
尽管是数据科学中为数不多的基本概念之一,但中心极限定理 (CLT) 仍然被误解。
围绕这些基本统计概念的问题确实会在数据科学面试中出现。但是一些追求趋势的数据科学家经常将他们的学习时间投入到最新趋势和新算法上,但却因为没有重新审视基本概念而在面试中挂掉了。
这篇文章将帮助您更直观地理解 CLT 定理。它还将帮助您更好地理解它的重要性以及使用时的关键假设。
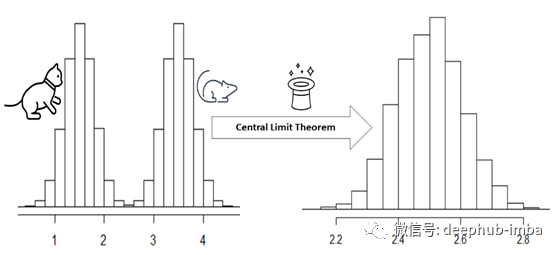
简单解释
中心极限定理指出,只要样本量足够大,任何分布的均值的抽样分布将是正态的。
让我们用一个更具体的例子将上面的定义与更简单的词分开。
假设有一个200万家庭的国家,分为两个关键地区:Tom 和 Jerry。为了简单起见,让我们假设有100万家庭生活在Tom地区,100万家庭生活在Jerry地区。。
一家受欢迎的快餐连锁店招募您来帮助他们决定是否应该在该国投资并开设分店。如果他们这样做了,他们应该在 Tom 还是 Jerry 地区开设它。
假设评估每个地区人们现有饮食习惯的一个有用指标是每个家庭每周光顾快餐店的次数。你的任务是为Tom 、Jerry和整个国家解决这些问题。
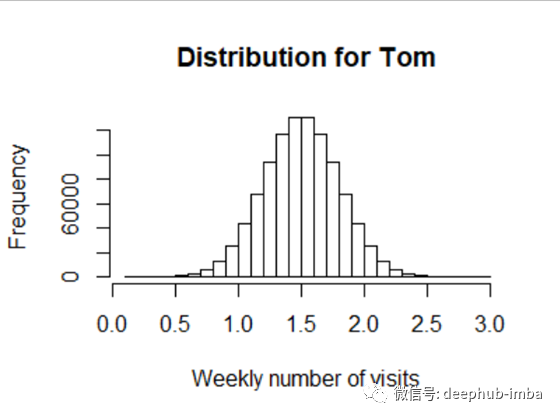
在我们假设的国家/地区,Tom 每周访问的平均次数为 1.5,其分布如图 1 所示。
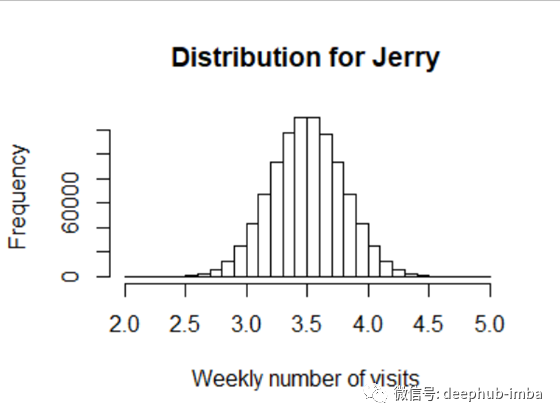
Jerry每周平均访问次数为3.5次,分布如图2所示。
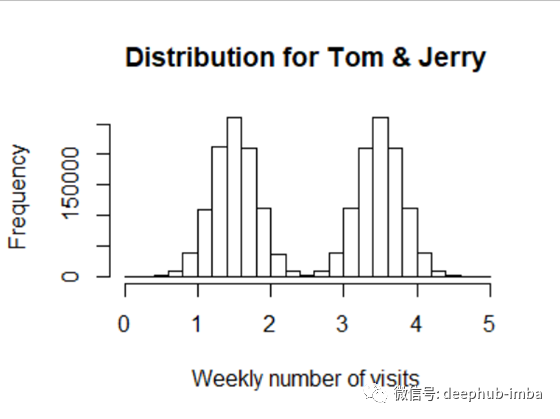
总体而言,每周平均访问次数的分布见图3,平均值为2.5
理论上,我们可以探访这个国家每个人的饮食习惯,然后计算出平均每周到访率。然而,这在现实世界的项目中是不可行的。
我们所做的是从总体中“抽样”。所谓“样本”,我们的意思是我们可以从总体中只询问一小部分人(通常是出于良好的理由随机选择的)。
假设我们从Tom区域随机抽取100个家庭,然后计算均值。
如果我们重复同样的实验,我们会得到不同的平均值。如果我们重复同样的实验100次,我们将得到100个不同的(样本)平均值。
然后绘制这些样本均值的分布,它将看起来像一个正态分布。该样本分布的均值将非常接近真实的总体均值。
图4显示了Tom区域10,000个平均值的分布(在R中模拟)。每个平均值都是通过随机抽取100个家庭进行抽样计算得出的。
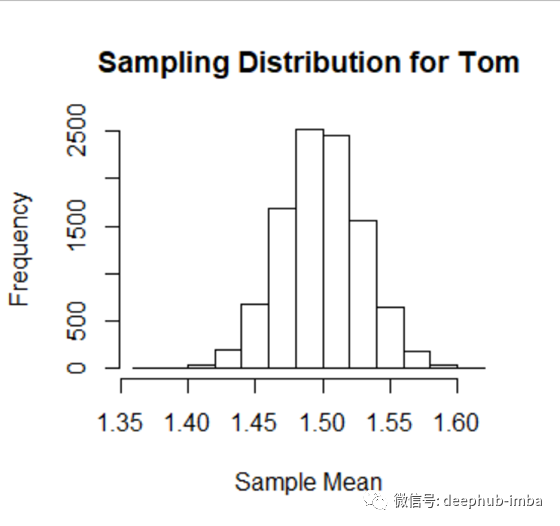
图 5 显示了Jerry地区 10,000 个平均值的分布。同样,每个平均值都是通过对 100 个随机选择的家庭进行抽样计算得出的。
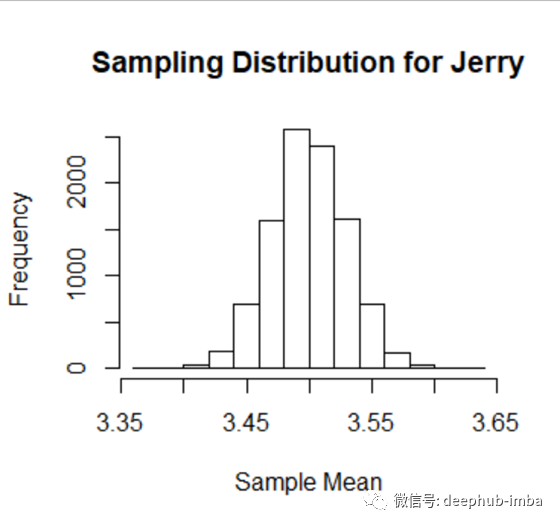
图 4 和图 5 中的分布都是正态分布。在这一点上,您可能认为这些样本分布是正态的,因为总体分布(从中得出这些分布)是正态的。
然而,初学者可能会感到惊讶。
人口(原始)分布是什么并不重要。如果我们抽样,并且样本足够大,样本均值的最终分布将是正态分布的。此外,该抽样分布的均值将近似等于总体均值。
你刚刚在上面读到的是简单的 CLT 定理。
让我们使用前面的示例演示 CLT。让我们从由 Tom 和 Jerry 地区组成的整个国家中随机选择 100 个家庭并计算平均值,并重复相同的实验 100,000 次。图 6 显示了这 10,000 个平均值的分布。
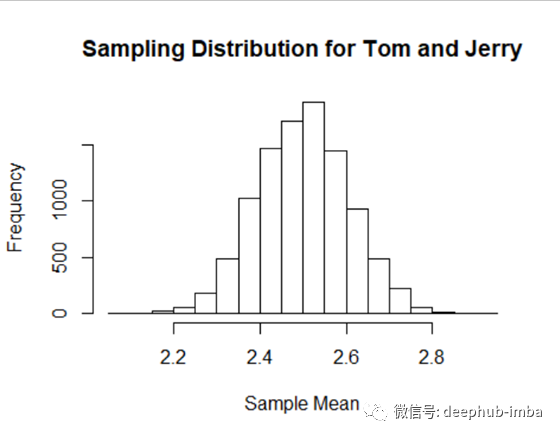
显然,该国人口分布不正常。即便如此,抽样分布也是正态分布,均值非常接近总体均值。
这就是 CLT 的魅力所在。我们不需要知道随机变量的潜在分布是什么。我们仍然可以通过抽样找出总体的均值,并正确假设抽样分布将近似正态分布。
什么使 CLT 有用?
在大多数有用的现实项目中,由于时间和资源的限制,我们无法出去从整个人群中收集数据。然而,CLT 使我们能够自信地走出去,从人口的一个子集收集数据,然后使用统计数据得出关于人口的结论。
CLT 是假设检验的基础,这是推理统计的一个分支,可帮助我们仅从具有代表性的数据子集中得出关于总体的结论。
最后的想法
在假设示例中,Tom 和 Jerry 的人口分布是正态的,而整个国家的分布是非正态的(有两个峰值)。然而,在所有三种情况下,抽样分布都是正态的。这是中心极限定理的结果。不管总体分布如何,只要样本足够大,均值的抽样分布是正态分布的。在大多数实际应用中,通常认为大于 30 的样本量就足够了。
CLT 定理仅在要建模的分布的均值和方差是有限的情况下才有效。因此,该定理不适用于柯西分布的情况。如果您想进一步研究,请查看此模拟演练的两个示例,一个适用于 CLT,另一个不适用。
这篇文章中的所有数字都是用 R 生成的。带有注释的代码可以在我的 GitHub 上找到。https://github.com/syedahmar/UnderstandCentralLimitTheorem
作者:Ahmar Shah, PhD