
介绍
在数据相关的职业生涯中遇到最痛苦的事情之一就是必须处理不同步的时间序列数据集。差异可能是由许多原因造成的——日光节约调整、不准确的SCADA信号和损坏的数据等等。在相同的数据集中,在不同的点上发现几个差异是很常见的,这需要分别识别和纠正每一个差异。而且当使用它时,可能会无意中抵消另一个同步部分。幸运的是,在新的“动态时间规整”技术的帮助下,我们能够对所有的非同步数据集应用一种适用于所有解决方案。

动态时间规整
简称DTW是一种计算两个数据序列之间的最佳匹配的技术。换句话说,如果你正在寻找在任何给定时间从一个数据集到另一个数据集的最短路径。这种方法的美妙之处在于它允许你根据需要对数据集应用尽可能多的校正,以确保每个点都尽可能同步。,甚至可以将其应用于不同长度的数据集。DTW 的应用是无穷无尽的,可以将它用于时间和非时间数据,例如财务指标、股票市场指数、计算音频等。唯一的警告是确保数据没有空值或缺失值,因为这可能会给 DTW 的工作带来麻烦。
用于寻找对应点之间最短路径的距离度量可以是 Scipy 的距离度量模块提供的任何度量。虽然在大多数情况下,欧几里得距离可以解决问题,但是你可能希望与其他距离进行试验以获得良好的度量。
实现
为了实现我们自己的 DTW 版本,我们将使用 Python 中的 fastdtw 库。这个包的新颖之处在于它简化了扭曲函数的复杂性,从而将复杂性从 O(n²) 降低到 O(n),这在运行时提供了明显的差异。
请继续启动 Anaconda 或您选择的任何 Python IDE 并安装 fastdtw,如下所示:
pip install fastdtw
随后,导入所有必需的包:
import numpy as np
import pandas as pd
import streamlit as st
import plotly.express as px
from sklearn.metrics import r2_score
在运行同步之前导入数据集并填写任何空值:
df = pd.read_csv('dataset.csv')
df['Power'] = pd.to_numeric(df['Power'],errors='coerce')
df['Voltage'] = pd.to_numeric(df['Voltage'],errors='coerce')
x = np.array(df['Power'].fillna(0))
y = np.array(df['Voltage'].fillna(0))
然后继续执行同步:
distance, path = fastdtw(x, y, dist=euclidean)
同步路径的结果将类似于以下内容:
path = [(0, 0), (0, 1), (0, 2), (1, 3), (2, 4),...]
参考数据集中的每个点都将与目标数据集中的一个或多个点进行匹配,即参考数据的第 0 行可以与目标数据的点 0、1 或 2 匹配。
现在有了扭曲的路径,可以继续创建具有同步结果的数据框,如下所示:
result = []
for i in range(0,len(path)):
result.append([df['DateTime'].iloc[path[i][0]],
df['Power'].iloc[path[i][0]],
df['Voltage'].iloc[path[i][1]]])
df_sync = pd.DataFrame(data=result,columns=['DateTime','Power','Voltage']).dropna()
df_sync = df_sync.drop_duplicates(subset=['DateTime'])
df_sync = df_sync.sort_values(by='DateTime')
df_sync = df_sync.reset_index(drop=True)
df_sync.to_csv('C:/Users/.../synchronized_dataset.csv',index=False)
最后,您可以使用 Sklearn 的 r2_score 模块计算相关性分数,以比较同步前后的相关性或同步水平:
correlation = r2_score(df['Power'],df['Voltage'])
数据可视化
为了绘制和可视化您的同步数据,我们将使用 Plotly 和 Streamlit——我最喜欢的两个用于可视化数据并将其呈现为应用程序的库。
可以使用下面的函数来创建时间序列图表。请确保时间戳采用正确的 dd-mm-yyyy hh:mm 格式,或者修改函数以适应你的数据。
def chart(df):
df_columns = list(df)
df['DateTime'] = pd.to_datetime(df['DateTime'],format='%d-%m-%y %H:%M')
df['DateTime'] = df['DateTime'].dt.strftime(' %H:%M on %B %-d, %Y')
df = df.sort_values(by='DateTime')
fig = px.line(df, x="DateTime", y=df_columns,
labels={
"DateTime": "DateTime",
"value": "Value",
"variable": "Variables"
},
hover_data={"DateTime": "|%d-%m-%Y %H:%M"})
fig.update_layout(
font_family="IBM Plex Sans",
font_color="black"
)
fig.update_xaxes(
rangeselector=dict(
buttons=list([
dict(count=12, label="12h", step="hour", stepmode="backward"),
dict(count=1, label="1d", step="day", stepmode="backward"),
dict(count=7, label="7d", step="day", stepmode="backward"),
dict(step="all")
])
)
)
st.write(fig)
要可视化和呈现图表,请通过在 Anaconda 提示符下键入以下命令来运行您的脚本:
cd C:/Users/.../local_directory
streamlit run synchronization.py
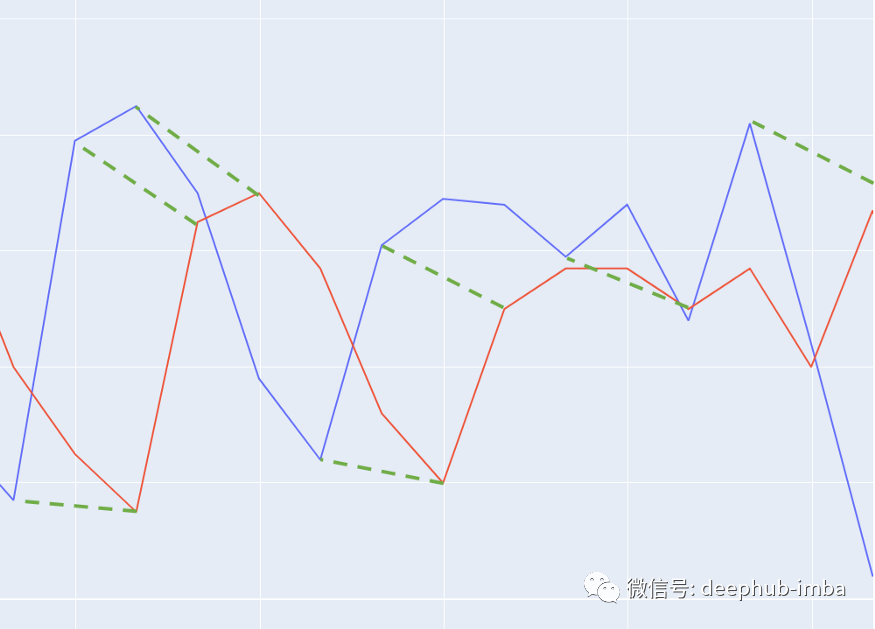
可以在同步之前和之后对数据进行可视化:

总结
动态时间规整可能是快速方便地同步时间序列数据的最有效的解决方案。虽然它不是完美无缺的,确实存在边界条件匹配性差等缺点,但它是我接触过的最全面的解决方案。并且它绝不限于线性数据,并且确实可以同步具有不同维度的非线性数据。
作者:M Khorasani