
前言
WebServer是一个很好的入门级C++项目,因为它涉及到了方方面面,不仅可以提高编程能力,还包括了操作系统、计算机网络、数据库等方面的知识,所以我很推荐大家去入手这个项目。说细一点这个项目包含系统编程、日志系统、线程池、网络知识、并发模型等实现,但是很多人一开始做这个项目的时候,会觉得逻辑很混乱从而无从下手,所以我写下这篇文章目的就是帮助大家起到一个梳理逻辑的作用,好了废话不多说,咱们往下看!
一、下载项目、功能测试
拿到一个项目首先不要着急自己复现、也不要着急去看功能,首先我们要测试一下能不能跑成功
qinguoyi/TinyWebServer: :fire: Linux下C++轻量级WebServer服务器 (github.com)以这个项目为例
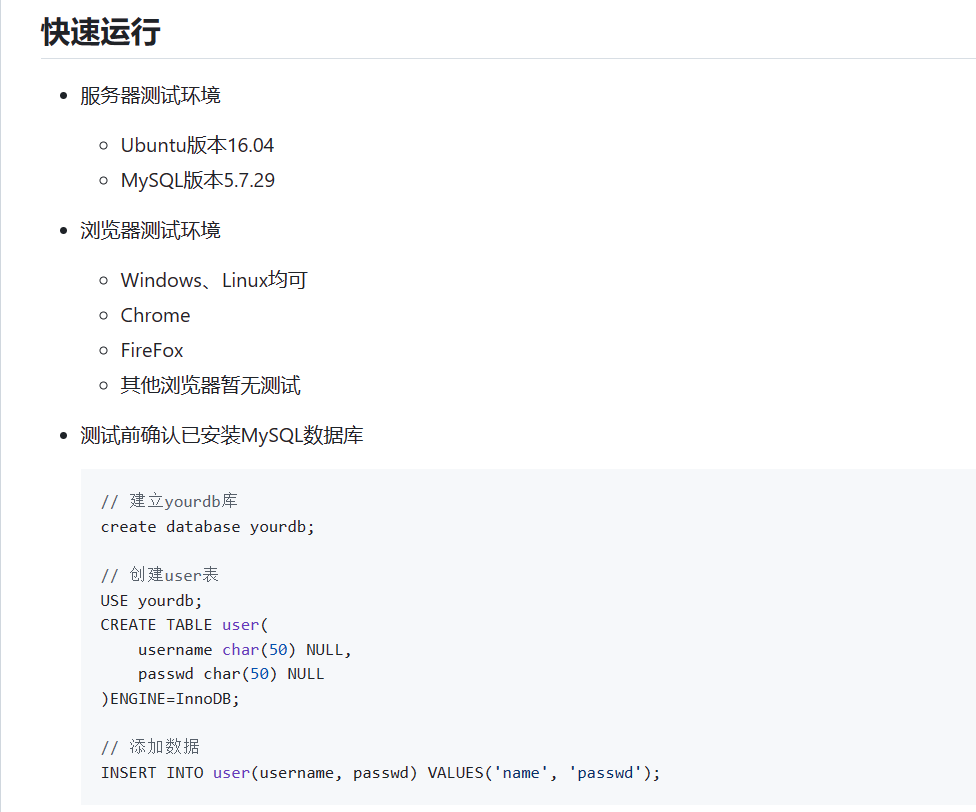
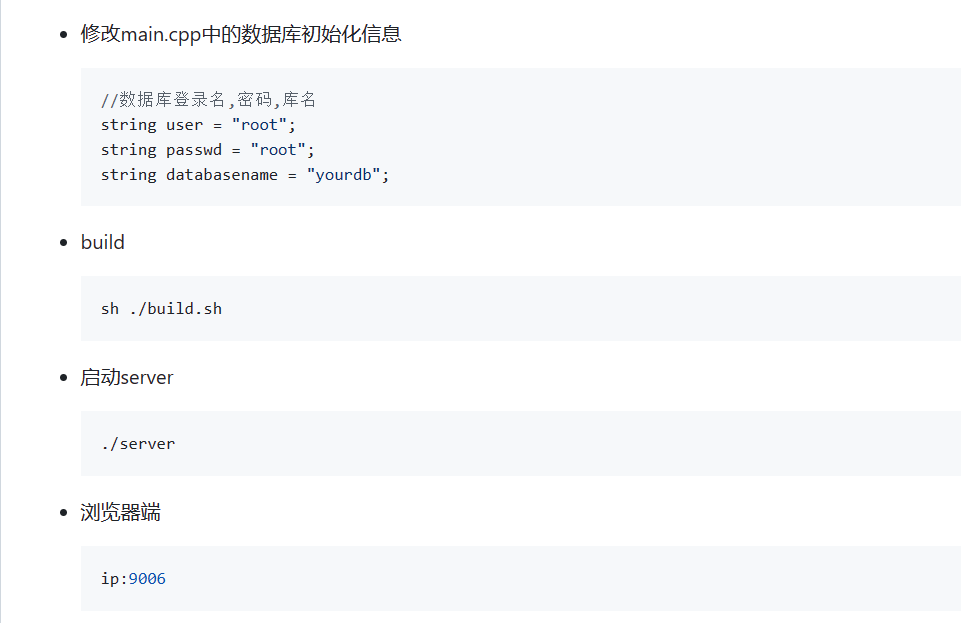
在这个过程中,可能会遇到如下这个问题:
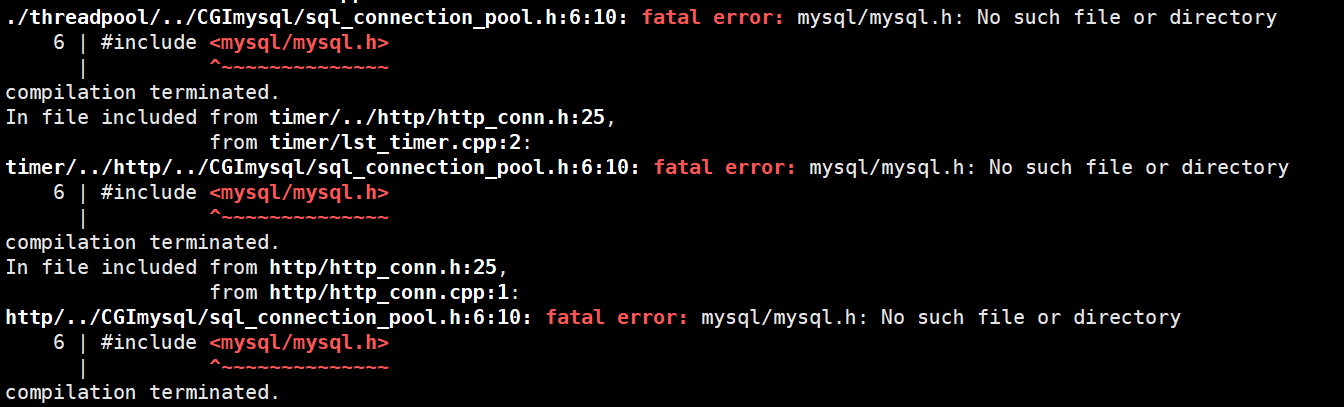
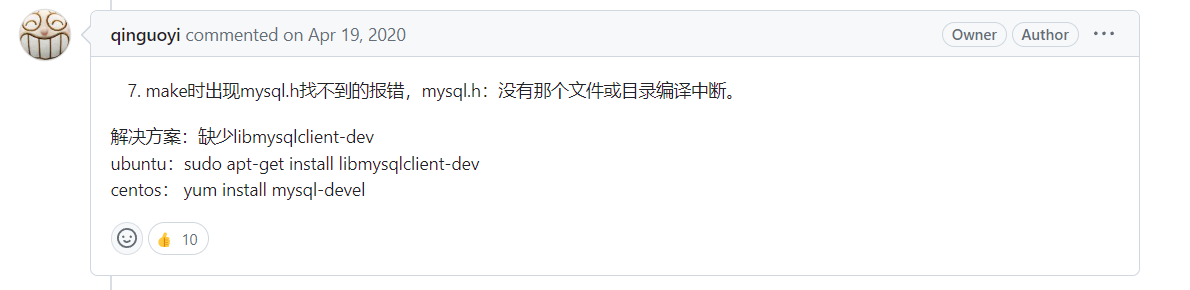
不要慌~ 作者给出了解决方案
二、Demo演示
三、该怎么去看框架?
首先进入到main函数里,一层一层的看依赖关系,直到找到最里面的那一层,也就是最底层,然后从最底层开始,一个文件一个文件的写。我们举例来看,main函数里面,最先是个Config类的对象,这个对象用来进行配置操作,比如对端口号、日志写入方式、触发组合模式等等的赋值,所以我们暂且不管它。接下来我们可以观察到,有一个WebServer类的对象server,并且发现server调用了一堆函数,那我们便知道最后在main函数里面全部依靠server这个对象实现,所以不难得出,WebServer类就是我们的最高层,通过最终封装一个WebServer类来实现一切功能,但是我们要找到是最底层,从最底层一层一层往上写,所以接下来我们进入WebServer类进行观察,我们知道WebServer类的主要职责就是将之前设计的各个模块串联在了一起,我们可以观察到WebServer类中有许多数据成员和成员函数,我们暂时不需要知道这些成员是具体来干什么的,只需要先知道其中的函数是给自己相关的数据成员赋值的或者实现某个功能,比如在log_write()中来决定是异步写日志还是同步写日志,sql_pool()函数是用来申请一个数据库连接池的对象,并且进行初始化等操作,thread_pool()是用来申请一个线程池对象,并进行相关初始化操作的。我们目前不需要知道很多信息,但是请务必先留意一下eventListen()和eventLoop()这两个函数,我们先进入webserver.cpp中去看,注意到eventListen()是用来进行监听的,当有新客户来临的时候,将它加入监听集合,那eventLoop()是用来干什么的呢?可以看到它的循环体里面,好像是在等待事件发生,然后再处理各种各样的事情并且一直在循环,是的,它就是我们的主循环函数,是用来处理各种业务的。接下来既然我们是WebServer服务器项目,那什么是最重要的呢?没错当然是http解析了,所以接下来我们看http解析的实现,浏览器(客户端)发起http连接请求,我们的服务器就会接收到请求,并且需要将请求的内容记录起来,最后再做出响应的答复给浏览器,在http类中,我们要做的事情就是接收连接,处理连接(设计两个状态机,即主状态机/从状态机来进行报文解析),响应连接,最后封装了一个运行函数(process)。那我们在接收连接,处理连接,以及做出响应处理的时候不能就一个线程来实现吧,那效率该有多低呀,所以在这一层之前我们必须先实现线程池。一切的一切需要先有用户吧,他们才能进行后续的一切请求,所以在这一层之前,需要实现数据库连接池。其实我们不难想象,我们实现的所有东西,都需要有一个记录吧,日志系统几乎是每一个实际的软件项目从开发、测试到交付,再到后期的维护过程中极为重要的查看软件代码运行流程,还原错误现场,记录运行错误位置等的重要依据。所以需要先实现一个日志系统。其实无论是写日志,还是请求各种资源等的操作都需要信号量或锁机制来实现吧,至此,我们便得到了整个项目的第一层也就是最底层,便是锁机制的实现,接下来分别是日志系统、数据库连接池、线程池、http连接处理、封装WebServer类、配置文件再到main函数,接下来我们便一层一层去分析!
第一层:锁机制的实现
在这个类中,我们需要封装信号量、锁机制以及条件变量,互斥锁用于同步线程之间对共享数据的访问,而条件变量或信号量则时用于在线程之间同步共享数据的值。
1.sem类就是我们要用来实现信号量的类,在这个类中,封装了以下操作
在构造函数中用sem_init来初始化一个信号量,有默认和带初值两种初始化方式,并且在析构函数中销毁信号量,释放其资源。
sem_wait操作是用来以原子操作的方式将信号量值 - 1,若信号量值为0则阻塞
sem_post操作是用来以原子操作将信号量+1
2.locker类同理,在构造函数与析构函数中分别初始化以及释放资源
lock操作是上锁,unlock操作是解锁,get操作时获得互斥锁的指针
3.cond类亦是如此
第二层:Log类
顾名思义,LOG类就是项目的日志系统。所谓日志,即由服务器自动创建,并记录运行状态,错误信息,访问数据的文件等。
日志的实现有两种,一种是同步写日志,一种是异步写日志
同步日志:日志写入函数与工作线程串行执行,由于涉及I/O操作,同步日志会阻塞整个处理流程,服务器所能处理的并发能力将有所下降,尤其是在访问峰值时,写日志可能会成为系统的瓶颈
异步日志:将工作线程所写的日志内容先存入阻塞队列,写线程从阻塞队列中取出内容,写入日志
在异步日志中,每个工作线程当有日志需要处理时,将所需写的内容所在内存加入一个阻塞队列,然后就不管了。而日志系统会单独分配一个写线程,不断地从阻塞队列中获得任务并写入日志文件中。从上面地日志工作流程描述中我们可以发现,这是一个典型的生产者-消费者模型。其中工作线程是生产,写线程是消费者。那么,生产者-消费者模型的临界区(缓冲区)是什么呢?在我们日志系统中,这个临界区就是一个队列。 在本项目中,我们使用循环队列来实现。
写日志的操作是通关一个对象来实现的,所以需要用单例模式来获取一个实例。
1.get_instance用来获取唯一的Log类实例
2.m_count用来记录日志行数,m_is_async用来标记是否是异步写日志,它们俩通过构造函数进行初始化,*m_fp是打开log的文件指针,它在析构函数中进行资源释放
3.flush函数用来刷新文件缓冲区
4.flush_log_thread用来进行异步写日志操作
5.init函数是对除了构造函数初始化之外的其余数据成员进行初始化的,可选择的参数有日志文件、日志缓冲区大小、最大行数、以及最长日志条队列
6.write_log中对日志进行了划分等级
第三层:connection_pool类与connectionRAII类
在程序设计思想中,"池"(Pool)通常指的是一种资源管理的模式,其中资源被集中管理并通过预先分配而不是按需创建。这种模式可以用于多种类型的资源,比如:
内存池
线程池
数据库连接池
那么,我们为什么要使用池呢?我们以数据库连接池举例,来说明一下池的优点和好处。
首先,我们先来看看数据库访问的一般流程:
1.当系统需要访问数据库时,先系统创建数据库连接
2.接着完成数据库操作
3.最后断开数据库连接
这非常好理解,就仿佛把大象放入冰箱需要几步一样。但是,从这个流程中我们可以看出,除了第二步,第一步和第三步都是重复且耗时的无意义工作;而且当系统需要频繁地访问数据库时,就会频繁创建和断开数据库连接,这种行为不但耗时,甚至容易对数据库造成安全隐患。因此,我们使用“池”来解决这一问题。在程序初始化时,我们就立刻创建多个数据连接,把它们集中管理。当程序需要使用时,就从“池”中取出使用,用完再放回池中,这样就避免了频繁的数据库连接和断开操作,而且更加地安全可靠。
通过上面地介绍,我们发现,其实池是一个装着资源地容器。如果池里装的是进程就是进程池,如果是线程就是线程池,而如果是数据库连接,那就是数据库连接池。具体实现池的方法有许多,比如:数组,链表,队列等。
1.static connection_pool* Getinstance()是单例模式,是用来获取数据库连接池的,也就是我们最终从这一个池中获取数据库连接
2.init和上述几个类一样,是初始化操作
3.MYSQL *Getconnection()用来获取数据库连接
4.bool ReleaseConnection(MYSQL *con)释放数据库连接
5.int GetFreeConn()获取空余连接数量
6.void DestroyPool()销毁所有连接,也就是摧毁池
其实在这一部分文件中,我们还涉及到了一个很重要的思想,就是RAII类
RAII(Resource Acquisition Is Initialization)(资源获取即初始化)是一种C++编程中的重要设计原则,用于管理资源的获取和释放。RAII的核心思想是通过对象的生命周期来控制资源的生命周期,从而确保资源在合适的时候被正确地获取和释放。我们的智能指针如unique_ptr,锁lock_gurad和文件流都采用了RAII的机制。
根据上述思想,我们单独再创建一个RAII类,这个类的唯一作用就是与数据库连接池的资源进行绑定;可以看到这个类中只有构造函数和析构函数。
这样当类创建实例时就会调用构造函数,构造函数内就会调用数据库连接函数;当类的生命周期结束时就会调用析构函数,析构函数会调用销毁数据库函数;从而实现了资源的获取与释放与类的实例的生命周期绑定。
第四层:定时器功能
我们的系统资源是有限的,当一个客户长时间不响应的时候,我们就要关闭这个连接,把资源分配给正在使用的客户,以此来提高服务器的运行效率,我们设定定时器的目的就是让它去处理非活动连接。
client_data类是我们用户数据结构体,用来封装我们的连接资源。client_data中包括客户端的socket地址,socket文件描述符以及定时器。
util_timer类就是我们的定时器类,里面包含超时时间,回调函数,连接资源,前向定时器,后向定时器等。
然后我们再设计定时器容器,这里我们选择的是升序的双向链表,当然,我们也有更高级的定时器容器比如时间轮或者时间堆,上升链表类就是用来监督是否超时的。
其中最主要的是tick()函数,也称为心搏函数,就是后期的主循环中,没经过一段时间,就调用一次tick,tick函数就会完成一定的功能,很显然它的功能就是将过期的定时器从链表中删除。
void sort_timer_lst::tick() {
if (!head) {
return;
}
/*获取时间*/
time_t cur = time(NULL);
util_timer *tmp = head;
/*遍历定时器链表*/
while (tmp) {
/*因定时器链表为升序,则如果当前时间小于定时器超时时间,则后面所有定时器都未到期*/
if (cur < tmp->expire) {
break;
}
/*如果当前时间超过定时器时间,调用回调函数*/
tmp->cb_func(tmp->user_data);
/*设置新的头节点*/
head = tmp->next;
if (head) {
head->prev = NULL;
}
delete tmp;
tmp = head;
}
}
这在个文件中,又涉及到了一种思想吗,就是Utils(使用程序)或称抽象工具类
我们定时器的设计基本完成了,接下来我们要来设计一些方法来合理的使用它。
首先我们需要思考一个问题是:我们以前写的传统的代码运行逻辑,是从上到下一行一行按顺序运行的,我们不可能提前预判一些不稳定出现的事件然后用代码处理它,我们只能是等不稳定的事件出现后,让他通过某种方式通知我,然后我在通过一些预案(即处理这些事件的代码)来处理该事件。那么这里的某种方式是什么呢?
我们通常使用信号,这里的逻辑是,我们每过一段时间就给主循环一个信号,主循环收到信号就记录下来,等其他IO事件完成之后,就调用tick()处理非活动连接。所以接下来我们的需求是如何设置信号,如何发送信号,以及了解一下主循环如何接收信号。
class Utils{
public:
Utils(){}
~Utils(){}
void init(int timeslot);
/*对文件描述符设置非阻塞*/
int setnonblocking(int fd);
/*将内核事件表注册读事件,ET模式,选择开启EPOLLONESHOT*/
void addfd(int epollfd, int fd, bool one_shot, int TRIGMode);
/*信号处理函数*/
static void sig_handler(int sig);
/*设置信号处理函数 这里第二个参数void(handler)(int)等价于void(*handler)(int),再作函数参数时,后者的*可以省略*/
void addsig(int sig, void(handler)(int), bool restart = true);
/*定时处理任务, 重新定时以不触发SIGALRM信号*/
void timer_handler();
void show_error(int connfd, const char *info);
public:
static int *u_pipefd;
sort_timer_lst m_timer_lst;
static int u_epollfd;
int m_TIMESLOT;
};
第五层:线程池的设计
线程池这里的设计思想不算难,大家通过看代码就可以理解,在这个类中,需要设计两个模块,一个是用来存放线程的数组,一个是用来存放请求的链表,其他的一些成员变量都是用来辅助创建数组和链表的,当然必须要有的还有互斥锁和信号量,剩下的就是一些操作了。
第六层:http连接处理
在这个项目中,http很重要,我也见识到了这一部分的内容是相当地长,在http_conn这个类中,大概有以下这些内容:接受连接,处理连接(设计两个状态机,即主状态机/从状态机来进行报文解析),响应连接,最后封装了一个运行函数(process),接下来我们对这些部分一一讲解
http_conn类中,首先映入眼帘的必须是public中的3个静态数据成员,分别是
//设置读取文件的名称m_read_file大小
static const int FILENAME_LEN = 200;
//设置读缓冲区 m_read_buf大小
static const int READ_BUFFER_SIZE = 2048;
//设置写缓冲m_write_buf大小
static const int WRITE_BUFFER_SIZE = 1024;
接下来是报文的请求方法
//报文的请求方法,本项目只用到GET和Post
enum METHOD{
GET = 0,
POST,
HEAD,
PUT,
DELETE,
TRACE,
OPTIONS,
CONNECT,
PATH
};
涉及到了主状态机与从状态机,从状态机用于获取报文,主状态机用于解析报文
//主状态机的状态
enum CHECK_STATE{
CHECK_STATE_REQUESTLINE = 0,
CHECK_STATE_HEADER,
CHECK_STATE_CONTENT
};
//报文解析结果
enum HTTP_CODE{
NO_REQUEST,
GET_REQUEST,
BAD_REQUEST,
NO_RESOURCE,
FORBIDDEN_REQUEST,
FILE_REQUEST,
INTERNAL_ERROR,
CLOSED_CONNECTIONS
};
//从状态机状态
enum LINE_STATUS{
LINE_OK = 0,
LINE_BAD,
LINE_OPEN
};
接下来看函数的名字就可以知道它是实现什么功能的
//初始化套接字地址,函数内部调用私有方法init
void init(int sockfd, const sockaddr_in &addr, char *, int, int, string user, string passwd, string sqlname);
//关闭http连接
void close_conn(bool real_close = true);
//最终封装的一个process函数,用于实现读写数据
void process();
//读浏览器端发来的全部数据
bool read_once();
//响应报文写入函数
bool write();
sockaddr_in *get_address(){
return &m_address;
}
//同步线程初始化数据库读取表
void initmysql_reslut(connection_pool *connPool);
int timer_flag;//用于标记定时器是否超时
int improv;//用于标记是否检查定时器
//从m_read_buf读取,并处理请求报文
HTTP_CODE process_read();
//向m_write_buf写入响应报文
bool process_write(HTTP_CODE ret);
//主状态机解析请求报文中的请求行数据
HTTP_CODE parse_request_line(char *text);
//主状态机解析请求报文中的请求头数据
HTTP_CODE parse_headers(char *text);
//主状态机解析报文中的请求内容
HTTP_CODE parse_content(char *text);
//生成响应报文
HTTP_CODE do_request();
//m_start_line是已解析的字符
//get_line用于将指针往后偏移,指向未处理的字符
char *get_line(){
return m_read_buf + m_start_line;
}
//从状态机读取一行,分析是请求报文的哪一部分
LINE_STATUS parse_line();
void unmap();
//根据响应报文格式,生成对应的8个部分,以下函数均由do_request调用
bool add_response(const char *format, ...);
bool add_content(const char *content);
bool add_status_line(int status, const char *title);
bool add_headers(int content_length);
bool add_content_type();
bool add_content_length(int content_length);
bool add_linger();
bool add_blank_line();
最后一个,我们仔细看一下process函数
实现的功能是,从状态机从浏览器读取数据,从状态机将读到的数据写给主状态机
最终层:WebServer类
最顶层的一个server封装类,将我们至今为止写的所有代码,封装到一个类里,去实现它们的使命。定义为public的函数,这些函数都是要给外部调用的,而private部分的函数内容都是封装给EventLoop单独使用的。
总结
本篇文章的目的就是帮读者大概梳理一下整个项目的框架,让读者可以明白具体如何实现,从而可以把握整个项目的实现流程,最后自己去细看代码,也可以自己尝试一部分一部分去实现!
版权归原作者 大街上随处可见 所有, 如有侵权,请联系我们删除。