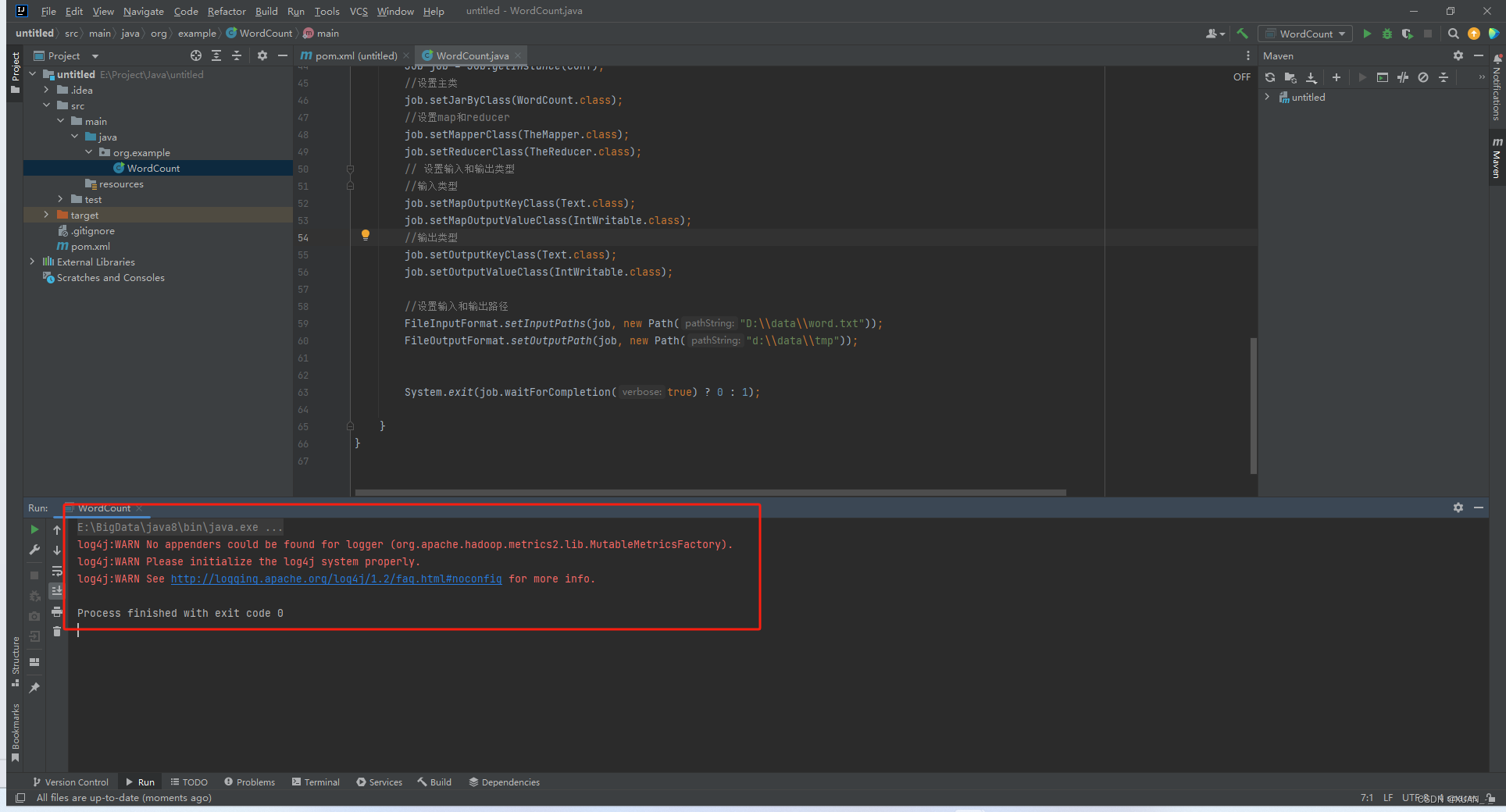
程序运行结束,查看结果
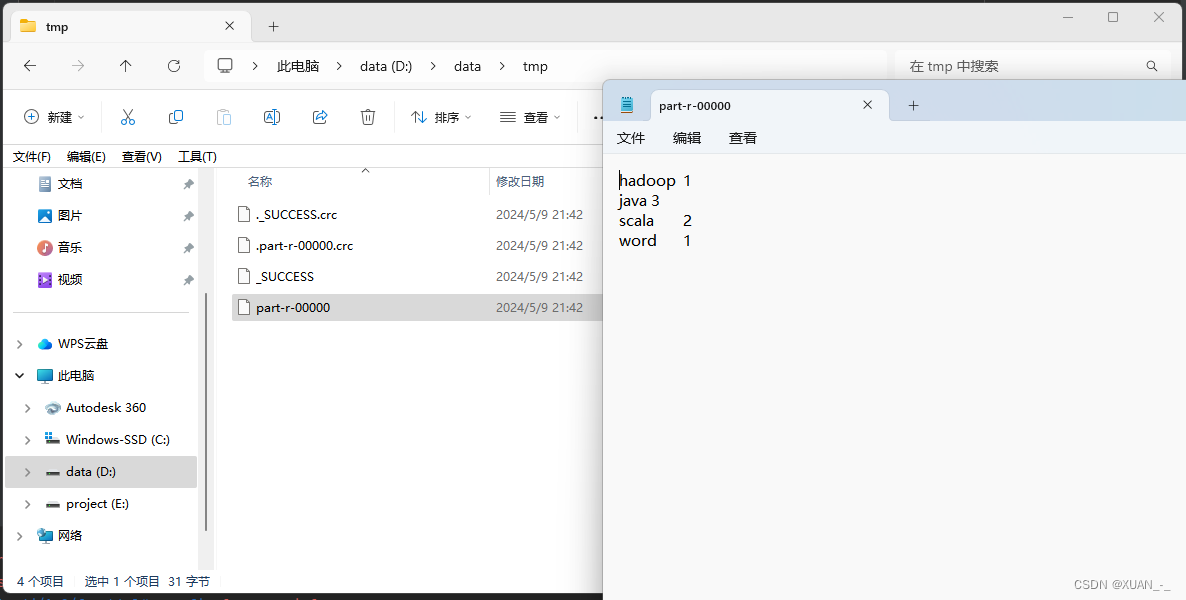
2、MapReduce WordCount程序
程序代码:
package org.example;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCount {
static public class TheMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String a = value.toString();
String[] words = a.split(",");
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}
static public class TheReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
public static void main(String[] args) throws Exception {
//设置环境参数
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//设置主类
job.setJarByClass(WordCount.class);
//设置map和reducer
job.setMapperClass(TheMapper.class);
job.setReducerClass(TheReducer.class);
// 设置输入和输出类型
//输入类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\data\\word.txt"));
FileOutputFormat.setOutputPath(job, new Path("d:\\data\\tmp"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
三、配置Spark环境
1、配置spark maven
正常创建一个java的maven项目
在pom.xml配置文件中添加下面配置
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!-- 声明scala的版本 -->
<scala.version>2.12.11</scala.version>
<!-- 声明linux集群搭建的spark版本,如果没有搭建则不用写 -->
<spark.version>3.2.1</spark.version>
<!-- 声明linux集群搭建的Hadoop版本 ,如果没有搭建则不用写-->
<hadoop.version>3.2.1</hadoop.version>
</properties>
<dependencies>
<!--scala-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.2.1</version>
<scope>provided</scope>
</dependency>
</dependencies>
下载后刷新页面(第一次下载可能会有点慢)
2、运行第一个spark程序
一、创建一个scala文件
1)、下载scala插件(进入插件市场输入scala搜索下载,等待下载完成即可)
下载完成后重启idea
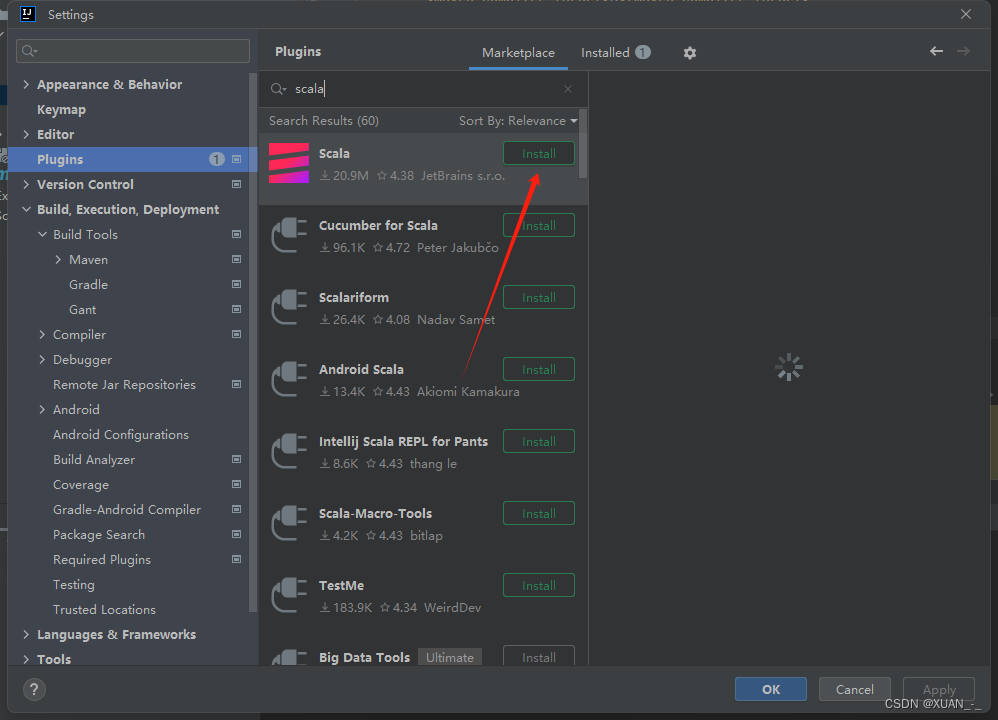
2)、加入scala程序文件
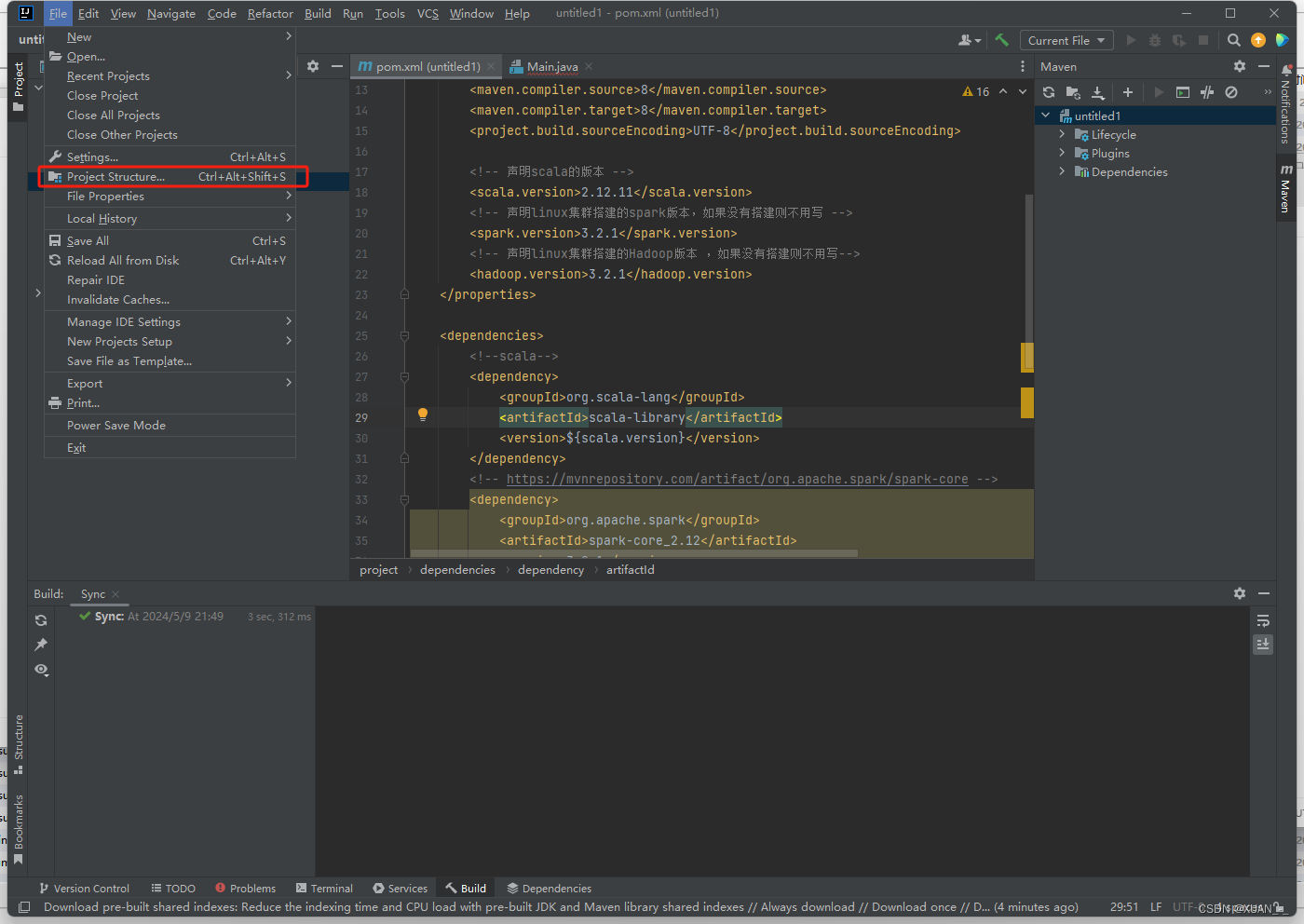

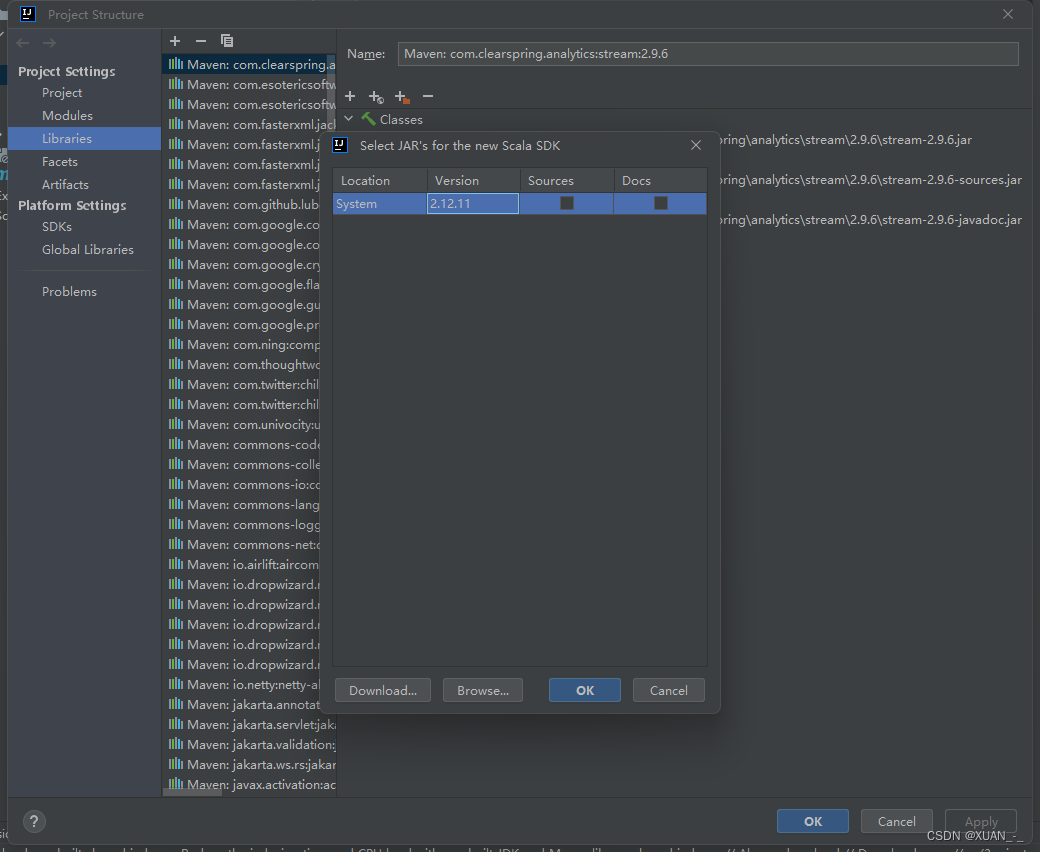
3)、创建第一个scala文件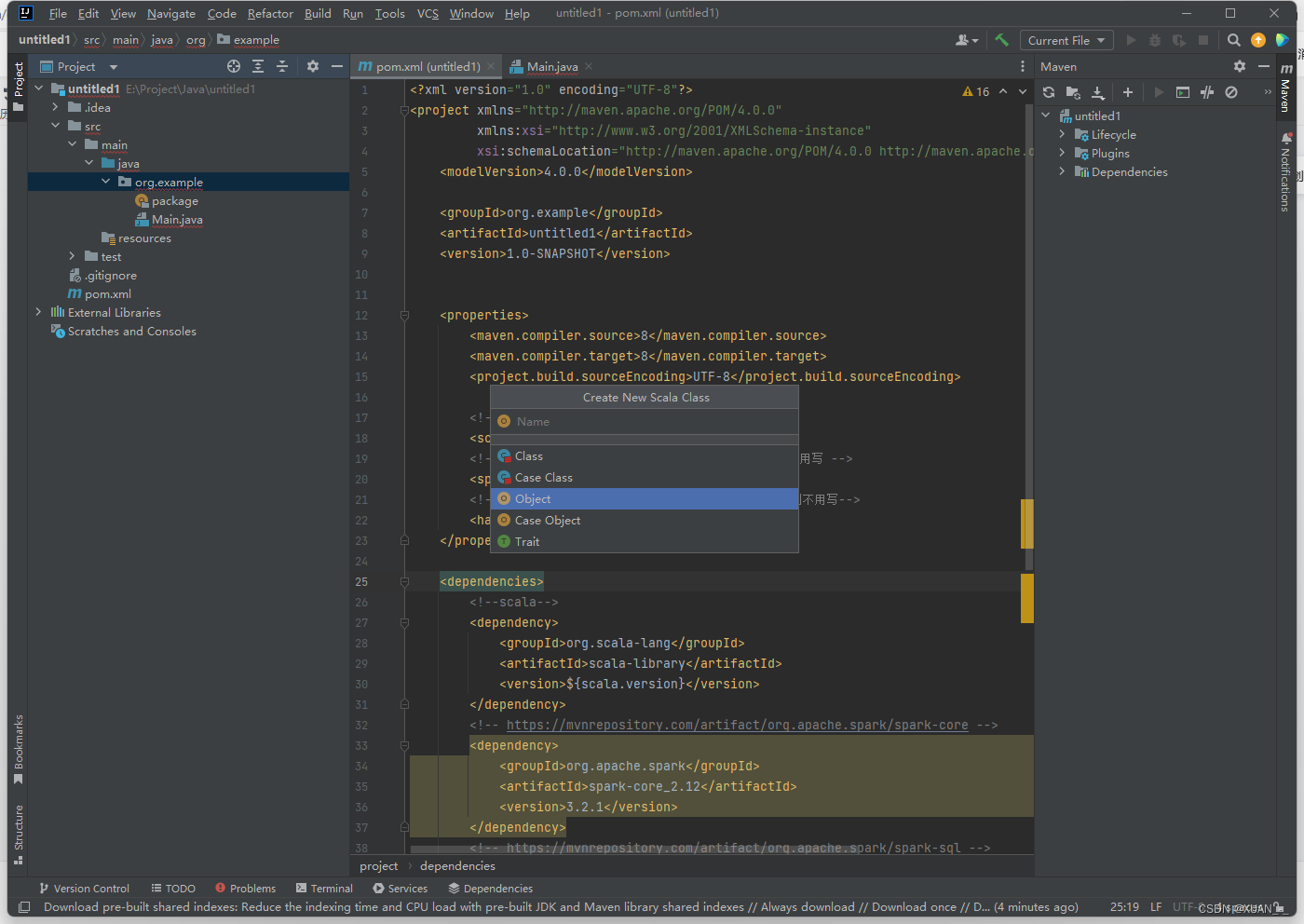
4)、写一个简单的wordcount程序
完整代码写在下方 (原始文件同上)

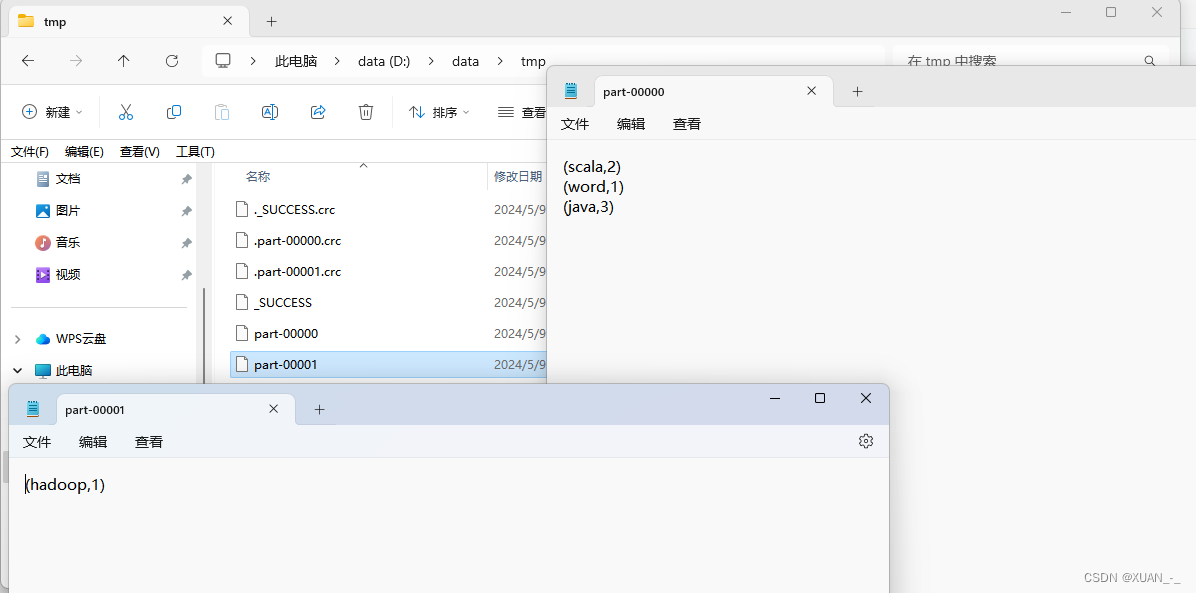
处理结果:
完整代码:
package org.example
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("wordcount").setMaster("local[1]")
val sc = new SparkContext(conf)
val rdd = sc.textFile("D:\\data\\user_info.csv") // 读取文件
.map(x => x.split(","))
.map(x => (x, 1))
.reduceByKey(_ + _)
.map(x => s"(${x._1}:${x._2})")
.saveAsTextFile("d:\\data\\tmp") // 保存到本地文件系统
val rdd1 = sc.textFile("d:\\data\\tmp") // 读取保存的文件
rdd1.collect().foreach(println) // 打印结果
sc.stop() // 停止SparkContext
}
}
版权归原作者 XUAN_-_ 所有, 如有侵权,请联系我们删除。